- 吴恩达深度学习笔记(30)-正则化的解释
极客Array
正则化(Regularization)深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常
- 吴恩达深度学习笔记(24)-为什么要使用深度神经网络?
极客Array
为什么使用深层表示?(Whydeeprepresentations?)我们都知道深度神经网络能解决好多问题,其实并不需要很大的神经网络,但是得有深度,得有比较多的隐藏层,这是为什么呢?我们一起来看几个例子来帮助理解,为什么深度神经网络会很好用。首先,深度网络在计算什么?如果你在建一个人脸识别或是人脸检测系统,深度神经网络所做的事就是,当你输入一张脸部的照片,然后你可以把深度神经网络的第一层,当成一
- 【深度学习笔记】1 数据操作
RIKI_1
深度学习深度学习笔记人工智能
注:本文为《动手学深度学习》开源内容,仅为个人学习记录,无抄袭搬运意图数据操作在深度学习中,我们通常会频繁地对数据进行操作。作为动手学深度学习的基础,本节将介绍如何对内存中的数据进行操作。在PyTorch中,torch.Tensor是存储和变换数据的主要工具。如果你之前用过NumPy,你会发现Tensor和NumPy的多维数组非常类似。然而,Tensor提供GPU计算和自动求梯度等更多功能,这些使
- 【深度学习笔记】6_4 循环神经网络的从零开始实现
RIKI_1
深度学习深度学习笔记rnn
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图6.4循环神经网络的从零开始实现在本节中,我们将从零开始实现一个基于字符级循环神经网络的语言模型,并在周杰伦专辑歌词数据集上训练一个模型来进行歌词创作。首先,我们读取周杰伦专辑歌词数据集:importtimeimportmathimportnumpyasnpimporttorchfromtorchimport
- 【深度学习笔记】6_10 双向循环神经网络bi-rnn
RIKI_1
深度学习深度学习笔记rnn
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图6.10双向循环神经网络之前介绍的循环神经网络模型都是假设当前时间步是由前面的较早时间步的序列决定的,因此它们都将信息通过隐藏状态从前往后传递。有时候,当前时间步也可能由后面时间步决定。例如,当我们写下一个句子时,可能会根据句子后面的词来修改句子前面的用词。双向循环神经网络通过增加从后往前传递信息的隐藏层来更
- 深度学习笔记1:神经网络端到端学习笔记
撒哈拉土狼
深度学习
许多重要问题都可以抽象为变长序列学习问题(sequencetosequencelearning),如语音识别、机器翻译、字符识别。这类问题的特点是,1)输入和输出都是序列(如连续值语音信号/特征、离散值的字符),2)序列长度都不固定,3)并且输入输出序列长度没有对应关系。因此,传统的神经网络模型(DNN,CNN,RNN)不能直接以端到端的方式解决这类问题的建模和学习问题。解决变长序列的端到端学习,
- 吴恩达深度学习-L1 神经网络和深度学习总结
向来痴_
深度学习人工智能
作业地址:吴恩达《深度学习》作业线上版-知乎(zhihu.com)写的很好的笔记:吴恩达《深度学习》笔记汇总-知乎(zhihu.com)我的「吴恩达深度学习笔记」汇总帖(附18个代码实战项目)-知乎(zhihu.com)此处只记录需要注意的点,若想看原笔记请移步。1.1深度学习入门我们只需要管理神经网络的输入和输出,而不用指定中间的特征,也不用理解它们究竟有没有实际意义。1.2简单的神经网络——逻
- 深度学习笔记:推理服务
TaoTao Li
tensorflow深度学习深度学习人工智能机器学习
在线推理服务解决的问题样本处理特征抽取(生成)特征抽取过程特征定义通用定义具体定义特征抽取加速Embeding查询NN计算DL框架计算优化图优化量化优化异构计算CodeGen总结参考资料解决的问题模型训练解决模型效果问题,模型推理解决模型实时预测问题。推理服务是把训练好的模型部署到线上,进行实时预测的过程。如阿里的RTP系统顾名思义,实时预测是相对于非实时预测(离线预测)而言,非实时预测是将训练好
- fast.ai 深度学习笔记(三)
绝不原创的飞龙
人工智能人工智能深度学习笔记
深度学习2:第1部分第6课原文:medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-6-de70d626976c译者:飞龙协议:CCBY-NC-SA4.0来自fast.ai课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢Jeremy和Rachel给了我这个学习的机会。第6课[##2017年深度学习优
