用集算器实现文本比对
控制台命令、JAVA、pyton、perl都可以进行简单的文本比对,但这些工具不擅长集合运算、结构化运算,编写多线程代码较复杂,处理多字段对比、大文件对比、异构文件对比等情况时很繁琐。
免费的集算器支持集合运算、游标运算、结构化运算,简化了多线程代码,可以弥补上述不足。集算器应用简单,支持独立使用、控制台执行、JAVA代码调用,详情参考集算器实现文本处理的应用方法。
下面用若干例子说明集算器实现文件对比的过程。
找到两个文件相同的列值
有两个文件:f1.txt和f2.txt,都有Name和Dept这两个列,第一行是列名,现在需要在这两个文件里找到相同的Name。部分数据如下:
文件f1.txt:
|
文件f2.txt:
|
集算器代码:

用import函数将文件读入内存,再用函数isect进行交集运算。默认的分隔符是tab。@t表示将第一行读为列名,后续的计算就可以直接用Name和Dept来引用相应的列,如果第一行不是列名,则应当用_1和_2这种默认列名来引用。
函数isect等价于交集运算符,代码可写作:A1.(Name) ^ B1.(Name) 。
结果如下: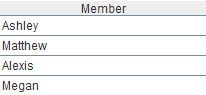
引申:
1、用交集运算可找到相同的字段值,类似的还有并集、差集、合集。
找到f1.txt和f2.txt共同的Name(合并重复值),可用函数union或并集运算符”&”,结果如下:
找到在f1.txt但不在f2.txt的Name,可用函数diff或差集运算符”\”,结果如下:
![]()
将f1.txt和f2.txt中的Name合并起来,允许重复,可用函数conj或和集运算符”|”,结果如下:

2、进行整行对比时,可用@ts将文件读为字符串集合。如下:

找到CSV中修改过的记录
old.csv是原始文件,new.csv是对old.csv进行增删改操作后的文件,两者的逻辑主键是userName和date,需要找出old.csv文件中哪些记录被修改过。
部分数据如下:
|
|
Old.csv |
New.csv |
|
1 2 3 4 5 6 7 8 9 |
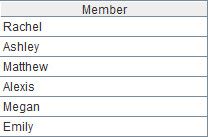
userName,date,saleValue,saleCount Rachel,2015-03-01,4500,9 Rachel,2015-03-03,8700,4 Tom,2015-03-02,3000,8 Tom,2015-03-03,5000,7 Tom,2015-03-04,6000,12 John,2015-03-02,4000,3 John,2015-03-02,4300,9 John,2015-03-04,4800,4 |
userName,date,saleValue,saleCount Rachel,2015-03-01,4500,9 Rachel,2015-03-02,5000,5 Ashley,2015-03-01,6000,5 Rachel,2015-03-03,11700,4 Tom,2015-03-03,5000,7 Tom,2015-03-04,6000,12 John,2015-03-02,4000,3 John,2015-03-02,4300,9 John,2015-03-04,4800,4 |
可以看到new.csv中的第2、3行是新增的记录,第4行是修改的记录,old.csv中第3行是删除的记录。
集算器代码:

以逗号为分隔符读入文件,将数据按照关键字排序。之后先求出新增的记录(主键不同),存在变量new中,再找到old.txt和new.txt有差异的记录(任意字段不同),存在变量diff中,最后计算diff和new的差集,也就是被修改过的记录(主键相同,其他字段不同)。结果如下:
![]()
引申:被删除的记录可以这样计算:[A2,B2].merge@d(userName,date)
找到两个大文件相同的行
文件file1.txt和file2.txt存储着大量的字符串,找出两者共同的行数据(交集)。部分数据如下:
| 大文件file1.txt |
大文件file2.txt |
| C:\Windows\System32\0409 C:\Windows\System32\9999 C:\Windows\System32\2hps.ico C:\Windows\System32\aaclient.dll …… C:\Windows\System32\zh-TW\msimsg.dll.mui C:\Windows\System32\zh-TW\msprivs.dll.mui C:\Windows\System32\zh-TW\WMPhoto.dll.mui C:\Windows\System32\zh-TW\WMPhoto.dll1.mui |
C:\Windows\System32\0409 C:\Windows\System32\2052 C:\Windows\System32\2hps.ico C:\Windows\System32\aaclient.dll …… C:\Windows\System32\zh-TW\msimsg.dll.mui C:\Windows\System32\zh-TW\msprivs.dll.mui C:\Windows\System32\zh-TW\WMPhoto.dll.mui C:\Windows\System32\zh-TW\WMPhoto.dll2.mui |
集算器代码:

函数cursor以游标形式打开文件,并不会将数据全部读入内存。默认以tab为列分割符读入全部的字段,自动命名为_1、_2、_3…_n。函数sortx可对游标进行排序,函数merge可对有序数据进行归并计算,@x表示对游标归并,@i表示归并结果为交集。函数export可将游标写入文件,结果如下:
| C:\Windows\System32\0409 C:\Windows\System32\2052\VSJitDebuggerUI.dll C:\Windows\System32\2hps.ico C:\Windows\System32\ACCTRES.dll C:\Windows\System32\ARP.EXE … |
引申:函数merge使用@i时表示交集,使用@u表示并集,使用@d表示差集,默认为归并,即将两个文件按字符顺序进行合并,并允许重复。
一大一小文件比较
文件File1.txt体积较大,但file2.txt可读入内存,现在需要找到两者相同的行。
集算器代码如下:
可以将小文件读入内存,再用Hash查找的方法来进行集合运算,这样可以显著提高效率。函数primary可设置主键,index可建立hash索引。函数find可用来查询出游标A1和B1相同的数据,即求交集。
引申:
1、求差集可将A3代码写作=A1.select(!B1.find(~._1))
2、求并集可先计算出file1和file2的差集,再和file2做合并:

用并行计算提高文件比较的性能
前面的算法是串行,改成并行可以进一步提高性能,具体做法是用多个线程并行读取文件,每个线程都用游标访问文件的一部分,并同时进行集合计算,最后再将每个游标的结果合并。
在相同的硬件环境下对2.77G大文件和39.93M的小文件进行测试,串行时平均耗时85秒,并行时平均耗时47秒,性能提高接近一倍。由于集合运算的复杂度较小,瓶颈会产生在硬盘读取上,如果进一步加大运算的复杂度,性能提升的幅度将会更大。
集算器并行计算的代码如下:

将文件分为4段,生成4个游标同时计算,计算完成后合并游标。
分段数量不宜过多,一般应该等于系统并行数量,否则会排队等待。并行数量可以在配置文件中设置。函数cursor使用了选项@z,这表示将文件分段,用游标取其中的某一段。之所以是“大致分”,是因为精确分会出现半行数据的情况,而集算器会去头补位,自动取出整行数据。
异构文件比较
Data.txt是tab分隔的文本,共有6个字段,其中here字段是分号分隔的字符串。文件list是单列数据。现在要比较两个文件,如果某条记录的here字段拆分后和List.txt中的任意一行匹配,则将这条记录输出到result.txt中。
源数据如下:
| Data.txt |
List.txt |
||||||||||||||||||||||||||||
|
Gee Whiz Lol
|
集算器代码:

代码中函数select可进行查询,函数array可拆分字符串,”^”表示求交集,”[]”表示空集。
结果如下:
|
根据HTML排除字符串列表
找出列表tagList里哪些字符串不在文件a.html中。TagList="Marketing","sales","humanresource","Finance","R&D","commerce"。a.html如下:
|
集算器代码
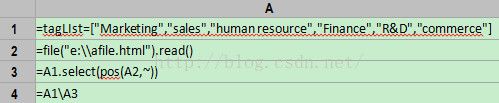
先用函数read将文件读为字符串,再用函数select进行查询,条件是:A2(大字符串)中是否包含~(A1的当前成员),最后计算差集,结果如下:
