推荐算法—ctr预估
文章目录
- 总览
- 传统CTR模型演化的关系图
- 深度学习CTR模型的演化图谱
- 算法比对与总结
- LR
- FM
- LR+GBDT
- FTRL——在线实时训练模型
- LS-PLM(MLR)
- FNN
- PNN
- Google Wide&Deep
- 华为 DeepFM
- Google Deep&Cross
- NFM
- AFM
- 阿里DIN
- 阿里DIEN
- xDeepFM
- 参考
总览
传统CTR模型演化的关系图

- 向下为了解决特征交叉的问题,演化出PLOY2,FM,FFM等模型;
- 向右为了使用模型化、自动化的手段解决之前特征工程的难题,Facebook将LR与GBDT进行结合,提出了GBDT+LR组合模型;
- 向左Google从online learning的角度解决模型时效性的问题,提出了FTRL;
- 向上阿里基于样本分组的思路增加模型的非线性,提出了LS-PLM(MLR)模型
深度学习CTR模型的演化图谱
算法比对与总结
各种CTR深度模型看似结构各异,其实大多数可以用如下的通用范式来表达,
-
input->embedding:
把大规模的稀疏特征ID用embedding操作映射为低维稠密的embedding向量 -
embedding层向量
concat, sum, average pooling等操作,大部分CTR模型在该层做改造 -
embedding->output:
通用的DNN全连接框架,输入规模从n维降为k*f维度甚至更低。
其中,embedding vector这层的融合是深度学习模型改造最多的地方,该层是进入深度学习模型的输入层,embedding 融合的质量将影响DNN模型学习的好坏。个人总结大体有以下4种操作,当然后续可能会有越来越多其他的变形结构
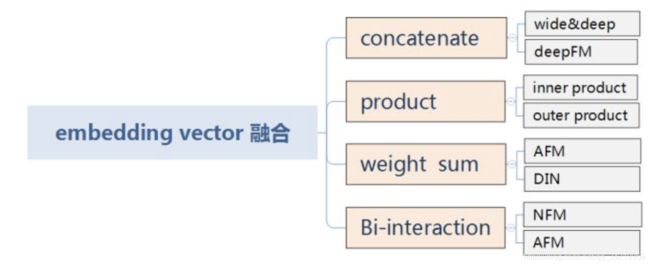
LR
使用各特征的加权和是为了综合不同特征对CTR的影响,而由于不同特征的重要程度不一样,所以为不同特征指定不同的权重来代表不同特征的重要程度。最后要套上sigmoid函数,正是希望其值能够映射到0-1之间,使其符合CTR的物理意义
FM
FM 模型可以看成是线性部分的 LR,还有非线性的特征组合 xixj 交叉而成,表示如下:

可以化简,减小复杂度
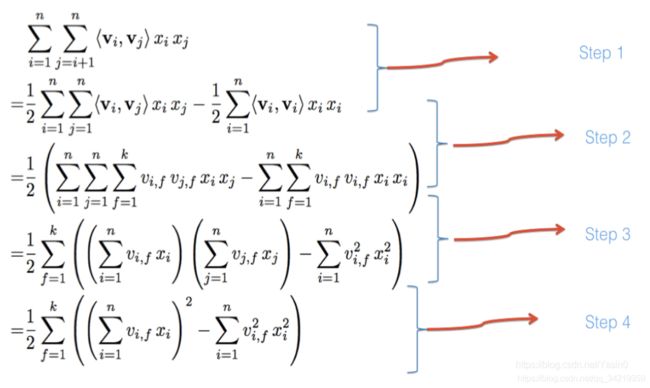
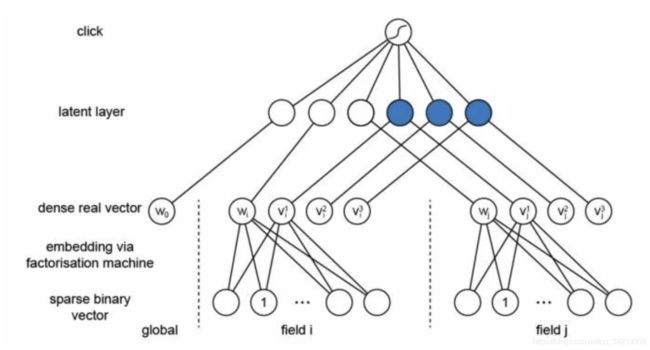
从神经网络的角度表示 FM, 可以看成底层为特征维度为 n 的离散输入,经过 embedding 层后,对 embedding 层线性部分(LR)和非线性部分(特征交叉部分)累加后输出
FM 等价于 FM + embedding,待学习的参数如下:
- LR 部分:1+n
- embedding 部分:n*k
LR+GBDT
FFM只能够做二阶的特征交叉,如果要继续提高特征交叉的维度,不可避免的会发生组合爆炸和计算复杂度过高的情况。需要有效的处理高维特征组合和筛选,2014年,Facebook提出了基于GBDT+LR组合模型的解决方案
Facebook提出了一种利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型输入,预估CTR的模型结构。