- 深度学习笔记
stoAir
深度学习笔记人工智能
DeepLearningBasic神经网络:algorithm1input1outputinput2input3input4algorithm2监督学习:1个x对应1个y;Sigmoid:激活函数sigmoid=11+e−xsigmoid=\frac{1}{1+e^{-x}}sigmoid=1+e−x1ReLU:线性整流函数;##LogisticRegression-->binaryclassif
- fast.ai 深度学习笔记(六)
绝不原创的飞龙
人工智能人工智能python深度学习
深度学习2:第2部分第12课原文:medium.com/@hiromi_suenaga/deep-learning-2-part-2-lesson-12-215dfbf04a94译者:飞龙协议:CCBY-NC-SA4.0来自fast.ai课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢Jeremy和Rachel给了我这个学习的机会。生成对抗网络(GANs)视频
- fast.ai 深度学习笔记(一)
绝不原创的飞龙
人工智能人工智能深度学习笔记
深度学习2:第1部分第1课原文:medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-1-602f73869197译者:飞龙协议:CCBY-NC-SA4.0来自fast.ai课程的个人笔记。随着我继续复习课程以“真正”理解它,这些笔记将继续更新和改进。非常感谢Jeremy和Rachel给了我这个学习的机会。第一课开始[0:00]:为了训练
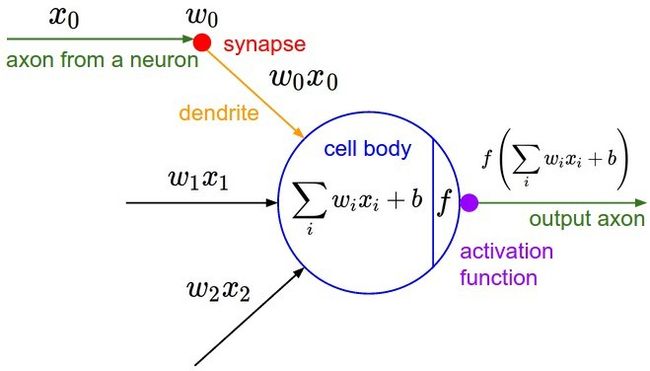
- 吴恩达深度学习笔记(15)-浅层神经网络之神经网络概述
极客Array
神经网络概述(NeuralNetworkOverview)从今天开始你将学习如何实现一个神经网络。这里只是一个概述,详细的在后面会讲解,看不懂也没关系,先有个概念,就是前向计算然后后向计算,理解了这个就可以了,有一些公式和表达在后面会详细的讲解。在我们深入学习具体技术之前,我希望快速的带你预览一下后续几天你将会学到的东西。现在我们开始快速浏览一下如何实现神经网络。之前我们讨论了逻辑回归,我们了解了
- Tensorflow实战深度学习笔记一
独立开发者Lau
人类直观能力----人工智能(自然语言理解、图像识别、语音识别等)。经验----机器学习。训练----特征相关度。特征提取深度学习---自动地将简单的特征组合成更加复杂的特征,并使用这些复杂特征解决问题。深度学习--------不等于模仿人类大脑。
- 吴恩达深度学习笔记(82)-深度卷积神经网络的发展史
极客Array
为什么要探索发展史(实例分析)?我们首先来看看一些卷积神经网络的实例分析,为什么要看这些实例分析呢?上周我们讲了基本构建,比如卷积层、池化层以及全连接层这些组件。事实上,过去几年计算机视觉研究中的大量研究都集中在如何把这些基本构件组合起来,形成有效的卷积神经网络。最直观的方式之一就是去看一些案例,就像很多人通过看别人的代码来学习编程一样,通过研究别人构建有效组件的案例是个不错的办法。实际上在计算机
- 深度学习笔记:灾难性遗忘
UQI-LIUWJ
机器学习笔记
1灾难性遗忘介绍当神经网络被训练去学习新的任务时,它可能会完全忘记如何执行它以前学过的任务。这种现象尤其在所谓的“连续学习”(continuouslearning)或“增量学习”(incrementallearning)场景中很常见2不同视角下看待灾难性遗忘以及对应的解决方法2.1从梯度的视角2.1.1从梯度的视角看灾难性遗忘我们有两个不同任务的损失曲面,用平滑的曲面训练完之后,再在坑坑洼洼的曲面
- 深度学习笔记(九)——tf模型导出保存、模型加载、常用模型导出tflite、权重量化、模型部署
絮沫
深度学习深度学习笔记人工智能
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。本篇博客主要是工具性介绍,可能由于软件版本问题导致的部分内容无法使用。首先介绍tflite:TensorFlowLite是一组工具,可帮助开发者在移动设备、嵌入式设备和loT设备上运行模型,以便实现设备端机器学习。框架具有的主要特性:延时(数据无需往返服务器)隐私(没有任何个人数据离开设备)
