【自动驾驶产业流程调研】(更新中)从招聘需求,观察自动驾驶领域行业概貌,及自动驾驶公司运作流程。
文章目录
- 一、 首先查看各个岗位要求
- 感知研发(融合预测)
- 感知深度学习方向
- 路径规划与决策
- 控制算法
- 高精地图研发
- 仿真研发
- 行为预测 与 轨迹预测
- 机器学习基础设施搭建
- 前端研发
- 后端研发
- 软件研发工程师-嵌入式
- 软件研发工程师- 自动驾驶系统
- 软件研发工程师 - 基础架构
- 地图识别 提取
- 二、各个岗位之间的关系
- 三、汽车如何自动上路
- 第一步、感知这个世界 (我是谁?)
- 1、多传感器信息融合 (多种感官)
- 1) 摄像头
- 2) LiDAR 激光雷达
- 5) UWB 超宽带无线载波通信
- 4)毫米波雷达
- 5)红外夜视
- 6) 组合导航设备
- 7) 压力传感器
- 8) 流量传感器
- 9) IMU
- 2、目标识别 (目标检测)
- 1)行人识别
- 2) 车辆识别
- 3) 其他物体及环境检测
- 4) 交通信号灯检测与识别
- 5) 交通标志检测与识别
- 6) 车道线检测与识别
- 3、轨迹预测 (目标跟踪)
- 1) 单目标跟踪
- 2) 多目标跟踪
- 第二步、定位 (我在哪里?)
- 高精地图定位
- SLAM 同步定位与建模
- 学习路径
- VIO(visual-inertial odometry)
- 单目视觉SLAM
- 融合了IMU 和视觉信息的VIO/VINS
- 机器人定位导航/状态估计
- 平台工程
- 云平台
- V2X通信
- 车载平台
- 车联网系统
- 软件研发工程师 - 自动驾驶系统
- 第三步、决策与路径规划 (我要到哪里去?我该如何去?)
- 路线规划
- 1、Goal-Directed Techniques
- 2、Separator-Based Techniques
- 3、Hierarchical Techniques
- 4、Bounded-Hop Techniques
- 5、算法的结合
- 行为选择
- 运动规划
- 第四步、 控制 (执行及整车应用)
- 高级控制算法
- 自动驾驶级别 L0 L1 L2 L3 L4 L5
一、 首先查看各个岗位要求

感知研发(融合预测)
岗位职责:
将独立感知模块的输出统一并进行融合,得到适合后续路径规划模块的表示。
岗位要求(前三项至少满足一项):
熟悉计算机视觉中多视角几何知识;
熟悉基于滤波和优化的状态估计算法,并可以灵活运用解决实际问题;
熟悉传统统计机器学习知识,并有项目实践经验;
良好的编程能力,熟悉python, c++,掌握常见的算法和数据结构知识。
加分项:
有多传感器融合或轨迹预测研发经验;
参加kaggle比赛获得前十名者;
参加过ACM/ICPC等编程竞赛者取得优异成绩。
感知深度学习方向
岗位职责:
追踪并改进前沿深度学习算法,包括但不限于基础深度学习模型设计,基于视觉与LiDAR的物体检测与分割,目标追踪等。
岗位要求:
在计算机视觉/深度学习/机器感知三者之中至少熟悉一项基本知识,有处理真实大规模数据经验(课程作业除外);
在以上三者之中,对某一项有深入研究或理解;
熟悉python, c++;
动手能力强,可以快速将想法落实。
加分项:
有计算机视觉或机器学习相关研究经验,有高水平论文发表;
参加kaggle比赛获得前十名者;
参加过ACM/ICPC等编程竞赛者取得优异成绩。
路径规划与决策
实现和优化自动驾驶卡车的决策与路径规划工作;
对接上游感知团队和下游控制团队,从整个系统角度设计合适的planning模块,并对上下游提出需求。
控制算法