用GBDT构建特征工程,和利用LR预估CTR两步是独立训练的。
GBDT是由多棵回归树组成的树林,后一棵树利用前面树林的结果与真实结果的残差做为拟合目标。每棵树生成的过程是一棵标准的回归树生成过程,因此每个节点的分裂是一个自然的特征选择的过程,而多层节点的结构自然进行了有效的特征组合
一个训练样本在输入GBDT的某一子树后,会根据每个节点的规则最终落入某一叶子节点,那么我们把该叶子节点置为1,其他叶子节点置为0,所有叶子节点组成的向量即形成了该棵树的特征向量,把GBDT所有子树的特征向量连接起来,即形成了后续LR输入的特征向量。

GBDT容易产生过拟合,以及GBDT这种特征转换方式实际上丢失了大量特征的数值信息,因此我们不能简单说GBDT由于特征交叉的能力更强,效果就比FFM好,在模型的选择和调试上,永远都是多种因素综合作用的结果。
FTRL——在线实时训练模型
FTRL的全称是Follow-the-regularized-Leader,与模型演化图中的其他模型不同,FTRL本质上是模型的训练方法。虽然Google的工程化方案是针对LR模型的,但理论上FTRL可以应用在FM,NN等任何通过梯度下降训练的模型上。
从训练样本的规模角度来说,梯度下降可以分为:batch,mini-batch,SGD(随机梯度下降)三种,batch方法每次都使用全量训练样本计算本次迭代的梯度方向,mini-batch使用一小部分样本进行迭代,而SGD每次只利用一个样本计算梯度。对于online learning来说,为了进行实时得将最新产生的样本反馈到模型中,SGD无疑是最合适的训练方式。
- SGD对于互利网广告和推荐的场景来说,有比较大的缺陷,就是难以产生稀疏解
由于one hot等id类特征处理方法导致广告和推荐场景下的样本特征向量极度稀疏,维度极高,动辄达到百万、千万量级。为了不割裂特征选择和模型训练两个步骤,如果能够在保证精度的前提下尽可能多的让模型的参数权重为0,那么我们就可以自动过滤掉这些权重为0的特征,生成一个“轻量级”的模型。“轻量级”的模型不仅会使样本部署的成本大大降低,而且可以极大降低模型inference的计算延迟。这就是模型稀疏性的重要之处。
而SGD由于每次迭代只选取一个样本,梯度下降的方向虽然总体朝向全局最优解,但微观上的运动的过程呈现布朗运动的形式,这就导致SGD会使几乎所有特征的权重非零。即使加入L1正则化项,由于CPU浮点运算的结果很难精确的得到0的结果,也不会完全解决SGD稀疏性差的问题。就是在这样的前提下,FTRL几乎完美地解决了模型精度和模型稀疏性兼顾的训练问题
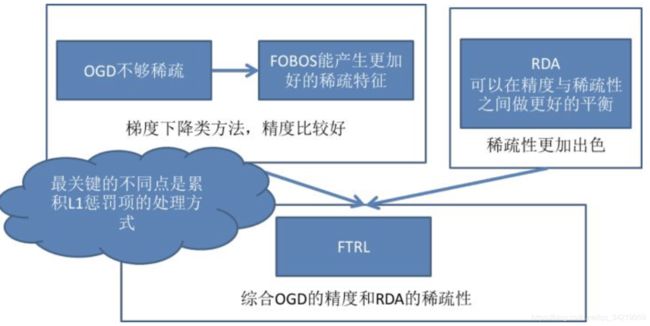
- 从最近简单的SGD到OGD(online gradient descent),OGD通过引入L1正则化简单解决稀疏性问题;
- 从OGD到截断梯度法,通过暴力截断小数值梯度的方法保证模型的稀疏性,但损失了梯度下降的效率和精度;
- FOBOS(Forward-Backward Splitting),google和伯克利对OGD做进一步改进,09年提出了保证精度并兼顾稀疏性的FOBOS方法;
- RDA:微软抛弃了梯度下降这条路,独辟蹊径提出了正则对偶平均来进行online learning的方法,其特点是稀疏性极佳,但损失了部分精度。
- Google综合FOBOS在精度上的优势和RDA在稀疏性上的优势,将二者的形式进行了进一步统一,提出并应用FTRL,使FOBOS和RDA均成为了FTRL在特定条件下的特殊形式。
LS-PLM(MLR)
它的另一个更广为人知的名字是MLR(Mixed Logistic Regression),它在LR的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用LR进行CTR预估。
举例来说,如果CTR模型要预估的是女性受众点击女装广告的CTR,显然我们并不希望把男性用户点击数码类产品的样本数据也考虑进来,因为这样的样本不仅对于女性购买女装这样的广告场景毫无相关性,甚至会在模型训练过程中扰乱相关特征的权重。为了让CTR模型对不同用户群体,不用用户场景更有针对性,其实理想的方法是先对全量样本进行聚类,再对每个分类施以LR模型进行CTR预估。MLR的实现思路就是由该动机产生的。

