https://blog.csdn.net/u012102306/article/details/51322209#commentBox
https://blog.csdn.net/winner941112/article/details/82899277
1. 避免使用触发shuffle的算子,例如reduceByKey、join、distinct、repartition
a. 使用broadcast与map代替join算子
https://blog.csdn.net/winner941112/article/details/82899850
2. 使用persist持久化RDD
https://blog.csdn.net/winner941112/article/details/82899483

知识点:persist和cache的关系
cache算子等同于执行了persist算子且持久化级别为MEMORY_ONLY
知识点:cache()和persist()的使用规则为,必须在transformation或者textFile等创建一个rdd之后,直接连续调用cache()和persist()才可以
3. 使用预聚合的shuffle操作
a. 使用reduceByKey或者aggregateByKey算子来替代groupByKey算子,执行时,对每个节点本地的相同key进行预聚合;而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差
4. 使用高性能算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map
使用foreachPartitions替代foreach(将RDD中数据写入mysql)
使用filter之后进行coalesce操作,手动减少RDD的partition数量
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
5. 广播大变量
如果使用的外部变量比较大,建议使用Spark的广播功能,广播后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的task执行时共享该Executor中的那份变量副本,这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低GC的频率
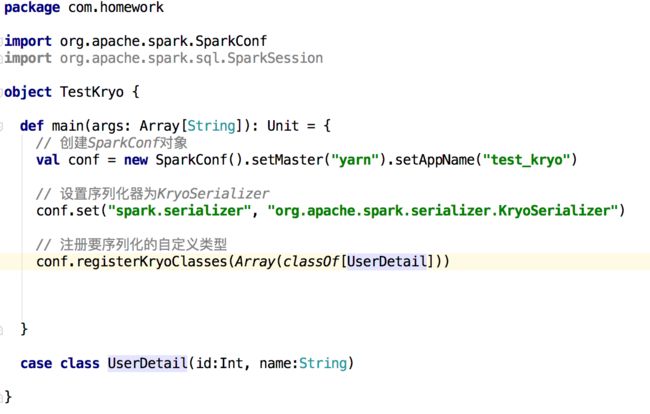
6. 使用Kryo优化序列化性能
spark中,主要有三个地方涉及到了序列化
在算子函数中使用到外部变量
将自定义的类型作为RDD的泛型类型时,所以自定义类型对象,都会进行序列化,因此这种情况下,也要求自定义的类必须实现Serializable接口
使用可序列化的持久化策略时,Spark会将RDD中的每个partition都序列化成一个大的字节数组
对于这三种出现序列化的地方,我们都可以通过使用kryo序列化类库,来优化序列化和反序列化的性能
Spark默认使用java序列化机制
Kryo要求最好要注册所有需要进行序列化的自定义类型
步骤:设置序列化类,再注册要序列化的自定义类型(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等)
7. 优化数据结构
Java中,有三种类型比较耗费内存:对象、字符串、集合类型
Spark建议,在Spark编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型替代字符串,使用数组替代集合类型,这样尽可能减少内存占用,从而降低GC频率,提升性能。但是要保证代码的可维护性
8. 资源参数调优
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
## 设置每个stage的默认task数量
--conf spark.default.parallelism=1000 \
## 设置RDD持久化数据在Executor内存中能占的比例,默认为0.6
--conf spark.storage.memoryFraction=0.5 \
## 设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2
--conf spark.shuffle.memoryFraction=0.3 \
9. 数据倾斜优化
https://blog.csdn.net/u012102306/article/details/51556450
10. spark-submit参数优化
https://my.oschina.net/rosetta/blog/777771
--conf spark.yarn-executor.memoryOverhead=2048
--conf spark.core.connection.ack.wait.timeout=300(默认60s)
11. 数据倾斜只会发生在shuffle过程中,常用并且可能触发shuffle操作的算子有:distinct groupByKey reduceByKey aggregateByKey join cogroup repartition
12. spark-submit通过—conf传参时,key必须以spark.开头,然后通过
spark.sparkContext.getConf.get(“spark….”, “-9999”)
13.