L4级别重卡自动驾驶控制系统设计、研发及工程和产品化;
根据产品需求制订控制组技术路线和要求,和团队一起完成控制算法的开发/优化、代码编写、仿真/实车验证与调试;
机器人,计算机科学,机电控制、机械电子等相关专业硕士以上学历;
掌握控制理论以及基本控制方法(PID、MPC、LQR、最优控制等),有实际控制系统开发经验;
熟练使用Linux和C/C++语言;
具有较强的动手能力,善于解决实际问题。
熟悉ROS操作系统者优先;
熟悉汽车纵、横向动力学特性,有车辆动力学建模/仿真经验者优先;
高精地图研发
岗位职责:
使用多源传感器(包括但不限于相机与LiDAR)开发基于不同依据的高精度定位模块,用于自动驾驶中分米级别的高精度定位;
处理多源传感器与定位算法输出结果的融合;
综合使用相关知识,完成大规模自动化的多源传感器标定(包括但不限于相机、LiDAR、IMU)。
岗位要求:基础项(前三项至少满足一项)
熟悉计算机视觉中多视角几何知识;
熟悉常用vSLAM,VO/VIO或LiDAR SLAM算法,有实际动手或项目经验;
熟悉基于滤波和优化的状态估计算法,并可以灵活运用解决实际问题;
熟悉python, c++,有很强的动手能力。
加分项:
有计算机视觉或机器人相关研究经验,有高水平论文发表;
有大规模定位系统开发和实践经验,有实际处理原始传感器数据的动手经历。
仿真研发
行为预测 与 轨迹预测
机器学习基础设施搭建
前端研发
后端研发
软件研发工程师-嵌入式
岗位职责:
负责自动驾驶嵌入式系统开发与验证;
负责传感器的选型、测试、评估、应用程序开发、实车测试;
负责网络性能优化及代码维护;
负责上位机图像显示、调试及管理,UI设计。
熟练掌握C/C++语言,掌握python语言,熟悉Linux系统、Shell、Makefile;
熟练掌握Linux环境下的 C/C++程序调试手段;
精通Socket网络编程,了解TCP、UDP、HTTP等网络协议;
精通Linux多线程编程、进程间通信、文件I/O操作等;
熟悉Linux驱动,有嵌入式开发经验;
至少一种无人车常用传感器开发经验,如:camera、LiDAR、GNSS/INS、Radar;
具有很强的动手能力,能够进行软硬件联调,熟悉232、485、CAN通信,能够熟练使用示波器进行问题分析;
学习能力强,良好的团队意识及沟通能力。
加分项:
有内存优化经验;
了解openCV,有一定的图像方面工作经验;
有无人车、Robotmaster、飞思卡尔等比赛经验;
有ROS使用经验。
软件研发工程师- 自动驾驶系统
1、负责自动驾驶系统的研发与维护;
2、负责算法模块到自动驾驶系统的集成;
3、负责上车模块安全性设计、开发和维护;
4、负责自动驾驶相关服务、软件与工具的研发与维护;
5、负责搭建大规模数据处理业务流和相关监控分析工具。
1、统招本科及以上学历,计算机、软件工程、网络工程相关专业背景,具备扎实的计算机理论基础,相关项目经验;
2、良好的编程能力,精通C++语言,熟悉python语言,了解语言特性,精通数据结构和算法;
3、对Linux/Unix操作系统和计算机网络有较好理解;
4、熟悉Docker相关容器技术;
5、熟悉分布式系统的设计原理;
1、有构建大型系统的经验;
2、具备设计高性能系统的能力;
3、有安全系统或模拟系统的开发经验;
软件研发工程师 - 基础架构
岗位职责:
参与企业内各类服务与工具的研发与维护;
参与自动驾驶相关软件产品的研发与维护;
参与搭建跨数据中心的数据仓库及应用;
参与搭建分布式计算平台;
参与搭建大规模数据处理业务流和相关监控分析工具;
参与搭建自动驾驶数据的存储和传输方案;
与团队高效协作进行敏捷式开发,保证项目按时交付。
