第一章:绪论
1.1什么是数据结构
1.2基本概念与术语
1.3抽象数据类型的表示与实现
1.4算法与算法分析
1.1什么是数据结构
定义:数据结构(data structure)是相互之间存在一种或多种特定关系的数据元素的集合。
基本的数据结构:
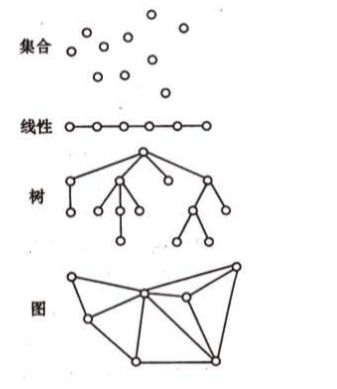
• (1) 集合:结构中的数据元素之间除了同属于一个集合的关系外,没有其他关系;
• (2)线性结构:结构中的数据元素之间存在一个对一个的关系;(一对一)
• (3)树形结构:结构中的数据元素之间存在一个对多个的关系;(一对多)
• (4)图状结构或网状结构:结构中的数据元素之间存在多个对多个的关系(多对多)

1.2 基本概念和术语
数据(data):是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。对计算机科学而言,数据的含义极为广泛,如图像、声音等都可以通过编码而归于数据的范畴。
数据元素(data element):是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。有时,一个数据元素可由若干个数据项(data item)组成,例如把一本书的目录作为一个数据元素,书目录信息中的每一项为一个数据项,数据项是数据不可分割的最小单位。
数据对象(data object):是性质相同的数据元素的集合,是数据的一个子集,例如整数数据对象是集合N={0,±1,±2,±,3±,4……},字母字符数据对象是集合C={A,B,C,D……,Z};
数据结构(data structure):是相互之间存在一种或多种特定关系的数据元素的集合。
1.3抽象数据类型的表示与实现
抽象数据类型可通过固有数据类型来表示和实现,即利用处理器中已存在的数据类型来说明新的结构,用已经实现的操作来组合新的操作。
抽象数据类型 rectangle(矩形) 的表示和实现(C++方式)。
class rectangle {
public:
int w,h; //成员变量,宽和高
void init (int w_,int h_); //成员函数,设置宽高
int area(); //成员函数,求面积
int perimeter(); //成员函数,求周长
}
1.4算法和算法分析
什么是算法
算法(algorithm)是对特定问题求解步骤的一种,描述,它是指令的有限序列,其中每一条指令表示一个或多个操作;此外,一个算法还具有下列5个重要特性:
(1):有穷性 一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都可在有穷时间内完成。
(2):确定性 算法中每一条指令必须有确切的含义,读者理解时不会产生二义性。并且,在任何条件下,算法只有唯一的一条执行路径,即对于相同的输入只能得出相同的输出。
(3):可行性 一个算法是能行的,即算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现的。
(4):输入 一个算法有零个或多个的输入,这些输入取自于某个特定的对象的集合。
(5):输出 一个算法有一个或多个的输出,这些输出是同输入有着某些特定关系的量。
算法设计的要求
通常一个”好”的算法应该考虑到以下目标。
(1):正确性 算法应当满足具体问题的需求。通常一个大型问题的需求,要以特定的规格说明方式给出,而一个实习问题或练习题,往往就不那么严格,目前多数是用自然语言描述需求,它至少应当包括对于输入、输出和加工处理等的明确的无歧义性的描述。设计或选择的算法应当能正确地反映这种需求;否则,算法的正确与否的衡量准则就不存在了。
“正确”一词的含义在通常的用法中有很大差别,大体可分为以下4个层次;
a.程序不含语法错误;
b.程序对于几组输入数据能够得出满足规格说明要求的结果;
c.程序对于精心选择的典型、苛刻而带有刁难性的几组输入数据能够得出满足规格说明要求的结果;
d.程序对于一切合法的输入数据都能产生满足规格说明要求的结果。
显然,达到d层意义下的正确是极为困难的,所有不同输入数据的数量非常大,逐一验证的方法是不现实的,对于大型软件需要进行专业测试,而一般情况下,通常以c层意义的正确性作为衡量一个程序是否合格的标准
(2):可读性 算法主要是为了人的阅读与交流,其次才是机器执行。可读性好有助于对算法的理解;晦涩难懂的程序易于隐藏较多错误,难以调试和修改。
(3):健壮性 当输入数据非法时,算法也能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果。
(4):效率与低存储量需求 通俗地说,效率指的是算法执行的时间,对于同一个问题如果有多个算法可以解决,执行时间短的算法效率高。存储量需求指算法执行过程中所需要的最大存储空间。效率与低存储量需求这两者都与问题的规模有关。就像求100个人的平均分与求1000个人的平均分所花的执行时间或运行空间显然有一定的差别。
算法效率的度量
算法执行时间需通过依据该算法编制的程序在计算机上运行时所消耗的时间来度量。而度量一个程序的执行时间通常有两种方法。
(1)事后统计的方法 因为计算机内部都有计时功能,有的甚至可以精确到毫秒级,不同算法的程序可通过一组或若干组相同的统计数据以分辨优劣。但这种方法有两个缺陷:一是必须运行依据算法编制的程序;二是所得时间的统计量依赖于计算机的硬件、软件等环境因素,有时容易掩盖算法本身的优劣。因此人们常常用另一种事前分析估值的方法。
(2)事前分析估值的方法 一个高级程序语言编写的程序在计算机上运行时所消耗的时间取决于下列因素:
① 依据的算法选用何种策略;
② 问题的规模,例如求100以内还是1000以内的素数;
③ 书写程序的语言,对于同一个算法,实现语言的级别越高,执行效率就越低;
④ 编译程序所产生的机器代码的质量;
⑤ 机器执行指令的速度;
时间复杂度
显然,同一个算法用不同的语言实现,或者用不同的编译程序进行编译,或者在不同的计算机上运行时,效率均不同。这表明使用绝对的时间单位衡量算法的效率时不合适的。抛开这些与计算机硬件、软件有关的因素,可以认为一个特定算法“运行工作量”的大小,只依赖于问题的规模(通常用整数量n表示),或者说,它是问题规模的函数。
一个算法是由控制结构(顺序、分支和循环3种)和原操作(指固有数据类型的操作)构成的,则算法时间取决于两者的综合效果,为了便于比较同一问题的不同算法,通常的做法是,从算法中选取一种对于所研究的问题(或算法类型)来说是基本操作的原操作,以该基本操作重复执行的次数作为算法的时间度量。

