python爬取qq音乐
爬取网页版的音乐可以使用抓包工具也可以直接使用谷歌浏览器的开发者调试工具分析地址
下面使用开发者调试工具分析数据
从搜索开始随便输入一个歌曲名到搜索框
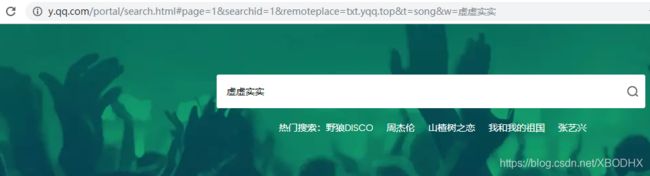
可以看到有很多请求,一般我们需要的都是ajax请求所以切换到XHR选项:

会有很多请求,一般请求以json数据返回
寻找返回的json数据
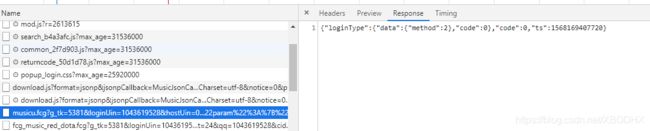
挨个点一下看看response或者preview一般来说返回的json数据都比较多的才能获取到有用的信息,

这条返回的比较长复制链接打开看看
经过分心没有有用的信息,经过一番分析找到了这个链接:https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=70950360097159007&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E8%99%9A%E8%99%9A%E5%AE%9E%E5%AE%9E&g_tk=5381&loginUin=1043619528&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0
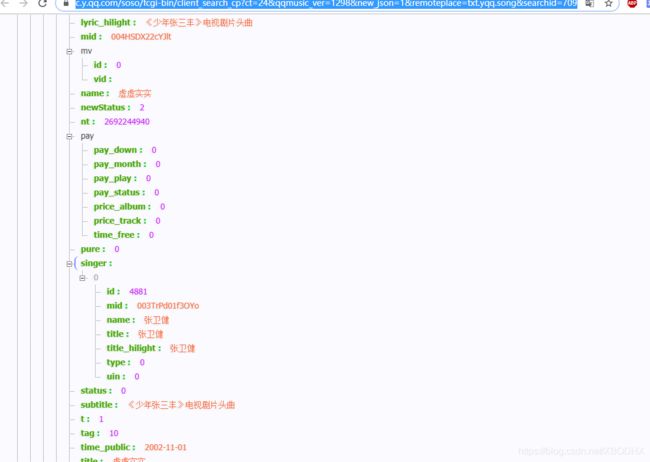
里面有音乐的一些参数正是需要的
来分析下这个链接

其他参数经过尝试都是固定的
打开详细页面
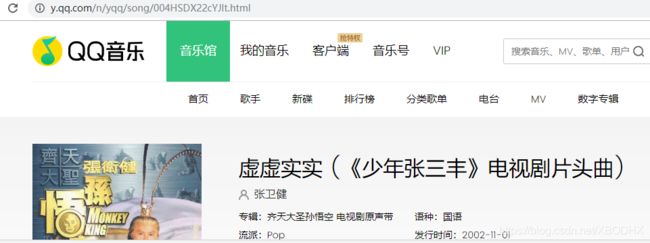
找到如下又有效地址:
歌词地址:https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg?nobase64=1&musicid=110532&-=jsonp1&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0
复制后打开出现如下报错:

试试用python模拟请求看看
可以打开:
![]()
模拟请求代码:
import requests
import ssl
ssl_context = ssl._create_unverified_context
def get_request(url):
header = {
'Connection': "keep-alive",
'Pragma': "no-cache",
'Cache-Control': "no-cache",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/72.0.3626.119 Safari/537.36",
'Accept': "*/*",
'Referer': url,
'Accept-Encoding': "gzip, deflate, sdch, br",
'Accept-Language': "zh-CN,zh;q=0.8",
'cache-control': "no-cache",
}
return requests.get(url, headers=header)
url ='https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg?nobase64=1&musicid=110532&-=jsonp1&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
res = get_request(url)
print(res.text)评论地址:https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=5381&loginUin=1043619528&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=110532&cmd=8&needmusiccrit=0&pagenum=0&pagesize=25&lasthotcommentid=&domain=qq.com&ct=24&cv=10101010