岗位要求:
统招本科及以上学历,计算机、软件工程、网络工程相关专业背景,具备扎实的计算机理论基础,相关项目经验;
熟练使用Python、Go、C/C++中至少一种编程语言,具备良好的学习能力并持续关注领域动态,对新技术有探索精神;
熟悉主流Web前后端技术栈Flask/VueJS/MongoDB/MySQL/MQ/Redis/HTTPS/CORS/Nginx等;
熟悉分布式系统的设计原理,有能力编写高性能分布式系统;
对Linux/Unix操作系统和计算机网络有较好理解;
熟悉Docker、Kubernetes等相关容器技术;
熟悉标准化软件工程技术,如UML、设计模式、软件测试、敏捷开发等;
能快速掌握业务需求,具备很强的发现、分析和解决问题的能力,善于系统性思考并使用创新性思维解决问题,细心、责任心强、抗压能力强、沟通能力强、执行力强。
加分项:
有开源社区的代码贡献;
有混合云/数据中心/IaaS/PaaS/SaaS等平台项目经验;
有ROS系统开发的项目经验;
有IoT系统开发的项目经验;
能提前实习六个月以上者优先。
地图识别 提取
二、各个岗位之间的关系
感知研发(融合预测)
感知深度学习方向
路径规划与决策
控制算法
高精地图研发
仿真研发
行为预测 与 轨迹预测
机器学习基础设施搭建
前端研发
后端研发
软件研发工程师-嵌入式
软件研发工程师- 自动驾驶系统
软件研发工程师 - 基础架构
地图识别 提取
思考方式: 从人的角度出发,思考如何实现自动驾驶。
三、汽车如何自动上路

下图显示了自动驾驶汽车系统的典型架构框图,其中感知和决策系统显示为不同颜色的模块集合。感知系统负责使用车载传感器捕获的数据,如光探测和测距(LIDAR)、无线电探测和测距(雷达)、摄像机、全球定位系统(GPS),惯性测量单元(IMU)、里程表,以及有关传感器模型、道路网络、交通规则、汽车动力学等的先验信息的决策。
决策系统负责将汽车从初始位置导航到用户定义的最终目标,考虑到车辆状态和环境的内部表现,以及交通规则和乘客的舒适度。为了在整个环境中导航汽车,决策系统需要知道汽车在其中的位置。定位器模块负责根据环境的静态地图估计车辆状态(姿态、线速度、角速度等)。这些静态地图在自动操作之前自动计算,通常使用自动驾驶汽车本身的传感器,尽管需要手动注释(即人行横道或红绿灯的位置)或编辑(即移除传感器捕获的非静态物体)。自动驾驶汽车可以使用一个或多个不同的离线地图,如占用网格地图、缓解地图或地标地图,进行定位。
定位模块接收离线地图、传感器数据和平台里程计作为输入,并生成自动驾驶汽车的状态作为输出。需要注意的是,虽然GPS可能有助于定位控制器的处理,但由于树木、建筑物、隧道等造成的干扰,使得GPS定位不可靠,仅GPS在城市环境中进行适当的定位是不够的。映射器模块接收离线地图和状态作为输入,并生成在线地图作为输出。该在线地图通常是离线地图中的信息和使用传感器数据和当前状态在线计算的占用网格地图的合并。在线地图最好只包含环境的静态表示,因为这可能有助于决策系统的某些模块的操作。为了允许检测和移除在线地图中的移动对象,通常使用移动对象跟踪模块或MOT。
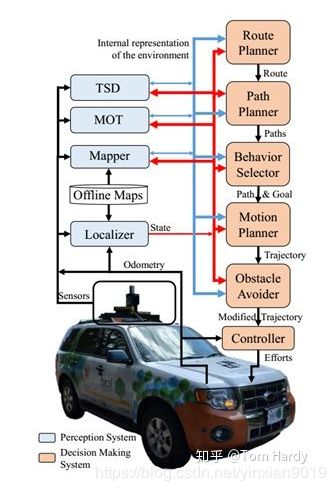
行为选择器模块负责选择当前的驾驶行为,如车道保持、交叉口处理、红绿灯处理等。行为选择器根据当前驾驶行为选择目标,并在决策时间范围内避免与环境中的静态和移动障碍物发生碰撞。运动规划模块负责计算从当前车辆状态到当前目标的轨迹,该轨迹遵循行为选择器定义的路径,满足车辆的运动学和动力学约束,并为乘客提供舒适性。
第一步、感知这个世界 (我是谁?)
感知什么内容?