一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数f(n)算法的时间度量记作:
它表示随问题规模n增大,算法执行时间的增长率和f(n)的增长率相同,称做算法的渐进时间复杂度,简称时间复杂度。
显然,被称做问题的基本操作的原操作应是其重复执行次数和算法的执行时间成正比的原操作,多数情况下它是最深层循环内的语句中的原操作,它的执行次数和包含它的语句的频度相同,语句的频度指的是该语句重复执行的次数,例如,下下列3个程序中:
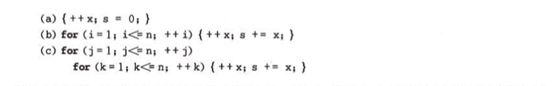
这三个程序段的时间复杂度分别为O(1),O(n),O(n²)。
一般情况下,对一个问题(或一类算法)只需选择一种基本操作来讨论算法的时间复杂度即可,有时也需要同时考虑几种基本操作,甚至可以对不同的操作赋予不同的权重值,以反映执行不同操作所需的相对时间,这种做法便于综合比较解决同一问题的两种完全不同的算法。
由于算法时间复杂度考虑的只是对于问题规模n的增长率,则在难以精确计算基本操作执行次数(或语句频度)的情况下,只需要求出它关于n的增长率或阶即可。例如:

++x执行的频度表达式应该是(n-1)(n-2)/2;n²是其增长最快的项,所以其时间复杂度为O(n²) 。
算法的存储空间需求
类似算法的时间复杂度,我们以空间复杂度作为算法所需存储空间的度量,记作:
其中n为问题的规模大小,一个上机执行的程序除了需要存储空间来寄存本身所使用指令、常数、变量和输入数据外,也需要一些数据进行操作的工作单元和存储一些为实现计算所需信息的辅助空间。若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析除输入和程序之外的额外空间,否则应同时考虑输入本身所需空间(和输入数据的表示形式有关)。若额外空间对于输入数据来说是常数,则称此算法为原地工作。如果所占空间依赖于特定的输入,则除特别指明外,均按最坏情况来分析。