通过爬虫爬取公共资源交易平台(四川省)最近的招标信息
一:引入JSON的相关的依赖
net.sf.json-lib
json-lib
2.4
jdk15
二:通过请求的url获取URLConnection连接
package com.svse.pachong;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;import org.apache.log4j.Logger;
/**
* 通过请求的url获取URLConnection连接
* @author lenovo
* @date 2019年1月22日
* description:
*/
public class open_url_test {
public static Logger logger = Logger.getLogger(open_url_test.class);
public boolean openurl(String url_infor) throws Exception{
URL url = new URL(url_infor);
// 连接类的父类,抽象类
URLConnection urlConnection = url.openConnection();
// http的连接类
HttpURLConnection httpURLConnection = (HttpURLConnection) urlConnection;
/* 设定请求的方法,默认是GET(对于知识库的附件服务器必须是GET,如果是POST会返回405。流程附件迁移功能里面必须是POST,有所区分。)*/
httpURLConnection.setRequestMethod("GET");
// 设置字符编码 httpURLConnection.setRequestProperty("Charset", "UTF-8");
// 打开到此 URL引用的资源的通信链接(如果尚未建立这样的连接)。
int code = httpURLConnection.getResponseCode();
System.out.println("code:"+code); //连接成功 200
try {
InputStream inputStream = httpURLConnection.getInputStream();
System.out.println("连接成功");
logger.info("打开"+url_infor+"成功!");
return true;
}catch (Exception exception){
logger.info("打开"+url_infor+"失败!");
return false;
}
}
}
三:通过爬取的url解析想要的数据,并以json的格式返回
package com.svse.pachong;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.nio.charset.Charset;
import net.sf.json.JSONException;
import net.sf.json.JSONObject;/**
* 通过爬取的url解析想要的数据,并以json的格式返回
* @param urlString 需要爬取的网站url路径
* @return 返回json结果的数据
* @throws IOException
* @throws JSONException
*/
public class readData {
public static JSONObject readData(String urlString) throws IOException, JSONException{
InputStream is = new URL(urlString).openStream();
try {
BufferedReader rd = new BufferedReader(new InputStreamReader(is, Charset.forName("UTF-8")));
StringBuilder sb = new StringBuilder();
int cp;
while ((cp = rd.read()) != -1) {
sb.append((char) cp);
}
String jsonText = sb.toString();
JSONObject json = JSONObject.fromObject(jsonText);
return json;
} finally {
is.close();
}
}
}
四:爬取入口
package com.svse.pachong;
import java.io.IOException;
import net.sf.json.JSONArray;
import net.sf.json.JSONException;
import net.sf.json.JSONObject;/**
* 爬取的入口
* @author lenovo
* @date 2019年1月22日
* description:
*/
public class Main {
static String urlString = "http://www.scggzy.gov.cn/Info/GetInfoListNew?keywords=×=4×Start=×End=&province=&area=&businessType=&informationType=&industryType=&page=1&parm=1534929604640";
@SuppressWarnings("static-access")
public static void main(String[] args) {
open_url_test oUrl = new open_url_test();
try {
if (oUrl.openurl(urlString)) {
readData rData = new readData();
JSONObject json = rData.readData(urlString);
JSONObject ob=JSONObject.fromObject(json);
String data=ob.get("data").toString(); //JSONObject 转 String
data="["+data.substring(1,data.length()-1)+"]";
JSONArray json2=JSONArray.fromObject(data); //String 转 JSONArray
for (int i = 0; i < 10; i++) {
JSONObject jsonObject = (JSONObject) json2.get(i);
System.out.println("--------------------------------------------");
System.out.println("项目: "+jsonObject.get("Title"));
System.out.println("时间: "+jsonObject.get("CreateDateStr"));
System.out.println(jsonObject.get("TableName"));
System.out.println(jsonObject.get("Link"));
System.out.println( jsonObject.get("province") +" "+jsonObject.get("username")+" "+jsonObject.get("businessType")+" "+jsonObject.get("NoticeType"));
}
}else{
System.out.println("解析数据失败!");
}
} catch (JSONException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}}
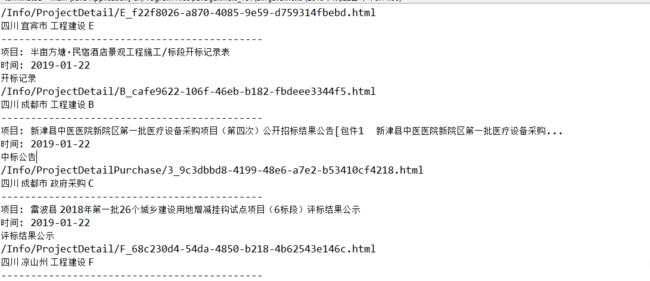
四:测试结果
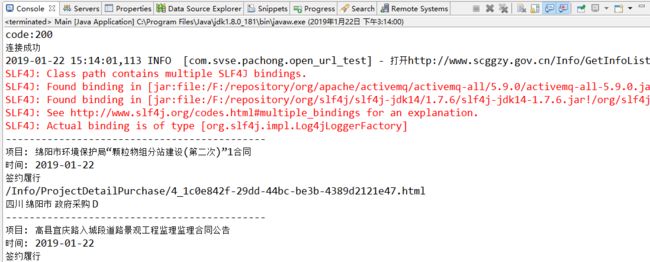

至此,整个爬取的任务就结束了!