《零基础入门学习Python》第053讲:论一只爬虫的自我修养
目录
0. 请写下这一节课你学习到的内容:格式不限,回忆并复述是加强记忆的好方式!
测试题
0. 请问 URL 是“统一资源标识符”还是“统一资源定位符”?
1. 什么是爬虫?
2. 设想一下,如果你是负责开发百度蜘蛛的攻城狮,你在设计爬虫时应该特别注意什么问题?
3. 设想一下,如果你是网站的开发者,你应该如何禁止百度爬虫访问你网站中的敏感内容?
4. urllib.request.urlopen() 返回的是什么类型的数据?
5. 如果访问的网址不存在,会产生哪类异常?
6. 鱼C工作室(https://ilovefishc.com)的主页采用什么编码传输的?
7. 为了解决 ASCII 编码的不足,什么编码应运而生?
动动手
0. 下载鱼C工作室首页(https://ilovefishc.com),并打印前三百个字节。
1. 写一个程序,检测指定 URL 的编码。
2. 写一个程序,依次访问文件中指定的站点,并将每个站点返回的内容依次存放到不同的文件中。
0. 请写下这一节课你学习到的内容:格式不限,回忆并复述是加强记忆的好方式!
马上我们的教学就要进入最后一个章节,Pygame 嗨爆引爆全场,但由于发生了一个小插曲,所以这里决定追加一个章节,因为有人反应说:“你上一节课教我们去查找文档,教我们如何从官方文档中找到需要的答案,但是我发现知易行难也,希望举一个详细点的例子,教我们如何去查找。”
所以这里我们详细的深刻的讲一下网络爬虫。所以就有了本章节,论一只爬虫的自我修养。
首先,我们需要理解,什么是网络爬虫,如图:
网络爬虫又称为网络蜘蛛(Spider),如果你把整个互联网想象为一个蜘蛛网的构造,每个网站或域名都是一个节点,那我们这只蜘蛛就是在上面爬来爬去,在不同的网页上爬来爬去,顺便获得我们需要的资源,抓取最有用的。做过网站的朋友一定很熟悉,我们之所以能够通过百度、谷歌这样的搜索引擎检索到你的网页,靠的就是他们每天派出大量的蜘蛛在互联网上爬来爬去,对网页中的每个关键字建立索引,然后建立索引数据库,经过了复杂的排序算法之后,这些结果将按照搜索关键词的相关度的高低展现在我们的眼前。那当然,现在让你编写一个搜索引擎是一件非常苦难的、不可能完成的事情,但是有一句老话说的好啊:千里之行,始于足下。我们先从编写一段小爬虫代码开始,然后不断地来改进它,要使用Python编写爬虫代码,我们要解决的第一个问题是:
Python如何访问互联网?
好在Python为此准备好了电池,Python为此准备的电池叫做:urllib
urllib 事实上是由两个单词组成的:URL(就是我们平时说的网页地址) 和 lib(就是library的意思,就是首页)。
•URL的一般格式为(带方括号[]的为可选项):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
•URL由三部分组成:
–第一部分是协议(protocol):http,https,ftp,file,ed2k…
–第二部分是存放资源的服务器的域名系统或IP地址(有时候要包含端口号,各种传输协议都有默认的端口号,如http的默认端口为80)。