MLR目标函数的数学形式如上式,首先用聚类函数π对样本进行分类(这里的π采用了softmax函数,对样本进行多分类),再用LR模型计算样本在分片中具体的CTR,然后将二者进行相乘后加和。
当m=1时MLR就退化为普通的LR,m越大模型的拟合能力越强,但是模型参数规模随m线性增长,相应所需的训练样本也随之增长。在实践中,阿里给出了m的经验值为12。
MLR算法适合于工业级的广告、推荐等大规模稀疏数据场景问题。主要是由于表达能力强、稀疏性高等两个优势:
- 端到端的非线性学习:从模型端自动挖掘数据中蕴藏的非线性模式,省去了大量的人工特征设计,这使得MLR算法可以端到端地完成训练,在不同场景中的迁移和应用非常轻松。
- 稀疏性:MLR在建模时引入了L1和L2,1范数,可以使得最终训练出来的模型具有较高的稀疏度,模型的学习和在线预测性能更好。
FNN
用FM的隐向量完成Embedding初始化
DNN 中,网络的原始输入是全部原始特征,维度为 n,通常都是百万级以上。然而特征维度 n 虽然空间巨大,但如果归属到每个特征所属的 field(维度为 f),通常 f 维度会小很多
FNN相比Deep Crossing的创新在于使用FM的隐层向量作为user和item的Embedding,从而避免了完全从随机状态训练Embedding。由于id类特征大量采用one-hot的编码方式,导致其维度极大,向量极稀疏,所以Embedding层与输入层的连接极多,梯度下降的效率很低,这大大增加了模型的训练时间和Embedding的不稳定性,使用pre train的方法完成Embedding层的训练,无疑是降低深度学习模型复杂度和训练不稳定性的有效工程经验。
- FM 部分的 embedding 需要预先进行训练,所以 FNN 不是一个 end-to-end 模型
- FNN 对低阶信息的表达比较有限
- FNN 假设每个 fileld 只有一个值为非零值,如果是稠密原始输入,则 FNN 失去意义。对于一个 fileld 有几个非零值的情况,例如用户标签可能有多个,一般可以做 average/sum/max 等处理
PNN
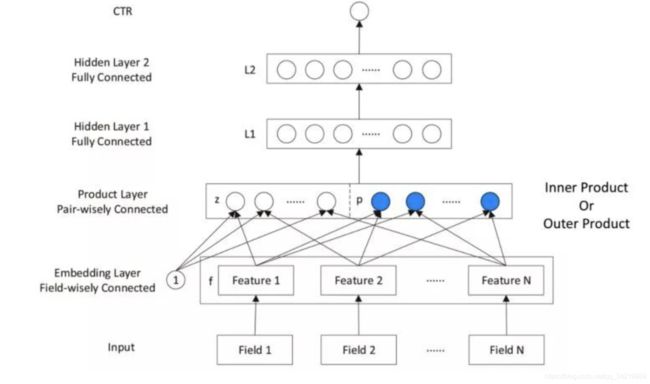
FNN 的 embedding 层直接 concat 连接后输出到 MLP 中去学习高阶特征。
PNN,全称为 Product-based Neural Network,认为在 embedding 输入到 MLP 之后学习的交叉特征表达并不充分,提出了一种 product layer 的思想,既基于乘法的运算来体现体征交叉的 DNN 网络结构
Product Layer 层由两部分组成,左边 z 为 embedding 层的线性部分,右边为 embedding 层的特征交叉部分。
这种 product 思想来源于,在 CTR 预估中,认为特征之间的关系更多是一种 and“且”的关系,而非 add"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。
Google Wide&Deep