1、多传感器信息融合 (多种感官)
1) 摄像头
成本低、可识别物体属性、依赖光线、易受恶劣天气影响
2) LiDAR 激光雷达
精度高、分辨率高、测距范围大、响应速度快
受恶劣天气影响、成本高
周围环境进行3D建模,获得环境的深度信息、识别障碍物、规划路径、以及进行环境测绘等等
5) UWB 超宽带无线载波通信
4)毫米波雷达
探测距离远、性能稳定、测速准确
无法感知平面目标信息,无法识别物体属性,相对分辨率低,覆盖区域呈扇形,有盲点区域
5)红外夜视
6) 组合导航设备
7) 压力传感器
8) 流量传感器
9) IMU
陀螺仪:测量XYZ三轴角速度
磁力计:指南针 水平方向偏航角
加速度计: XYZ三轴加速度
2、目标识别 (目标检测)
1)行人识别
2) 车辆识别
3) 其他物体及环境检测
4) 交通信号灯检测与识别
5) 交通标志检测与识别
6) 车道线检测与识别
3、轨迹预测 (目标跟踪)
1) 单目标跟踪
2) 多目标跟踪
第二步、定位 (我在哪里?)
高精地图定位
高精地图被认为是实现自动驾驶的重要技术方案,使用地图采集车先构建出包含非常详细的环境细节的地图,在正常运行的自动驾驶车辆上则利用SLAM重定位技术从高精地图里获取定位信息。
高精度地图主要有以下三大功能:地图匹配、辅助环境感知和路径规划。高精度地图将车辆位置精准的定位于车道之上、帮助车辆获取更为准确有效全面的当前位置交通状况并为无人车规划制定最优路线。
目前国内仅有13家企业取得了导航电子地图制作甲级资质,可以为主机厂商提供车载导航数据。而真正能够提供完善电子地图的只有七家,分别是:四维图新、高德软件、凯立德、易图通、灵图、瑞图万方、城际高科;只有8家参与到导航业务。
SLAM 同步定位与建模
从机器人定位导航的层面上认识SLAM的作用,SLAM只是机器人定位导航的一种方法,不同传感器的不同特性使其适用于不同的场合,为了提高定位导航系统的可靠性稳定性,在实际中往往涉及多传感器融合。而SLAM方法进行定位导航的优势在于不需要外部先验信息,使用范围更广泛。
后端建图实现的是稠密地图,即获取到周围环境详细的深度信息,也是实现避障、路径规划的任务的基础。
使用多传感器融合的方式提高定位系统的可靠性稳定性,这里面激光/视觉SLAM是其中一个重要的定位来源;另一方面在构建高精地图时,也会用到SLAM技术。
学习路径
入门书籍推荐高博的**《SLAM十四讲》,这本书不仅涵盖了SLAM和状态估计相关的基本理论知识,而且高博给出了每个理论模块的编程实现,第一遍建议可以先不细推公式,把书浏览一遍了解主要内容,第二遍就可以动手跟着书一点点撸代码了。之后就可以学习目前主流的开源框架**,在对SLAM有较深的了解和实践之后,建议读**《state estimation for robotics》和《Multi View Geometry》**,前者是介绍状态估计理论非常完备的一本书,举例来说,在非线性性非高斯章节中,作者从机器人的运动和测量方程出发,根据马尔科夫假设和贝叶斯公式,将目前主流的滤波(EKF,UKF,PF)方法统一在贝叶斯估计的框架下。后者涵盖了SLAM视觉几何的所有理论知识。
对三维旋转的描述计算需要李群李代数的知识,高博的书和《state estimation for robotics》都有详细讲解,简单来说,使用旋转矩阵表示的旋转方便向量的坐标计算,但直接对其优化是有约束优化问题(9个参数3个自由度),解决思路就是在三维旋转群的正切空间上对用李代数表示的旋转误差量进行无约束优化,对正切空间的理解可以参考《Lie groups, Lie algebras, projective geometry and optimization
for 3D Geometry, Engineering and Computer Vision》。
推公式的时候发现矩阵白学了?宝宝不哭,这有一本《the Matrix CookBook》送给你。