–第三部分是资源的具体地址,如目录或文件名等。
那好,说完URL,我们现在可以来谈一下 urllib 这个模块了,Python 3 其实对这个模块进行了挺大的改动,以前有urllib和urllib2 两个模块,Python3 干脆把它们合并在了一起并做了统一。其实 urllib 并不是一个模块,而是一个包。我们来查一下文档就知道了(我们说过,有问题,找文档。)
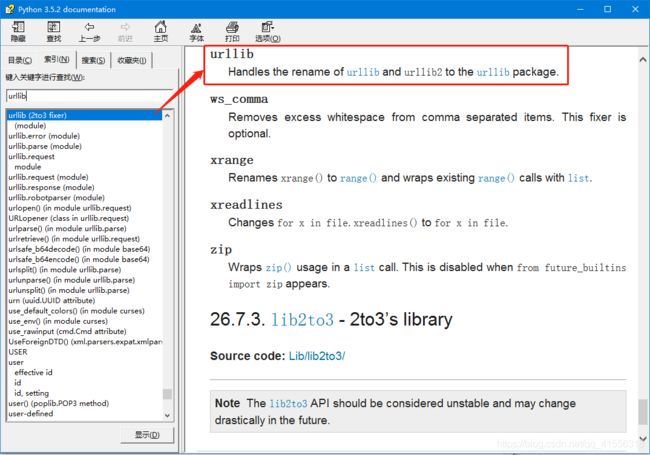
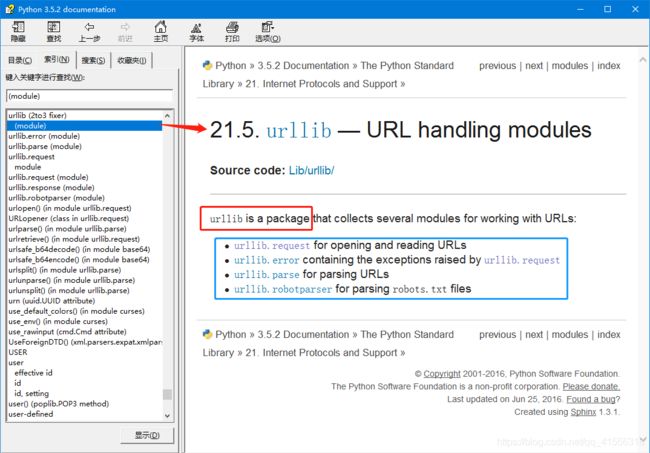
urllib 其实是一个包,其中包含4个模块,request 、error、parse 和 robotparser,我们主要会来讲解 request 这个模块,这个模块也是最复杂的,因为它包含了对服务器的请求和发出、跳转、代理、安全等几大方面。
我们点进去会发现文档非常长,从头看到尾是不可能的,这时候怎么办呢?建议百度、谷歌,查询 urllib.request 的用法,或者查询 Python3 如何访问网页,也可以得到想要的结果。你会得到,使用 urlopen() 这个函数。
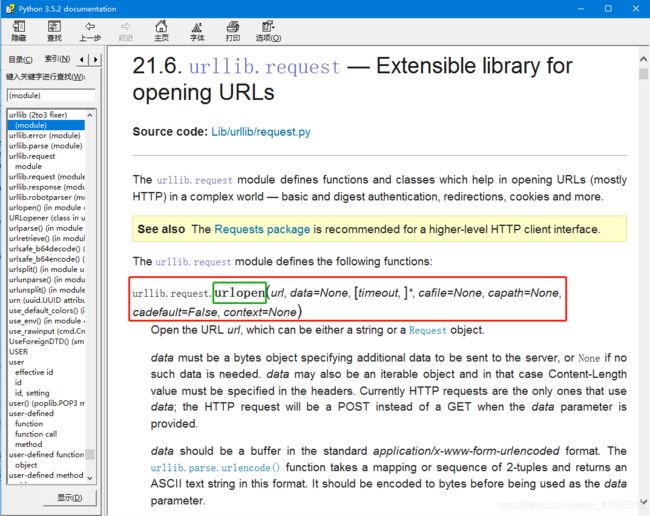
urlopen() 函数除了第一个参数 url 是必需的外,后面的都有默认参数和可选参数,文档告诉我们,url 可以是一个字符串或者 Request object。Request object 是什么,我们下节课讲解。我们猜测 url 为一个字符串是应该就是域名地址的字符串,我们先来尝个鲜:(之所以选择https://ilovefishc.com这个网页,是因为这个网页的源代码量较少,其他的网站会直接把IELD搞崩溃,不信你可以试试 https://www.baidu.com。)
>>> import urllib.request
>>> response = urllib.request.urlopen("https://ilovefishc.com")
>>> html = response.read()
>>> print(html)
b'\n\n\n \n \n \n \n \n \xe9\xb1\xbcC\xe5\xb7\xa5\xe4\xbd\x9c\xe5\xae\xa4-\xe5\x85\x8d\xe8\xb4\xb9\xe7\xbc\x96\xe7\xa8\x8b\xe8\xa7\x86\xe9\xa2\x91\xe6\x95\x99\xe5\xad\xa6|Python\xe6\x95\x99\xe5\xad\xa6|Web\xe5\xbc\x80\xe5\x8f\x91\xe6\x95\x99\xe5\xad\xa6|\xe5\x85\xa8\xe6\xa0\x88\xe5\xbc\x80\xe5\x8f\x91\xe6\x95\x99\xe5\xad\xa6|C\xe8\xaf\xad\xe8\xa8\x80\xe6\x95\x99\xe5\xad\xa6|\xe6\xb1\x87\xe7\xbc\x96\xe6\x95\x99\xe5\xad\xa6|Win32\xe5\xbc\x80\xe5\x8f\x91|\xe5\x8a\xa0\xe5\xaf\x86\xe4\xb8\x8e\xe8\xa7\xa3\xe5\xaf\x86|Linux\xe6\x95\x99\xe5\xad\xa6 \n \n \n \n \n \n \n \n \n\n\n\n\n\n'得到的字符串是一个以 b 开头(二进制)字符串。