- 深度学习笔记(八)——构建网络的常用辅助增强方法:数据增强扩充、断点续训、可视化和部署预测
絮沫
深度学习深度学习笔记人工智能
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。截图和程序部分引用自北京大学机器学习公开课要构建一个完善可用的神经网络,除了设计网络结构以外,还需要添加一些辅助代码来增强网络运行的稳定性,鲁棒性。可以用来增强的方向主要有个,首先是数据输入前的预处理环节,其次是数据在训练过程中的优化,最后的数据在训练结束后的导出和可视化,同时能够及时保存结
- 深度学习笔记(七)——基于Iris/MNIST数据集构建基础的分类网络算法实战
絮沫
深度学习算法深度学习笔记
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。截图和程序部分引用自北京大学机器学习公开课认识网络的构建结构在神经网络的构建过程中,都避不开以下几个步骤:导入网络和依赖模块原始数据处理和清洗加载训练和测试数据构建网络结构,确定网络优化方法将数据送入网络进行训练,同时判断预测效果保存模型部署算法,使用新的数据进行预测推理使用Keras快速构
- 《动手学深度学习》学习笔记 第10章 注意力机制
北方骑马的萝卜
《手动深度学习》笔记深度学习学习笔记
本系列为《动手学深度学习》学习笔记书籍链接:动手学深度学习笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看关于本系列笔记:书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很多,笔记只保留主要内容,同时也是对之前知识的查漏补缺《动手学深度学习》学习笔记第4章多层感知机《动手学深度学习》学习笔记第5章深度学习计算《动手学深度学习》学习笔记第6章卷积神经网络《动手学深度学习》学习笔记
- 深度学习笔记(六)——网络优化(2):参数更新优化器SGD、SGDM、AdaGrad、RMSProp、Adam
絮沫
深度学习深度学习笔记人工智能
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。截图和程序部分引用自北京大学机器学习公开课前言在前面的博文中已经学习了构建神经网络的基础需求,搭建了一个简单的双层网络结构来实现数据的分类。并且了解了激活函数和损失函数在神经网络中发挥的重要用途,其中,激活函数优化了神经元的输出能力,损失函数优化了反向传播时参数更新的趋势。我们知道在简单的反
- 李沐—动手学深度学习笔记
比三毛多一根头发
笔记
目录引言1.2机器学习中的关键组件1.3.1监督学习2.预备知识2.1数据操作2.1.3.广播机制2.1.4.索引和切片2.1.5.节省内存2.1.6.转换为其他Python对象2.2.数据预处理2.2.1.读取数据集2.2.2.处理缺失值2.2.3.转换为张量格式2.3.线性代数2.3.2.向量2.3.5.张量算法的基本性质2.3.6.降维3.线性神经网络4.多层感知机4.1多层感知机4.1.1
- 深度学习笔记(四)——使用TF2构建基础网络的常用函数+简单ML分类实现
絮沫
深度学习深度学习笔记分类
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。截图和程序部分引用自北京大学机器学习公开课TF2基础常用函数1、张量处理类强制数据类型转换:a1=tf.constant([1,2,3],dtype=tf.float64)print(a1)a2=tf.cast(a1,tf.int64)#强制数据类型转换print(a2)查找数据中的最小值和
- 深度学习笔记(三)——NN网络基础概念(神经元模型,梯度下降,反向传播,张量处理)
絮沫
深度学习深度学习笔记网络
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。截图部分引用自北京大学机器学习公开课人工智能算法的主流分类首先明白一个概念,广义上的人工智能算法并不是只有MachineLearning或DeepLearning,而是一个相对的,能够使用计算机模拟人类智能在一定场景下自动实现一些功能。所以系统控制论中的很多最优控制算法同样可以称之为智能算法
- 深度学习笔记(五)——网络优化(1):学习率自调整、激活函数、损失函数、正则化
絮沫
深度学习深度学习笔记网络tensorflow