VIO(visual-inertial odometry)
即视觉惯性里程计,有时也叫视觉惯性系统(VINS,visual-inertial system),是融合相机和IMU数据实现SLAM的算法,根据融合框架的区别又分为紧耦合和松耦合,松耦合中视觉运动估计和惯导运动估计系统是两个独立的模块,将每个模块的输出结果进行融合,而紧耦合则是使用两个传感器的原始数据共同估计一组变量,传感器噪声也是相互影响的,紧耦合算法上比较复杂,但充分利用了传感器数据,可以实现更好的效果,是目前研究的重点。
VIO目前实现比较好的有vinsmono,okvis,MSCKF。前两个是基于非线性优化的方案而且框架比较相似,后者是基于滤波优化的方案,也是Google Tango上使用的方法,MSCKF目前并没有开源,不过宾夕法尼亚的Kumar实验室18年有一个相似的工作,目前已经开源。此外还有ROVIO。值得注意的是,虽然在纯视觉SLAM中,学界已经公认基于非线性优化方法的SLAM方法效果要好于滤波的方法,但在VIO中,非线性优化和滤波方法目前还没有很明显的优劣之分。我的理解是结合相机和IMU两种传感器的信息,提供了对当前状态更多的观测,使得算法对历史观测之间约束信息的依赖降低,这也是为什么okvis、vinsmono采用滑动窗口法(global bundle adjustment和filter 的折中)也能取得很好效果的原因。
单目视觉SLAM
单目视觉 SLAM 算法存在一些本身框架无法克服的缺陷,首先是尺度的问题 ,单目 SLAM 处理的图像帧丢失了环境的深度信息,即使通过对极约束和三角化恢复了空间路标点的三维信息,但是这个过程的深度恢复的刻度是任意的,并不是实际的物理尺度,导致的结果就是单目SLAM 估计出的运动轨迹即使形状吻合但是尺寸大小却不是实际轨迹尺寸;
由于基于视觉特征点进行三角化的精度和帧间位移是有关系的,当相机进行近似旋转运动的时候,三角化算法会退化导致特征点跟踪丢失,同时视觉 SLAM 一般采取第一帧作为世界坐标系,这样估计出的位姿是相对于第一帧图像的位姿,而不是相对于地球水平面 (世界坐标系) 的位姿,后者却是导航中真正需要的位姿,换言之,视觉方法估计的位姿不能和重力方向对齐。
融合了IMU 和视觉信息的VIO/VINS
通过引入 IMU 信息可以很好地解决上述问题,首先通过将 IMU 估计的位姿序列和相机估计的位姿序列对齐可以估计出相机轨迹的真实尺度,而且 IMU 可以很好地预测出图像帧的位姿以及上一时刻特征点在下帧图像的位置,提高特征跟踪算法匹配速度和应对快速旋转的算法鲁棒性,最后 IMU 中加速度计提供的重力向量可以将估计的位置转为实际导航需要的世界坐标系中。

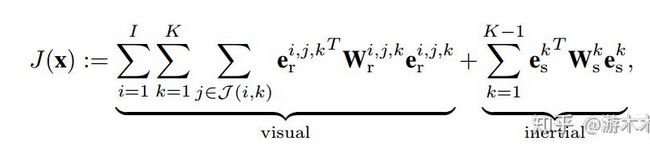
整个机器人的运动过程就是运动方程根据上一时刻状态和当前时刻运动输入 [公式] 预测当前状态,利用传感器的测量方程作为矫正的过程,在纯视觉SLAM中,因为缺少运动输入,预测方程提供信息不足,我们是直接采用测量方程构建重投影误差进行运动优化估计,而引入IMU数据之后,用IMU作为运动输入 [公式] 可以对状态进行很好的预测,VIO就是利用了运动预测和测量方程构建联合估计。具体来说,在假设噪声服从高斯分布,对非线性方程进行一阶近似的条件下,从最大后验估计的角度就可以推导出我们在VIO论文中看到的联合优化目标函数:
机器人定位导航/状态估计
状态估计的目的就是得出机器人三组状态量(位置、速度、姿态),为机器人运动控制做状态反馈。
平台工程
云平台
利用高精度地图进行路线规划,采用新型计算平台,整合多传感器信息,开发相应的车辆控制算法对汽车进行行为控制。
V2X通信
车载平台
车联网系统
软件研发工程师 - 自动驾驶系统
第三步、决策与路径规划 (我要到哪里去?我该如何去?)
