scrapy野蛮式爬取(将军CrawlSpider,军师rules)
如果将Spider比作scrapy爬虫王国的一个元帅,那CrawlSpider绝对是元帅手底下骁勇善战的将军。而其rules,便是善于抽丝剥茧的军师。
以下便记录以下一个CrwalSpider的作战过程。
1、 首先创建scrapy项目
python -m scrapy startproject 项目名称
2、 创建CrawlSpider
python -m scrapy genspider -t crawl 蜘蛛名 域名
python -m 详细内容可见 https://zhuanlan.zhihu.com/p/91120727
此时我们便已经创建好了基础的CrawlSpider
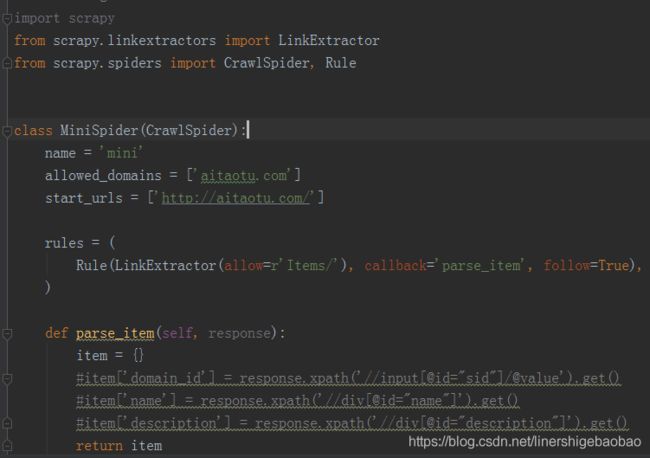
其中项目中的域名与起始url我们都可以自己手动修改。我们可以将不同的url入口放在start_urls中列表中,从而从不同起点开始爬取整个网站。爬虫开始后首先从start_urls列表中提取开始请求的url,然后其解析的response交给rules,rules通过LinkExtractor中的各种筛选url的方式,挑选出我们想要请求的url,,自动请求后将response通过callback返回给相应的回调函数。从而解析出我们想要的内容。
3、Rule里边参数解析
1、 LinkExtractor
LinkExtractor筛选方式:
其具体参数有:(可查看scrapy官方文档,搜索关键词:LinkExtractor)

主要用到:
1、 allow 定义从start_url请求来的response中哪些链接使我们要的。其为一个正则表达式或者正则表达式列表形式写出。
如: allow=r'http.*?.html' ,可以描述为允许提取http.............html类似的链接。
2、restrict_xpaths('') 直接放入表达式即可
3、restrict_css('') 如:![]() 可表述为:只要id为mainbody里的ul里的li里的a里边的链接。
可表述为:只要id为mainbody里的ul里的li里的a里边的链接。
其余方法看需要使用。LinkExtractor中可以使用多个筛选方式,用 “,”隔开即可

2、 callback
callback 将把LinkExtractor解析出来的链接请求之后的response回调给一个函数。函数接收该response后即可直接解析内连接内容。
注意:callback不可回调给parse。此处 parse已被默认去做了其它事情。如果重新定义一个parse来接受response,爬虫将可能无法工作。
3、cb_kwargs
它是一个字典格式的数据,里边包含了要传给回调函数的参数,
4、process_links
根据LinkExtractor中的条件过滤链接。
5、 process_request
去请求url
本人刚学习scrapy,所以了解不是很深。我现在的理解是process_links是用来根据LinkExtractor筛选出链接,然后process_request去请求这些筛选后的链接,最后得到的response通过callback回调给相应函数,从而进行下一步对数据的处理。(如果理解不对,请大家指正。谢谢!)
通过定义一个Rule我们便可以实现当前页面的所有详情页的请求,如果再定义一个Rule去把其他页面的url提取出来便可以实现网页垂直与横向爬取。从而一步步爬完整个网站。
另外发现rules的强大之处,其不需要我们再去构造完整的url。它可以结合我们的域名再结合提取的网页的相对地址,自动构造出完整的url。从而去实现更为方便的爬取。这也是算是比较惊喜的一个地方。
最后总结一下,CrawlSpider,通过start_urls制定爬取起点,通过rules制定两个(或多个)Rules规则,通过callback回调,便可以实现网页的深度、广度爬取。同时能够使我们对想要爬取的部分作出更为清晰的定义,其自动构造url的绝对路径能够极大的简化传统spider中url构造部分。
PS:小胖胖的猪崽