文中程序以Tensorflow-2.6.0为例部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。截图和程序部分引用自北京大学机器学习公开课通过学习已经掌握了主要的基础函数之后具备了搭建一个网络并使其正常运行的能力,那下一步我们还需要进一步对网络中的重要节点进行优化并加深认知。首先我们知道NN(自然神经)网络算法能够相比传统建模类算法发挥更好效果的原因是网络对复杂非线性函数的拟合效果更好
- 《动手学深度学习》学习笔记 第9章 现代循环神经网络
北方骑马的萝卜
《手动深度学习》笔记深度学习学习笔记
本系列为《动手学深度学习》学习笔记书籍链接:动手学深度学习笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看关于本系列笔记:书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很多,笔记只保留主要内容,同时也是对之前知识的查漏补缺9.现代循环神经网络 前一章中我们介绍了循环神经网络的基础知识,这种网络可以更好地处理序列数据。我们在文本数据上实现了基于循环神经网络的语言模型,但是对于
- 《动手学深度学习》学习笔记 第8章 循环神经网络
北方骑马的萝卜
《手动深度学习》笔记深度学习学习笔记
本系列为《动手学深度学习》学习笔记书籍链接:动手学深度学习笔记是从第四章开始,前面三章为基础知识,有需要的可以自己去看看关于本系列笔记:书里为了让读者更好的理解,有大篇幅的描述性的文字,内容很多,笔记只保留主要内容,同时也是对之前知识的查漏补缺8.循环神经网络 到目前为止我们默认数据都来自于某种分布,并且所有样本都是独立同分布的(independentlyandidenticallydistri
- 深度学习笔记(二)——Tensorflow环境的安装
絮沫
深度学习深度学习笔记tensorflow
本篇文章只做基本的流程概述,不阐述具体每个软件的详细安装流程,具体的流程网上教程已经非常丰富。主要是给出完整的安装流程,以供参考环境很重要一个好的算法环境往往能够帮助开发者事半功倍,入门学习的时候往往搭建好环境就已经成功了一半。在机器学习或者深度学习的设计研究中,人们往往会使用已经有的网络框架来构建网络模型和设计各种识别分类或者生成算法。主要可以给我们学习和使用的框架这里推荐两个:Tensorfl
- 2022-01-23 深度学习笔记
Luo_淳
专业学习深度学习人工智能
深度学习笔记引言:机器学习——自动寻找函数。1.你想要找什么函数?①Regression——Theoutputofthefunctionisascalar.②BinaryClassification——OnlyoutputYesorNo.举例:输入句子,输出句子positive还是negtive。③Multi-classClassification——分类,输入图片,输出图片中物品的类型。
- 深度学习笔记:下载鸢尾花数据集,并展示所有的属性
BioVS
pythontensorflownumpy
背景:深度学习课程作业。通过此作业,可了解tensorflow、matplotlib、pandas和numpy。可学习到matplot画图及细节设计,如图的颜色、字体大小、循环画图方法等代码:importtensorflowastfimportmatplotlib.pyplotaspltimportpandasaspdimportnumpyasnpTRAIN_URL="http://downloa
- tomcat基础与部署发布
暗黑小菠萝
Tomcat java web
从51cto搬家了,以后会更新在这里方便自己查看。
做项目一直用tomcat,都是配置到eclipse中使用,这几天有时间整理一下使用心得,有一些自己配置遇到的细节问题。
Tomcat:一个Servlets和JSP页面的容器,以提供网站服务。
一、Tomcat安装
安装方式:①运行.exe安装包
&n
- 网站架构发展的过程
ayaoxinchao
数据库应用服务器网站架构
1.初始阶段网站架构:应用程序、数据库、文件等资源在同一个服务器上
2.应用服务和数据服务分离:应用服务器、数据库服务器、文件服务器
3.使用缓存改善网站性能:为应用服务器提供本地缓存,但受限于应用服务器的内存容量,可以使用专门的缓存服务器,提供分布式缓存服务器架构
4.使用应用服务器集群改善网站的并发处理能力:使用负载均衡调度服务器,将来自客户端浏览器的访问请求分发到应用服务器集群中的任何
- [信息与安全]数据库的备份问题
comsci
数据库
如果你们建设的信息系统是采用中心-分支的模式,那么这里有一个问题
如果你的数据来自中心数据库,那么中心数据库如果出现故障,你的分支机构的数据如何保证安全呢?