Google Wide&Deep模型的主要思路正如其名,把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。其中Wide部分的主要作用是让模型具有记忆性(Memorization),单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接“记住”用户的大量历史信息;Deep部分的主要作用是让模型具有“泛化性”(Generalization),利用DNN表达能力强的特点,挖掘藏在特征后面的数据模式。最终利用LR输出层将Wide部分和Deep部分组合起来,形成统一的模型。Wide&Deep对之后模型的影响在于——大量深度学习模型采用了两部分甚至多部分组合的形式,利用不同网络结构挖掘不同的信息后进行组合,充分利用和结合了不同网络结构的特点。
- LR 部分的特征,仍然需要人工设计才能保证一个不错的效果。因为 LR 部分是直接作为最终预测的一部分,如果作为 Wide 部分的 LR 特征工程做的不够完善,将影响整个 Wide & Deep 的模型精度。
- 模型是 end-to-end 结构,Wide 部分和 Deep 部分是联合训练的。
- Embedding 层 Deep 部分单独占有
- LR: 1+n
embedding 部分:n * k
MLP 部分:f * k * H1 + H1 * H2 + H2 * 1
华为 DeepFM

在Wide&Deep之后,诸多模型延续了双网络组合的结构,DeepFM就是其中之一。DeepFM对Wide&Deep的改进之处在于,它用FM替换掉了原来的Wide部分,加强了浅层网络部分特征组合的能力。事实上,由于FM本身就是由一阶部分和二阶部分组成的,DeepFM相当于同时组合了原Wide部分+二阶特征交叉部分+Deep部分三种结构,无疑进一步增强了模型的表达能力。
- Wide 部分取代 WDL 的 LR,比 FNN 和 PNN 更能捕捉低阶特征信息。
- Wide & Deep 部分的 embedding 层得需要针对 Deep 部分单独设计;而在 DeepFM 中,FM 和 Deep 部分共享 embedding 层,FM 训练得到的参数既作为 Wide 部分的输出,也作为 DNN 部分的输入
- end-end训练
- FM 部分:1+n
embedding 部分:n * k
DNN 部分:f * k * H1 + H1 * H2+H1
通过 embedding 层后,FM 部分直接输出没有参数需要学习,进入 DNN 部分的参数维度从原始 n 维降到 f*k 维
Google Deep&Cross
Google 2017年发表的Deep&Cross Network(DCN)同样是对Wide&Deep的进一步改进,主要的思路使用Cross网络替代了原来的Wide部分。其中设计Cross网络的基本动机是为了增加特征之间的交互力度,使用多层cross layer对输入向量进行特征交叉。单层cross layer的基本操作是将cross layer的输入向量xl与原始的输入向量x0进行交叉,并加入bias向量和原始xl输入向量。DCN本质上还是对Wide&Deep Wide部分表达能力不足的问题进行改进,与DeepFM的思路非常类似。
NFM