下面开始播放,点击播放就会到播放页面,对播放页面进行分析找到如下地址:
https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey675913044284586&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data=%7B%22req%22%3A%7B%22module%22%3A%22CDN.SrfCdnDispatchServer%22%2C%22method%22%3A%22GetCdnDispatch%22%2C%22param%22%3A%7B%22guid%22%3A%228348972662%22%2C%22calltype%22%3A0%2C%22userip%22%3A%22%22%7D%7D%2C%22req_0%22%3A%7B%22module%22%3A%22vkey.GetVkeyServer%22%2C%22method%22%3A%22CgiGetVkey%22%2C%22param%22%3A%7B%22guid%22%3A%228348972662%22%2C%22songmid%22%3A%5B%22004HSDX22cYJlt%22%5D%2C%22songtype%22%3A%5B0%5D%2C%22uin%22%3A%221043619528%22%2C%22loginflag%22%3A1%2C%22platform%22%3A%2220%22%7D%7D%2C%22comm%22%3A%7B%22uin%22%3A1043619528%2C%22format%22%3A%22json%22%2C%22ct%22%3A24%2C%22cv%22%3A0%7D%7D
数据被url编码了使用站长工具解析一下:
http://tool.chinaz.com/tools/urlencode.aspx
解析后如下:
https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey675913044284586&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"8348972662","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8348972662","songmid":["004HSDX22cYJlt"],"songtype":[0],"uin":"1043619528","loginflag":1,"platform":"20"}},"comm":{"uin":1043619528,"format":"json","ct":24,"cv":0}}
经过分析发现只要获取songmid即可而songmid就是详细页的音乐id编码

所以直接提取这段信息即可
通过搜索得到的信息也有这个信息
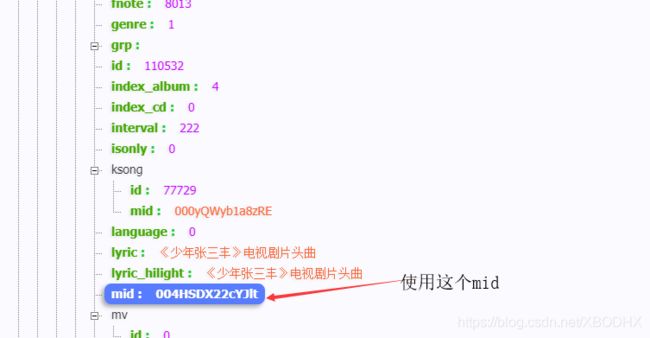
播放地址进过实验发现为sip地址加purl


其他的地址经过测试都不能得到播放地址
请求地址http://ws.stream.qqmusic.qq.com/C40000112DdN4Kn7CA.m4a?guid=8348972662&vkey=D6CAC5EFFC242688DBD0B536E70B4D9129E05E35AA80F85870C196921EA7D1ACB6566301450C67F516D644F20E3843BC8536B4B65A458629&uin=7880&fromtag=66
得到如下播放界面

