一、概述
在java中,不能对对象的内容进行直接操作,。在java中字符串用.equals()方法和CompareTo()方法一样,
对象可以用“==”和equal()方法,比较是否是同一对象(内存地址),如果类中重写了hashCode()方法和equals()方法,用equals()方法比较的是对象的属性值。否则equals()比较的是对象是否是同一个(和“==”一样)。字符串String类已经重写了hashCode()方法和equals()方法,可以用“==”和“equals()”方法进行比较。并且结果两者的结果相同(根据字符串内存性质决定(字符串存储在字符常量池中除new出来的))。
首先要了解在java中常量池:专门存储常量的地方,都指的是方法区(在jdk1.8以前各个版本虽然都有所差别,即方法区也叫做永久区是堆空间的一部分但是在jdk1.8中将方法区从堆中分离出来在物理内存当中)中。
-
编译常量池:把字节码加载进JVM的时候,存储的是字节码相关的信息。
-
运行常量池:存储常量数据。
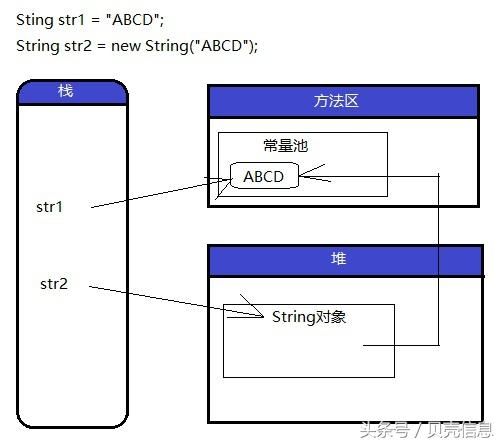
内存图
那么我们得到结论:
-
第1行代码:最多创建一个String对象,最少不创建String对象;如果常量池中,已经存在“ABCD”,那么str1直接引用,此时不创建String对象,否则,先在常量池先创建“ABCD”内存空间,再引用。
-
第2行代码:最多创建两个String对象,至少创建一个String对象,new关键字,绝对会在堆空间创建内存区域,所以至少创建一个String对象。
在这里只探讨在python环境下的一些性质。
在python中内存空间基本相同,但是储存的东西不一样一些值不可变的数据类型都可以。
二、python字符串和对象的加载机制
java:半编译(跨平台),半解释,ssh框架,ssm框架
任何语句必须依赖外部定义。比如:变量依赖类:成员或者方法:局部
流程控制依赖于块或者方法
参数的个数不确定时,参数列表可以用(数据类型...args),增强for循环遍历,注意参数的数据类型必须一致
python:语法简洁,编写效率高,但是执行(底层运行)效率高,解释语言执行效率低于编译语言。任何语句都可以单独存在。
实际在jdk1.8之前,堆中分隔了一部分称之为永久区或者方法区,里面有一个字符串常量池,声明并赋予一个字符串值
会先在常量池里面找是否以前有该内容的内存,如果有,将该内存地址赋予给常量。python不可变值的数据类型的内存结构和声明和赋值变量的过程与上述描述一样,下面是实例。
| a='Hello world!' b='Hello world!' c='Hello word!' #id()函数表示该变量的id用它可以代替表示变量的内存地址 print 'a=%s a_id=%d b=%s b_id=%d c=%s c_id=%d' %(a,id(a),b,id(b),c,id(c)) print 'a==b %s b==c %s' %(a==b,b==c) #cmp(x,y)比较两个参数的大小,返回结果为(x-y)数字(整数int),在python3系列中已经不存在该函数。 #可以重新定义方法来实现该功能 print 'cmp(a,b)计算结果%d cmp(b,c)计算结果%d'%(cmp(a,b),cmp(b,c)) |
结果如下:
| a=Hello world! a_id=37565008 b=Hello world! b_id=37565008 c=Hello word! c_id=37597888 a==b True b==c False cmp(a,b)计算结果0 cmp(b,c)计算结果1 |
接下来比较对象创建是否和java中一样在堆的回收区中创建,这里就不再一一解释了,从下面的代码就可以看出。
下面代码用的是python2.7定义一个类
| class Person: p1=Person('zhangsan',30,'男','1234567345') |
结果如下:
| 不重写__repr__()方法直接对对象的输出和对象的id p1<__main__.Person instance at 0x0261E418> p1_id39969816 p2<__main__.Person instance at 0x0261E440> p2_id39969856 p3<__main__.Person instance at 0x0261E468> p3_id39969896 p4<__main__.Person instance at 0x0261E490> p4_id39969936 p5<__main__.Person instance at 0x0261E490> p5_id39969936 p5==p4的结果是True,p4==p1的结果是False cmp(p5,p4)的结果0,cmp(p4,p1)的结果是1 |
| 重写__repr__()方法直接对对象的输出和对象的id p1zhangsan 30男 1234567345 p1_id39879824 p2lisi 34男 1578923401 p2_id39879864 p3wangyi 14女 1789234123 p3_id39879904 p4zhangsan 30男 1234567345 p4_id39879944 p5zhangsan 30男 1234567345 p5_id39879944 p5==p4的结果是True,p4==p1的结果是False cmp(p5,p4)的结果0,cmp(p4,p1)的结果是1 |
如果直接用 print 'p5-p4结果是%s p4-p1的结果是%s' %(p5-p4,p4-p1)
结果为:TypeError: unsupported operand type(s) for -: 'instance' and 'instance'
三、lambda
在JDK1.8中,出现了函数式接口,可以写成lambda表达式,但和python中有很大的区别,在python里面lambda里面只能是一个表达式,而在java中可以是整个方法体,标志不一样,在java中的代码现在暂时先不会提供。
在这里会用python2.7版本进行演示:
如果直接输出一个lambda表达式会print lambda a:a**2
返回一个如下的结果:
| a=[] print '没有排序的结果' #这里可以用“-”负号反转,使其顺序发生变更
|
结果如下:
| 没有排序的结果 zhangsan 30男 1234567345 lisi 34男 1578923401 wangyi 14女 1789234123 zhaotian 21男 1734234123 zhangsan 12女 1567567345 按照名字升序排列 lisi 34男 1578923401 wangyi 14女 1789234123 zhangsan 30男 1234567345 zhangsan 12女 1567567345 zhaotian 21男 1734234123 按照电话号码的后三位按照降序排列 lisi 34男 1578923401 zhangsan 30男 1234567345 zhangsan 12女 1567567345 wangyi 14女 1789234123 zhaotian 21男 1734234123 名字相同按照年龄升序排列,名字不同按照名字降序排列 zhaotian 21男 1734234123 zhangsan 12女 1567567345 zhangsan 30男 1234567345 wangyi 14女 1789234123 lisi 34男 1578923401 名字相同按照年龄升序排列,名字不同按照名字降序排列,用cmp方法 lisi 34男 1578923401 wangyi 14女 1789234123 zhangsan 12女 1567567345 zhangsan 30男 1234567345 zhaotian 21男 1734234123 |
| >>> g=lambda x:x**2 >>> h=lambda x,y:x+y >>> g(1) 1 >>> g(7) 49 >>> h(2,4) 6 |