是否应该在这种信息系统结构的基础上进行改造,容许分支机构的信息系统也备份一个中心数据库的文件呢?
&n
- 使用maven tomcat plugin插件debug关联源代码
商人shang
mavendebug查看源码tomcat-plugin
*首先需要配置好'''maven-tomcat7-plugin''',参见[[Maven开发Web项目]]的'''Tomcat'''部分。
*配置好后,在[[Eclipse]]中打开'''Debug Configurations'''界面,在'''Maven Build'''项下新建当前工程的调试。在'''Main'''选项卡中点击'''Browse Workspace...'''选择需要开发的
- 大访问量高并发
oloz
大访问量高并发
大访问量高并发的网站主要压力还是在于数据库的操作上,尽量避免频繁的请求数据库。下面简
要列出几点解决方案:
01、优化你的代码和查询语句,合理使用索引
02、使用缓存技术例如memcache、ecache将不经常变化的数据放入缓存之中
03、采用服务器集群、负载均衡分担大访问量高并发压力
04、数据读写分离
05、合理选用框架,合理架构(推荐分布式架构)。
- cache 服务器
小猪猪08
cache
Cache 即高速缓存.那么cache是怎么样提高系统性能与运行速度呢?是不是在任何情况下用cache都能提高性能?是不是cache用的越多就越好呢?我在近期开发的项目中有所体会,写下来当作总结也希望能跟大家一起探讨探讨,有错误的地方希望大家批评指正。
1.Cache 是怎么样工作的?
Cache 是分配在服务器上
- mysql存储过程
香水浓
mysql
Description:插入大量测试数据
use xmpl;
drop procedure if exists mockup_test_data_sp;
create procedure mockup_test_data_sp(
in number_of_records int
)
begin
declare cnt int;
declare name varch
- CSS的class、id、css文件名的常用命名规则
agevs
JavaScriptUI框架Ajaxcss
CSS的class、id、css文件名的常用命名规则
(一)常用的CSS命名规则
头:header
内容:content/container
尾:footer
导航:nav
侧栏:sidebar
栏目:column
页面外围控制整体布局宽度:wrapper
左右中:left right
- 全局数据源
AILIKES
javatomcatmysqljdbcJNDI
实验目的:为了研究两个项目同时访问一个全局数据源的时候是创建了一个数据源对象,还是创建了两个数据源对象。
1:将diuid和mysql驱动包(druid-1.0.2.jar和mysql-connector-java-5.1.15.jar)copy至%TOMCAT_HOME%/lib下;2:配置数据源,将JNDI在%TOMCAT_HOME%/conf/context.xml中配置好,格式如下:&l
- MYSQL的随机查询的实现方法
baalwolf
mysql
MYSQL的随机抽取实现方法。举个例子,要从tablename表中随机提取一条记录,大家一般的写法就是:SELECT * FROM tablename ORDER BY RAND() LIMIT 1。但是,后来我查了一下MYSQL的官方手册,里面针对RAND()的提示大概意思就是,在ORDER BY从句里面不能使用RAND()函数,因为这样会导致数据列被多次扫描。但是在MYSQL 3.23版本中,
- JAVA的getBytes()方法
bijian1013
javaeclipseunixOS
在Java中,String的getBytes()方法是得到一个操作系统默认的编码格式的字节数组。这个表示在不同OS下,返回的东西不一样!