得到的字符串似乎和我们所理解的网页代码不一样,但是我们又看到了很熟悉的身影(例如:div,link rel等),但是在这个网页,如果右键审查元素
我们会发现网页的代码很整齐,那这是怎么回事呢?为什么Python这里高的一团糟,我们刚才说了,Python这里直接得到的是byte类型(二进制编码),所以我们可以对它进行解码操作,我们先来看一下这个网页的编码方式是:UTF-8。
>>> html = html.decode("utf-8")
>>> print(html)
鱼C工作室-免费编程视频教学|Python教学|Web开发教学|全栈开发教学|C语言教学|汇编教学|Win32开发|加密与解密|Linux教学
测试题
0. 请问 URL 是“统一资源标识符”还是“统一资源定位符”?
答:往后的学习你可能会经常接触 URL 和 URI,为了防止你突然懵倒,所以在这里给大家简单普及下。URI 是统一资源标识符(Universal Resource Identifier),URL 是统一资源定位符(Universal Resource Locator)。用一句话概括它们的区别:URI 是用字符串来标识某一互联网资源,而 URL 则是表示资源的地址(我们说某个网站的网址就是 URL),因此 URI 属于父类,而 URL 属于 URI 的子类。
1. 什么是爬虫?
答:爬虫事实上就是一个程序,用于沿着互联网结点爬行,不断访问不同的网站,以便获取它所需要的资源。
2. 设想一下,如果你是负责开发百度蜘蛛的攻城狮,你在设计爬虫时应该特别注意什么问题?
答:不要重复爬取同一个 URL 的内容。假设你没做这方面的预防,如果一个 URL 的内容中包含该 URL 本身,那么就会陷入无限递归。
3. 设想一下,如果你是网站的开发者,你应该如何禁止百度爬虫访问你网站中的敏感内容?
(课堂上没讲,可以自行百度答案)
答:在网站的根目录下创建并编辑 robots.txt 文件,用于表明您不希望搜索引擎抓取工具访问您网站上的哪些内容。此文件使用的是 Robots 排除标准,该标准是一项协议,所有正规搜索引擎的蜘蛛均会遵循该协议爬取。既然是协议,那就是需要大家自觉尊重,所以该协议一般对非法爬虫无效。
4. urllib.request.urlopen() 返回的是什么类型的数据?
答:返回的是一个HTTPResponse的实例对象,它属于http.client模块。
>>> response = urllib.request.urlopen("http://www.fishc.com")
>>> type(response)
调用其read()方法才能读出URL的内容。
5. 如果访问的网址不存在,会产生哪类异常?
(虽然课堂没讲过,但你可以动手试试)
答:HTTPError
6. 鱼C工作室(https://ilovefishc.com)的主页采用什么编码传输的?