路线规划
在过去的十年中,道路网络中的路线规划算法的性能有了显著的进步。新开发的算法可以在毫秒或更短的时间内计算出行驶方向。道路网中的路径规划方法在查询时间、预处理时间、空间利用率和对输入变化的鲁棒性等方面提供了不同的权衡。它们主要可分为四类:goal-directed, separator-based, hierarchical, bounded-hop, and combinations。
1、Goal-Directed Techniques
目标导向技术通过避免扫描不在目标顶点方向上的顶点来引导从源顶点到目标顶点的搜索。A是一种经典的目标导向最短路径算法。与Dijkstra算法相比,该算法在每个顶点上使用一个较低的距离函数,从而使更接近目标的顶点更早地被扫描,从而获得更好的性能。ALT(A、地标和三角形不等式)算法通过选取一小组顶点作为地标来增强A*。在预处理阶段,计算所有地标和所有顶点之间的距离。在查询阶段,利用包含地标的三角形不等式估计任意顶点的有效下界距离。查询性能和正确性取决于是否明智地选择顶点作为标记。另一个目标定向算法是Arc Flags。在预处理阶段,图被划分成具有少量边界顶点和平衡(即类似)顶点的单元。通过从每个边界顶点向后生长最短路径树,为树的所有弧(或边)设置第i个标志,计算单元i的弧标志。在查询阶段,该算法将修剪没有为包含目标顶点的单元格设置标志的边。arc flags方法具有较高的预处理时间,但在目标定向技术中查询时间最快。
2、Separator-Based Techniques
基于分隔符的技术基于顶点或边分隔符。顶点(或边)分隔符是顶点(或边)的一个小子集,其移除将图分解为几个平衡的单元。基于顶点分隔符的算法使用顶点分隔符来计算覆盖图。快捷边将添加到覆盖图中,以便保留与完整图的任何顶点对之间的距离。覆盖图比完整图小得多,用于加速查询算法。HPML(High Performance multivel Routing,高性能多级路由)算法是这种方法的一个变种,它显著减少了查询时间,但代价是增加了空间使用量和预处理时间,在不同的级别上为图添加了更多的快捷方式。
基于弧分隔符的算法使用边界分隔符将图分解为平衡的单元,试图最小化连接不同单元边界顶点的切割边数。快捷方式将添加到覆盖图中,以保持每个单元内边界顶点之间的距离。CRP(Customizable Route Planning,可定制路线规划)算法DEL15是为满足现实道路网络的需求而设计的,例如处理转弯成本和执行成本函数的快速更新。它的预处理有两个阶段。第一阶段计算多层分区和覆盖的拓扑。第二阶段通过自下而上和并行处理单元来计算团边的代价。查询作为覆盖图中的双向搜索进行处理。
3、Hierarchical Techniques
层次技术利用了道路网络固有的层次结构,其中主要道路(如公路)组成一个小的干线子网。一旦源顶点和目标顶点距离较远,查询算法只扫描子网的顶点。预处理阶段根据实际的最短路径结构计算顶点或边的重要性。CH(compression Hierarchies)算法是一种分层技术,它实现了创建快捷方式以跳过重要性较低的顶点的思想。它重复执行顶点压缩操作,如果图中最短路径唯一且包含要压缩的顶点,则从图中删除最不重要的顶点并在每对相邻顶点之间创建快捷方式。CH是通用的,因此可以作为其他点到点算法和扩展查询的构建块。REACH算法是一种分层技术,在预处理阶段计算顶点的中心度度量(REACH值),并在查询阶段使用它们来修剪基于Dijkstra的双向搜索。设P是从源顶点s到包含顶点v的目标顶点t的最短路径。v相对于P的到达值是r(v,P)=min{距离(s,v),距离(v,t)}。
4、Bounded-Hop Techniques
有界跳技术通过向图中添加虚拟快捷方式来预计算顶点对之间的距离。由于预先计算所有顶点对之间的距离对于大型网络是不可行的,因此有界跳技术的目标是在跳数很少的情况下获得任何虚拟路径的长度。
5、算法的结合