前面的 DeepFM 在 embedding 层后把 FM 部分直接 concat 起来(f*k 维,f 个 field,每个 filed 是 k 维向量)作为 DNN 的输入
Neural Factorization Machines,简称 NFM,提出了一种更加简单粗暴的方法,在 embedding 层后,做了一个叫做 BI-interaction 的操作,让各个 field 做 element-wise 后 sum 起来去做特征交叉,MLP 的输入规模直接压缩到 k 维,和特征的原始维度 n 和特征 field 维度 f 没有任何关系
Bi-interaction 听名字很高大上,其实操作很简单:就是让 f 个 field 两两 element-wise 相乘后,得到 f*(f-1)/2 个向量,然后直接 sum 起来,最后得到一个 k 维的向量。所以该层没有任何参数需要学习
- NFM 在 embedding 做了 bi-interaction 操作来做特征的交叉处理,优点是网络参数从 n 直接压缩到 k(比 FNN 和 DeepFM 的 f*k 还少),降低了网络复杂度,能够加速网络的训练得到模型;但同时这种方法也可能带来较大的信息损失
AFM
AFM的全称是Attentional Factorization Machines,通过前面的介绍我们很清楚的知道,FM其实就是经典的Wide&Deep结构,其中Wide部分是FM的一阶部分,Deep部分是FM的二阶部分,而AFM顾名思义,就是引入Attention机制的FM,具体到模型结构上,AFM其实是对FM的二阶部分的每个交叉特征赋予了权重,这个权重控制了交叉特征对最后结果的影响,也就非常类似于NLP领域的注意力机制(Attention Mechanism)。为了训练Attention权重,AFM加入了Attention Net,利用Attention Net训练好Attention权重后,再反向作用于FM二阶交叉特征之上,使FM获得根据样本特点调整特征权重的能力。
阿里DIN

AFM在FM中加入了Attention机制,2018年,阿里巴巴正式提出了融合了Attention机制的深度学习模型——Deep Interest Network。与AFM将Attention与FM结合不同的是,DIN将Attention机制作用于深度神经网络,在模型的embedding layer和concatenate layer之间加入了attention unit,使模型能够根据候选商品的不同,调整不同特征的权重。
阿里DIEN
DIEN的全称为Deep Interest Evolution Network,它不仅是对DIN的进一步“进化”,更重要的是DIEN通过引入序列模型 AUGRU模拟了用户兴趣进化的过程。具体来讲模型的主要特点是在Embedding layer和Concatenate layer之间加入了生成兴趣的Interest Extractor Layer和模拟兴趣演化的Interest Evolving layer。其中Interest Extractor Layer使用了DIN的结构抽取了每一个时间片内用户的兴趣,Interest Evolving layer则利用序列模型AUGRU的结构将不同时间的用户兴趣串联起来,形成兴趣进化的链条。最终再把当前时刻的“兴趣向量”输入上层的多层全连接网络,与其他特征一起进行最终的CTR预估。
xDeepFM
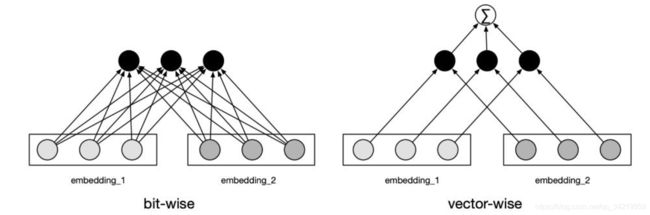
与DCN相同的是,都提出了要cross feature explicitly;但不同的是,DCN中的特征交叉是element-wise的,而CIN中的特征交叉是vector-wise的
xDeepFM模型结构如下,整个模型分为三个部分:
(1)Linear Part:捕捉线性特征
(2)CIN Part:压缩交互网络,显式地、vector-wise地学习高阶交叉特征
(3)DNN Part:隐式地、bit-wise地学习高阶交叉特征

CIN在实际计算中时间复杂度过高
CIN的sum-pooling操作会损失一定的信息
参考
https://www.jianshu.com/p/d5dfe2013715
https://blog.csdn.net/dengxing1234/article/details/79916532