答:UTF-8 编码。
一般网页通过点击审查元素,在
标签中的 charset 会显示采用了哪种编码。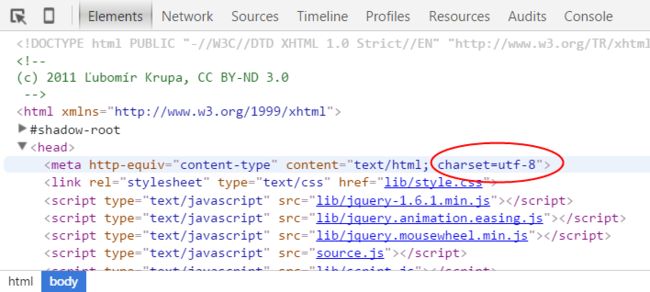
7. 为了解决 ASCII 编码的不足,什么编码应运而生?
答:Unicode 编码。扩展阅读关于编码的那篇文章太长了,有鱼油说太生涩难懂,对于对编码问题还一头雾水的鱼油请看 -> 什么是编码?
动动手
0. 下载鱼C工作室首页(https://ilovefishc.com),并打印前三百个字节。
代码清单:
>>> import urllib.request
>>> response = urllib.request.urlopen('http://www.fishc.com')
>>> print(response.read(300))
b'\r\n\r\n\t\r\n\r\n\r\n\t\r\n\t\t\r\n\t\t'1. 写一个程序,检测指定 URL 的编码。
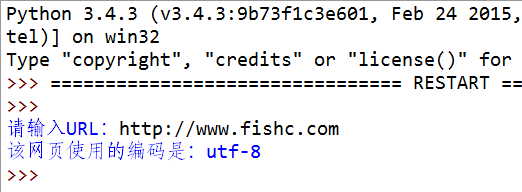
演示:
提示:
提供个“电池”给你用 -> 一次性解决你所有的编码检测问题
代码清单:
import urllib.request
import chardet
def main():
url = input("请输入URL:")
response = urllib.request.urlopen(url)
html = response.read()
# 识别网页编码
encode = chardet.detect(html)['encoding']
if encode == 'GB2312':
encode = 'GBK'
print("该网页使用的编码是:%s" % encode)
if __name__ == "__main__":
main()2. 写一个程序,依次访问文件中指定的站点,并将每个站点返回的内容依次存放到不同的文件中。
演示:
urls.txt 文件存放需要访问的 ULR:
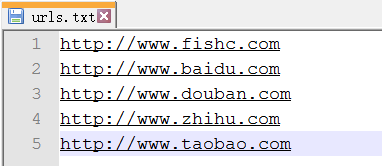
执行你写的程序(test.py),依次访问指定的 URL 并将其内容存放为一个新的文件:
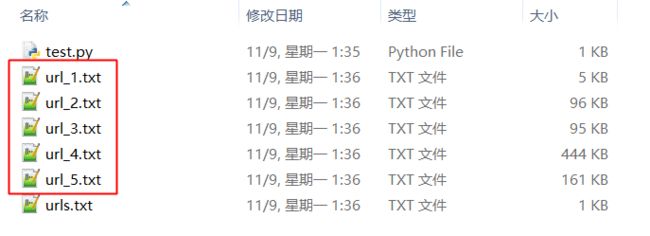
代码清单:
import urllib.request
import chardet
def main():
i = 0
with open("urls.txt", "r") as f:
# 读取待访问的网址
# 由于urls.txt每一行一个URL
# 所以按换行符'\n'分割
urls = f.read().splitlines()
for each_url in urls:
response = urllib.request.urlopen(each_url)
html = response.read()
# 识别网页编码
encode = chardet.detect(html)['encoding']
if encode == 'GB2312':
encode = 'GBK'
i += 1
filename = "url_%d.txt" % i
with open(filename, "w", encoding=encode) as each_file:
each_file.write(html.decode(encode, "ignore"))
if __name__ == "__main__":
main()