可以将各种技术组合到利用不同图形特性的混合算法中。REAL algorithm结合了REACH和ALT。REACH Flags algorithm结合了REACH和Arc标志。SHARC算法[BAU09]将快捷方式的计算与多级弧标志结合起来。CHASE算法[BAU10]结合了CH和Arc标志。TNR+AF算法结合了TNR和Arc标志。PHAST算法可以与多种技术相结合,利用多核cpu和gpu的并行性来加速它们。巴斯特等人。使用众所周知的欧洲大陆大小的基准西欧和现实世界道路网络的简化模型,对这里描述的许多路线规划技术进行了实验性评估。
行为选择
运动规划
运动规划子系统负责计算从自动驾驶汽车的当前状态到行为选择子系统定义的下一个局部目标状态的路径或轨迹。该运动方案执行局部驾驶行为,满足汽车的运动学和动力学约束,为乘客提供舒适性,避免与环境中的静态和移动障碍物发生碰撞。
运动计划可以是路径或轨迹。路径是汽车状态的序列,它不定义汽车状态如何随时间演变。此任务可委托给其他子系统(如行为选择子系统)或速度剖面可定义为曲率和接近障碍物的函数。轨迹是一条指定汽车状态随时间演化的路径。
1、Path Planning
路径规划包括从汽车当前状态到下一个目标状态生成一系列状态,这并不定义汽车状态随时间的演变。路径规划通常分为全局和局部路径规划。在全局路径规划中,在车辆开始移动之前,使用环境的脱机全局地图计算全局路径。在局部路径规划中,当汽车行驶时,利用周围环境的在线局部地图生成局部路径,使汽车能够处理行驶中的障碍物。路径规划的方法主要分为两类:基于图搜索的和基于插值曲线的方法。
2、轨迹规划
轨迹规划包括从自动驾驶汽车的当前状态到下一个目标状态的序列生成,该序列指定汽车状态随时间的演变。轨迹规划方法主要分为四类:基于图搜索的、基于采样的、基于插值曲线的和基于数值优化的方法。
3、Control
第四步、 控制 (执行及整车应用)
高级控制算法
在自动驾驶汽车领域,控制是指工程领域自动控制背后的理论,它涵盖了在没有持续的直接人为干预的情况下,应用各种机制来操作和调节过程。在最简单的自动控制类型中,控制子系统将过程的输出与期望的输入进行比较,并使用误差(过程的输出与期望的输入之间的差异)来改变过程的输入,从而使过程在受到干扰的情况下保持在其设定点。在自主车辆中,自动控制理论一般应用于路径跟踪和硬件驱动方法。路径跟踪方法的作用是在车辆模型存在误差等情况下稳定运动计划的执行。硬件驱动控制的作用是计算在执行器模型和其他模型不准确的情况下执行运动计划的转向、节气门和制动执行器输入。路径跟踪方法也被称为控制技术,因为它们采用自动控制理论,并将路径视为要控制的信号。然而,在自主车辆领域,将其称为路径跟踪方法更为合适,以区别于硬件驱动控制方法。
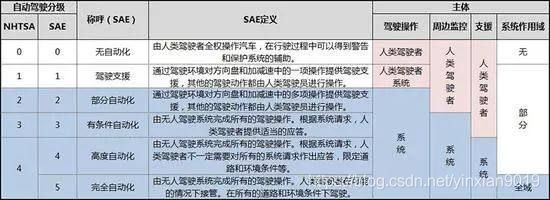
自动驾驶级别 L0 L1 L2 L3 L4 L5
针对自动驾驶的等级划分,目前主要有两个标准,一个是由美国交通部下属的NHSTA(国家高速路安全管理局)所制定,另一个则是由SAE International(国际汽车工程师协会)所制定,其中SAE的标准更为清晰、简洁,所以目前的通行标准是SAE International的标准。
L0:代表没有任何自动驾驶加入的传统人类驾驶,汽车仅仅提出部分警告,如时速、与前车距离、盲区等方面的预警。
L1:方向盘和加减速提供一项自动操作,如自适应巡航或者车道保持等。
L2:方向盘和加减速提供两项自动操作,如自适应巡航+车道保持等。
以上三个级别都需要驾驶者监测环境,并且迅速作出决策,汽车本身仅仅拥有类似于“条件反射”的动作,不带有任何“思考”。
L3:系统自动作出所有驾驶操作,并且可以观察路况(如交通信号灯、行人、路边状况等),并能作出正确决策,但是系统的请求需要驾驶者提供应答。L3级别意味着系统已经有了初步的“思考能力”,大部分时间可以完全自动驾驶,只是需要人类来“保驾护航”,就好比驾校里的学员,已经可以开车上路,但是旁边需要坐着教练。
L4:系统自动作出所有驾驶操作,自主决策,并且驾驶者无需提供应答,但是一般限定其行驶区域,比如公交、物流、出租车等。L4级别意味着车俩可以完全自主上路,无需人类陪同,那么诸如方向盘、油门、刹车之类的装置也就可以取消了。
L5:全域自动驾驶。L5级的自动驾驶车就像我们人类的老司机一样,可以全地域、全天候的自动驾驶,熟练的应对地理、气候等环境的变化。