基于邻域的算法
仅基于用户行为数据的推荐算法是协同过滤算法,应用最广的是基于邻域的算法。是基于统计的方法。大体分为两种,一是基于用户的协同过滤算法,二是基于物品的协同过滤算法。
一、基于用户的协同过滤算法(已被应用于邮件过滤和新闻过滤中)——UserCF
1.原始算法(参数:K)
总体思路:先找到有相似兴趣的其他用户,然后把那些用户喜欢、而用户A没有听说过的物品推荐表给A。由此可知,该算法主要由两个步骤:
1)找到和目标用户兴趣相似的用户集合。关键是计算两个用户的兴趣相似度,主要利用行为的相似度来计算。
2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
技术点:
(1)用户兴趣相似度计算:给定两个用户u和v,看其分别有过正反馈的物品集合N(u)和N(v)。这个我理解为:一个表的ID是用户,对应的内容是其有过反馈的物品
Jaccard公式如下:

或者用余弦相似度(较常用):

为了避免对两两用户均计算相似度,可先建立物品到用户的倒排表。这个我理解为:一个表的ID是物品,对应的内容是对其有过反馈的用户。然后建立一个稀疏矩阵,其中行和列均对应用户。矩阵中元素C[u][v] = 用户u和v均有过反馈的物品个数。对角线上的元素均为0.
(2)推荐物品
UserCF会给和他推荐兴趣最相似的K个用户喜欢的物品。用户u对物品i的感兴趣程度可以用下边的公式计算:
![]()
对于这个式子,我理解为:相似的K个用户中对该物品有过正反馈的的用户,对每个用户计算用户相似度*该用户对物品的喜欢程度,对这些用户求一个加和。
2. 参数K对算法性能的影响
准确率和召回率并不和参数K呈线性关系。选择合适K对推荐系统精度很重要。敏感度不高。
K越大推荐结果越热门、覆盖率越低。
3. 算法改进
对用户相似度:若两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。
4. UserCF实际应用
Digg新闻网站。个性化新闻推荐更强调抓住新闻热点,热门程度和时效性是个性化新闻推荐的热点,而个性化相对略次要。个性化的粒度较粗。此外,用UserCF算法需维护一个用户相似性表,用户数相对固定,易维护。
5. 算法优缺点:
缺点:随着网站用户数变大,计算用户兴趣相似度矩阵越来越费劲。且很难对推荐结果做出解释。
6. python实践
计算用户兴趣相似度时,可用欧几里得距离(过于严格,结果十分不准)或皮尔逊相关度计算相似度评价值。皮尔逊相关度是判断两组数据与某一直线拟合程度的度量,在数据不是很规范时倾向于给出更好的结果。皮尔逊相关度对应的结果是一条尽可能靠近图中所有坐标点的最佳拟合线
二、基于物品的协同过滤算法(大多数电商采用,如Amazon和Netflix)—— ItemCF
1. 原始算法(参数:K)
ItemCF算法不利用物品的内容属性计算物品间的相似度,而通过分析用户的行为记录计算物品之间的相似度。即物品A和物品B有很大的相似度是因为喜欢A的用户大都也喜欢物品B。可利用用户的历史行为给推荐结果提供推荐解释。
算法分两个步骤:
1)计算物品之间的相似度
2)根据物品的相似度和用户的历史行为给用户生成推荐列表
技术点:
(1)物品相似度计算:
法1:喜欢物品i的用户中有多少比例的用户也喜欢物品j。用wij表示
缺陷:若物品j很热门,则该比例值wij很大,接近1.由此造成任何物品都会和热门物品有很大的相似度,对长尾物品挖掘不很。
法2:对分母进行改变,如下:
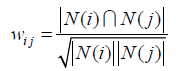
个人认为:这个改变和用户间兴趣相似度的余弦相似度很相似!!!该式惩罚了物品的权重,减轻了热门物品会和很多物品相似的可能性。
和UserCF一样,先建立用户—物品倒排表,即表的ID是用户,对应的内容是他喜欢的物品的列表。然后建立一个稀疏矩阵,其中行和列均对应物品。矩阵中元素C[i][j] =同时喜欢物品i和物品j的用户 数。对角线上的元素均为0。最后将矩阵归一化得到物品间的余弦相似度矩阵。
(2)推荐物品
用户u对物品j感兴趣程度可用下边的公式计算,其中j是被推荐的物品,rui是用户u对物品i的兴趣。
![]()
对于这个式子,可理解为:和用户历史上感兴趣的物品最相似的物品越有可能在用户的推荐列表中获得较高的排名。
2. 参数K对算法性能的影响
准确率和召回率、流行度不和参数K成线性关系。选择合适K对推荐系统精度很重要。
K越大,覆盖率越低。
3. 算法改进
考虑用户活跃度对物品相似度的影响:并非每个用户的贡献都相同。如批发书的用户。该用户虽然活跃,但其购买的物品两两间的相似度的贡献应远远小于一个只买几个自己喜欢的物品的用户。
改进的物品相似度:IUF。如下所示:

在实际计算中一般对于上述过于活跃的用户直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中(Item-ICF)。
其次,若将物品相似度按最大值归一化,可提高推荐的准确率,还可提高推荐的覆盖率和多样性。若不进行归一化,则会推荐较热门的类里面的物品。
对于物品相似度的法2计算方式,在实际应用中,热门的j仍会有较大的相似度。对于该问题,有如下解决方案。
方案一:在分母上加大对热门物品的惩罚——指数式惩罚。该方法可在适当牺牲准确率和召回率的情况下提升结果的覆盖率和新颖性。
每个用户一般都会在不同的领域喜欢一种物品。两个不同领域的最热门物品间往往具有较高的相似度,这时仅靠用户行为数据是不能解决该问题的,只能靠引入物品的内容数据解决该问题,如对不同的物品降低权重。
4. 算法优缺点
优点:可提供推荐解释
5. 实际应用(电商中)
维护一张物品相关度的表,一天更新一次。用户兴趣较固定和持久。用户大都不需流行度来辅助判断一个物品的好坏,而是通过自己熟悉领域的知识自己判断物品的质量。目的是帮助用户发现和他领域相关的物品。
三、 UserCF VS ItemCF
UserCF和ItemCF使用场合:
1.UserCF推荐结果注重于反应和用户兴趣相似的小群体的热点,而ItemCF注重于维系用户的历史兴趣。
2.UserCF的推荐更社会化,反映了用户所在小型兴趣群体中物品的热门程度,而ItemCF的推荐更个性化,反映了用户自己的兴趣传承。
新闻网站中物品相似度变化很快,物品数目庞大,用户兴趣相对固定,故新闻网站的个性化推荐较适使用UserCF。而在图书、互联网网站中,物品数目较少,物品相似度相对于用户的兴趣一般较稳定,用ItemCF较好。