String.getBytes(String decode)方法会根据指定的decode编码返回某字符串在该编码下的byte数组表示,如:
byte[] b_gbk = "
- AngularJS中操作Cookies
bijian1013
JavaScriptAngularJSCookies
如果你的应用足够大、足够复杂,那么你很快就会遇到这样一咱种情况:你需要在客户端存储一些状态信息,这些状态信息是跨session(会话)的。你可能还记得利用document.cookie接口直接操作纯文本cookie的痛苦经历。
幸运的是,这种方式已经一去不复返了,在所有现代浏览器中几乎
- [Maven学习笔记五]Maven聚合和继承特性
bit1129
maven
Maven聚合
在实际的项目中,一个项目通常会划分为多个模块,为了说明问题,以用户登陆这个小web应用为例。通常一个web应用分为三个模块:
1. 模型和数据持久化层user-core,
2. 业务逻辑层user-service以
3. web展现层user-web,
user-service依赖于user-core
user-web依赖于user-core和use
- 【JVM七】JVM知识点总结
bit1129
jvm
1. JVM运行模式
1.1 JVM运行时分为-server和-client两种模式,在32位机器上只有client模式的JVM。通常,64位的JVM默认都是使用server模式,因为server模式的JVM虽然启动慢点,但是,在运行过程,JVM会尽可能的进行优化
1.2 JVM分为三种字节码解释执行方式:mixed mode, interpret mode以及compiler
- linux下查看nginx、apache、mysql、php的编译参数
ronin47
在linux平台下的应用,最流行的莫过于nginx、apache、mysql、php几个。而这几个常用的应用,在手工编译完以后,在其他一些情况下(如:新增模块),往往想要查看当初都使用了那些参数进行的编译。这时候就可以利用以下方法查看。
1、nginx
[root@361way ~]# /App/nginx/sbin/nginx -V
nginx: nginx version: nginx/
- unity中运用Resources.Load的方法?
brotherlamp
unity视频unity资料unity自学unityunity教程
问:unity中运用Resources.Load的方法?
答:Resources.Load是unity本地动态加载资本所用的方法,也即是你想动态加载的时分才用到它,比方枪弹,特效,某些实时替换的图像什么的,主张此文件夹不要放太多东西,在打包的时分,它会独自把里边的一切东西都会集打包到一同,不论里边有没有你用的东西,所以大多数资本应该是自个建文件放置
1、unity实时替换的物体即是依据环境条件
- 线段树-入门
bylijinnan
java算法线段树
/**
* 线段树入门
* 问题:已知线段[2,5] [4,6] [0,7];求点2,4,7分别出现了多少次
* 以下代码建立的线段树用链表来保存,且树的叶子结点类似[i,i]
*
* 参考链接:http://hi.baidu.com/semluhiigubbqvq/item/be736a33a8864789f4e4ad18
* @author lijinna
- 全选与反选
chicony
全选
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title>全选与反选</title>
- vim一些简单记录
chenchao051
vim
mac在/usr/share/vim/vimrc linux在/etc/vimrc
1、问:后退键不能删除数据,不能往后退怎么办?
答:在vimrc中加入set backspace=2
2、问:如何控制tab键的缩进?
答:在vimrc中加入set tabstop=4 (任何
- Sublime Text 快捷键
daizj
快捷键sublime
[size=large][/size]Sublime Text快捷键:Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+Shift+W:关闭所有打开文件Ctrl+Shift+V:粘贴并格式化Ctrl+D:选择单词,重复可增加选择下一个相同的单词Ctrl+L:选择行,重复可依次增加选择下一行Ctrl+Shift+L:
- php 引用(&)详解
dcj3sjt126com
PHP
在PHP 中引用的意思是:不同的名字访问同一个变量内容. 与C语言中的指针是有差别的.C语言中的指针里面存储的是变量的内容在内存中存放的地址 变量的引用 PHP 的引用允许你用两个变量来指向同一个内容 复制代码代码如下:
<?
$a="ABC";
$b =&$a;
echo
- SVN中trunk,branches,tags用法详解
dcj3sjt126com
SVN
Subversion有一个很标准的目录结构,是这样的。比如项目是proj,svn地址为svn://proj/,那么标准的svn布局是svn://proj/|+-trunk+-branches+-tags这是一个标准的布局,trunk为主开发目录,branches为分支开发目录,tags为tag存档目录(不允许修改)。但是具体这几个目录应该如何使用,svn并没有明确的规范,更多的还是用户自己的习惯。
- 对软件设计的思考
e200702084
设计模式数据结构算法ssh活动
软件设计的宏观与微观
软件开发是一种高智商的开发活动。一个优秀的软件设计人员不仅要从宏观上把握软件之间的开发,也要从微观上把握软件之间的开发。宏观上,可以应用面向对象设计,采用流行的SSH架构,采用web层,业务逻辑层,持久层分层架构。采用设计模式提供系统的健壮性和可维护性。微观上,对于一个类,甚至方法的调用,从计算机的角度模拟程序的运行情况。了解内存分配,参数传
- 同步、异步、阻塞、非阻塞
geeksun
非阻塞
同步、异步、阻塞、非阻塞这几个概念有时有点混淆,在此文试图解释一下。
同步:发出方法调用后,当没有返回结果,当前线程会一直在等待(阻塞)状态。
场景:打电话,营业厅窗口办业务、B/S架构的http请求-响应模式。
异步:方法调用后不立即返回结果,调用结果通过状态、通知或回调通知方法调用者或接收者。异步方法调用后,当前线程不会阻塞,会继续执行其他任务。
实现:
- Reverse SSH Tunnel 反向打洞實錄
hongtoushizi
ssh
實際的操作步驟:
# 首先,在客戶那理的機器下指令連回我們自己的 Server,並設定自己 Server 上的 12345 port 會對應到幾器上的 SSH port
ssh -NfR 12345:localhost:22
[email protected]
# 然後在 myhost 的機器上連自己的 12345 port,就可以連回在客戶那的機器
ssh localhost -p 1
- Hibernate中的缓存
Josh_Persistence
一级缓存Hiberante缓存查询缓存二级缓存
Hibernate中的缓存
一、Hiberante中常见的三大缓存:一级缓存,二级缓存和查询缓存。
Hibernate中提供了两级Cache,第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存是由hibernate管理的,一般情况下无需进行干预;第二级别的缓存是SessionFactory级别的缓存,它是属于进程范围或群集范围的缓存。这一级别的缓存
- 对象关系行为模式之延迟加载
home198979
PHP架构延迟加载
形象化设计模式实战 HELLO!架构
一、概念
Lazy Load:一个对象,它虽然不包含所需要的所有数据,但是知道怎么获取这些数据。
延迟加载貌似很简单,就是在数据需要时再从数据库获取,减少数据库的消耗。但这其中还是有不少技巧的。
二、实现延迟加载
实现Lazy Load主要有四种方法:延迟初始化、虚
- xml 验证
pengfeicao521
xmlxml解析
有些字符,xml不能识别,用jdom或者dom4j解析的时候就报错
public static void testPattern() {
// 含有非法字符的串
String str = "Jamey친ÑԂ
- div设置半透明效果
spjich
css半透明
为div设置如下样式:
div{filter:alpha(Opacity=80);-moz-opacity:0.5;opacity: 0.5;}
说明:
1、filter:对win IE设置半透明滤镜效果,filter:alpha(Opacity=80)代表该对象80%半透明,火狐浏览器不认2、-moz-opaci
- 你真的了解单例模式么?
w574240966
java单例设计模式jvm
单例模式,很多初学者认为单例模式很简单,并且认为自己已经掌握了这种设计模式。但事实上,你真的了解单例模式了么。
一,单例模式的5中写法。(回字的四种写法,哈哈。)
1,懒汉式
(1)线程不安全的懒汉式
public cla