代码实现如下:
#-*- coding: utf-8 -*-
import requests
import json
import urllib
import sys,os
import re
from bs4 import BeautifulSoup
class Music_tx():
def __init__(self):
self.header = {
'Connection': "keep-alive",
'Pragma': "no-cache",
'Cache-Control': "no-cache",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/72.0.3626.119 Safari/537.36",
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
'Referer': "https://y.qq.com",
'Accept-Encoding': "gzip, deflate, br",
'Accept-Language': "zh-CN,zh;q=0.9",
'cache-control': "no-cache",
}
# 显示下载进度
def _progress(self, block_num, block_size, total_size):
'''回调函数
@block_num: 已经下载的数据块
@block_size: 数据块的大小
@total_size: 远程文件的大小
'''
sys.stdout.write('\r>> 已下载: %.1f%%' % (int(block_num * block_size) / int(total_size) * 100.0))
sys.stdout.flush()
#通过json接口搜索音乐
def search_music(self,keyword,num = 2,page = 1,file_path = None):
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62240638881390953&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p='+str(page)+'&n='+str(num)+'&w='+str(keyword)+'&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
response= requests.get(url, headers=self.header)
music_data = response.text
json_music_data = json.loads(music_data)
music_list = json_music_data['data']['song']['list']
song_mids = []
song_titles = []
song_singers = []
num = 0
if not file_path:
file_path = os.path.dirname(os.path.abspath(__file__)) + '\\'
if not os.path.isdir(file_path + 'mp3'):
os.mkdir(file_path + 'mp3')
file_path = os.path.dirname(os.path.abspath(__file__)) + '\\mp3\\'
for data in music_list:
try:
song_mids.append(data['mid'])
song_titles.append(data['title'])
song_singers.append(data['singer'][0]['name'])
print('正在下载:', data['title'], '......')
get_url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"8348972662","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8348972662","songmid":["'+data['mid']+'"],"songtype":[1],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}'
response = requests.get(get_url)
sip = json.loads(response.text)['req']['data']['sip'][0]
purl = json.loads(response.text)['req_0']['data']['midurlinfo'][0]['purl']
real_url = sip + purl
if os.path.isfile(file_path + data['title']+'-'+ data['singer'][0]['name'] + '.m4a'):
num += 1
path = file_path + data['title'] + '-' + data['singer'][0]['name'] + str(num) + '.m4a'
else:
path = file_path + data['title'] + '-' + data['singer'][0]['name'] + '.m4a'
try:
urllib.request.urlretrieve(real_url,path,reporthook=self._progress)
print('下载' + data['title'] + '成功')
except Exception:
print('下载' +data['title'] + '失败')
print(str(Exception))
except:
print('wrong')
print("下载完成")
#获取播放地址
def get_play_url(self,songid,strMediaMid):
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?&jsonpCallback=MusicJsonCallback&cid=205361747&songmid=' +\
songid+ '&filename=C400' +strMediaMid+ '.m4a&guid=6612300644'
# 获取返回文件并解析得到vkey
response = requests.get(url)
json_data = json.loads(response.text)
vkey = json_data['data']['items'][0]['vkey']
real_url = 'http://isure.stream.qqmusic.qq.com/C400' + strMediaMid + '.m4a?vkey=' + vkey + '&guid=6612300644&uin=0&fromtag=66'
#print(real_url)
return real_url
#通过网址直接下载
def down_music(self,url,file_path = None):
t = re.compile('\w+')
songmid = t.findall(url)[7]
get_url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"8348972662","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8348972662","songmid":["'+songmid+'"],"songtype":[1],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}'
response = requests.get(get_url)
sip = json.loads(response.text)['req']['data']['sip'][0]
purl = json.loads(response.text)['req_0']['data']['midurlinfo'][0]['purl']
real_url = sip + purl
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
title = soup.find('h1', attrs={'class': 'data__name_txt'}).text
singer = (soup.find('div', attrs={'class': 'data__singer'}).text).replace('\n','')
num = 0
if not file_path:
file_path = os.path.dirname(os.path.abspath(__file__)) + '\\'
if not os.path.isdir(file_path + 'mp3'):
os.mkdir(file_path + 'mp3')
file_path = os.path.dirname(os.path.abspath(__file__)) + '\\mp3\\'
if os.path.isfile(file_path + title + '-' + singer + '.m4a'):
num += 1
path = file_path + title + '-' + singer + str(num) + '.m4a'
else:
path = file_path + title + '-' + singer + '.m4a'
try:
urllib.request.urlretrieve(real_url, path, reporthook=self._progress)
print('下载' + title + '成功')
except Exception:
print('下载' + title + '失败')
if __name__ == '__main__':
qq_music = Music_tx()
# url = 'https://y.qq.com/n/yqq/song/0020stYG1RLye8.html'
# qq_music.down_music(url)#通过网址下载
qq_music.search_music('虚虚实实')#通过搜索下载
用到的接口:
搜索接口
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=62240638881390953&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p='+str(page)+'&n='+str(num)+'&w='+str(keyword)+'&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0
播放接口:
https://u.y.qq.com/cgi-bin/musicu.fcg?g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"8348972662","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8348972662","songmid":["'+songmid+'"],"songtype":[1],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}
找到的接口有可能过几天甚至第二天就不能用了这个很正常,只能重新分析
还有一个接口是网上找到的拼接起来有点麻烦下一篇文章分析一下。
下一篇地址:https://blog.csdn.net/XBODHX/article/details/100743772