07Python爬虫---Cookie实战
一、什么是Cookie
我们在浏览器中,经常涉及到数据的交换,比如你登录邮箱,登录一个页面。我们经常会在此时设置30天内记住我,或者自动登录选项。那么它们是怎么记录信息的呢,答案就是今天的主角cookie了,Cookie是由HTTP服务器设置的,保存在浏览器中,但HTTP协议是一种无状态协议,在数据交换完毕后,服务器端和客户端的链接就会关闭,每次交换数据都需要建立新的链接。就像我们去超市买东西,没有积分卡的情况下,我们买完东西之后,超市没有我们的任何消费信息,但我们办了积分卡之后,超市就有了我们的消费信息。cookie就像是积分卡,可以保存积分,商品就是我们的信息,超市的系统就像服务器后台,http协议就是交易的过程。
二、爬虫Cookie实战
此次实战登录ChinaUnix论坛
(1)无cookie处理登录
步骤:
(1)使用urllib.request.Resquest创建对象
(2)add_header添加头部信息
(3)urllib.request.urlopen进行登录并读取
(4)将爬取的网页保存到本地
(5)登录后再爬取该网页下的其他网页进行爬取
import urllib.request
import urllib.parse
url = "http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LfgTz"
postdata = urllib.parse.urlencode({
"username": "weisuen",
"password": "aA123456"
}).encode('utf-8') # 使用urlencode编码处理后,再设置为utf-8编码
req = urllib.request.Request(url, postdata) # 构建Resquest对象
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36")
data = urllib.request.urlopen(req).read() #登录并爬取对应的网页
fhandle = open("/home/zyb/crawler/myweb/part5/chinaUnixLogin.html", "wb")
fhandle.write(data)
fhandle.close()
url2 = "http://bbs.chinaunix.net/" # 设置要爬取的该网站下其他网页地址
req2 = urllib.request.Request(url2, postdata)
req2.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36")
data2 = urllib.request.urlopen(req2).read() # 爬取该站下的其他网页
fhandle2 = open("/home/zyb/crawler/myweb/part5/chinaUnixBBS.html", "wb")
fhandle2.write(data2)
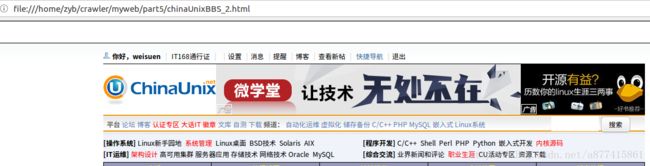
fhandle2.close()网页效果展示
问题:登陆后,打开本地第二个网页还是未登录状态
问题由来:因为我们没有设置Cookie,而HTTP协议是一个无状态的协议,访问新的网页,自然会话信息会消失
(2)问题解决
解决方案
(1)导入Cookie处理模块http.cookiejar
(2)使用http.cookiejar.CookieJar()创建CookieJar对象
(3)使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象。
(4)创建全局默认的opener对象
import urllib.request
import urllib.parse
import http.cookiejar
url = "http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LfgTz"
postdata = urllib.parse.urlencode({ # 此处登录可用自己在网站上注册的用户名和密码
"username": "weisuen",
"password": "aA123456"
}).encode("utf-8")
req = urllib.request.Request(url, postdata)
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36")
# 使用http.cookiejar.CookieJar()创建CookieJar对象
cjar = http.cookiejar.CookieJar()
# 使用HTTPCookieProcessor创建cookie处理器,并以其参数构建opener对象
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
# 将opener安装为全局
urllib.request.install_opener(opener)
file = opener.open(req)
data = file.read()
file = open("/home/zyb/crawler/myweb/part5/chinaUnixLogin_2.html", "wb")
file.write(data)
file.close()
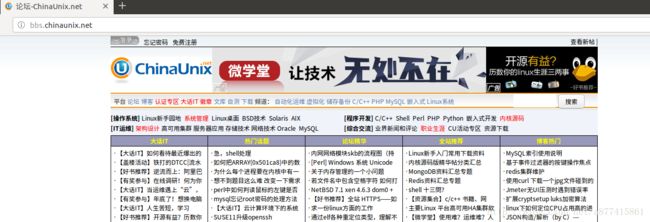
url2 = "http://bbs.chinaunix.net/" # 设置要爬取的该网站下其他网页地址
data2 = urllib.request.urlopen(url2).read()
fhandle = open("/home/zyb/crawler/myweb/part5/chinaUnixBBS_2.html", "wb")
fhandle.write(data2)
fhandle.close()