顺序表、链表(单、单循环、双循环)的C语言实现
这篇博客主要是对顺序表和带头节点链表的实现(单链表、单循环链表、双循环链表)。
不带头节点的链表最后面也会附上代码。
一、顺序表:顺序表是使用一块物理地址连续的存储单元存储数据元素的线性结构。比如常用的数组。
1. 顺序表的定义
typedef struct Seqlist
{
size_t size;//计数
size_t capacity;//容量
ElementType *base;//数据类型,ElementType=int 这里进行宏替换是为了方便存储不同的数据时,只需要更改宏即可
}Seqlist;
2. 顺序表的初始化
void SeqlistInit(Seqlist *plist)
{
assert(plist != NULL);
plist->capacity = SEQNUMBER;//容量的大小,使用宏
plist->size = 0;
plist->base = (ElementType *)malloc(sizeof(ElementType)*SEQNUMBER);
}
3. 顺序表的增:头插,尾插,位置插入,值插入
void SeqlistPushFront(Seqlist *plist, ElementType x)//头插
{
assert(plist != NULL);
if (IsFull(plist))//这里调用了一个是否为满的函数,直接判断size和capacity是否相等即可
{
printf("顺序表已满,%d不能插入\n", x);
return;
}
for (size_t i = plist->size; i > 0; i--)//方法画图讲解
{
plist->base[i] = plist->base[i - 1];
}
plist->base[0] = x;//头插,放到最前面
plist->size++;//插入后计数要增加
}
void SeqlistPushBack(Seqlist *plist, ElementType x)//尾插
{
assert(plist != NULL);
if (IsFull(plist) && !SeqlistInc(plist))
{
printf("顺序表已满,%d不能插入\n", x);
return;
}
plist->base[plist->size] = x;//直接插入即可
plist->size++;//插入后计数要增加
}
void SeqlistInsertPos(Seqlist *plist, int pos, ElementType x)//位置插入
{
assert(plist != NULL);
if (IsFull(plist))//满了不能插入
{
printf("顺序表已满,%d不能插入\n", x);
return;
}
if ( pos<0 || pos>(int)plist->size)//位置有误,顺序表前面都为空,不能前面为空(第一个除外)的地方插,要连续着
{
printf("输入的位置%d非法,%d不能插入\n",pos,x);
return;
}
for (size_t i = plist->size; i > (size_t) pos; i--)//位置正确,插入
{
plist->base[i] = plist->base[i - 1];
}
plist->base[pos] = x;
plist->size++;
}
void SeqlistInsertVal(Seqlist *plist, ElementType x)//值插入,插入前先排序
{
assert(plist != NULL);
qsort(plist->base, plist->size, sizeof(ElementType), cmp);//这里使用了库函数 ,qsort
if (IsFull(plist) && !SeqlistInc(plist))
{
printf("顺序表已满,%d不能插入\n", x);
return;
}
size_t end = plist->size - 1;
while (end >= 0 && x < plist->base[end])
{
plist->base[end + 1] = plist->base[end];
end--;
}
plist->base[end + 1] = x;
plist->size++;
}

顺序表插入这块:基本上的思想是,数据往后走,最后在插入的地方进行值覆盖。
4 .顺序表的删:头删,尾删,位置删除
void SeqlistPopFront(Seqlist *plist)//头删
{
assert(plist != NULL);
if (IsEmpty(plist))
{
printf("数据为空,无法删除\n");
return;
}
for (size_t i = 0; i < plist->size; i++)
{
plist->base[i] = plist->base[i + 1];//后面的数据往前覆盖
}
plist->size--;//元素个数减小
}
void SeqlistPopBack(Seqlist *plist)//尾删
{
assert(plist != NULL);
if (IsEmpty(plist))
{
printf("数据为空,无法删除\n");
return;
}
plist->size--;//直接个数减小,将最后一个位置设置为无效
}
void SeqlistEraseBack(Seqlist *plist, int pos)//位置删除
{
assert(plist != NULL);
if (IsEmpty(plist))
{
printf("顺序表为空,不能删除!\n");
return;
}
if (pos < 0 || pos > (int)plist->size)
{
printf("输入的位置%d非法,不能删除\n",pos);
return;
}
for (size_t i = (size_t)pos; i < plist->size ; i++)
{
plist->base[i] = plist->base[i + 1];//后面数据往前覆盖
}
plist->size--;//元素个数减小
}
顺序表的删除这块:基本思想是,将后面的数据挨个往前覆盖,最后再个数减少。
5.顺序表的查:位置查找、二分查找
int SeqlistFind(Seqlist *plist, ElementType x)//位置查找
{
assert(plist != NULL);
if (IsEmpty(plist))
{
printf("数据为空,无法查找!\n");
}
size_t pos = 0;
while (pos < plist->size && x != plist->base[pos])//位置要合法,数据不等于就继续执行
{
pos++;
}
if (pos == plist->size)//跳出后,若是因为位置不合法,则一定是数据不存在
{
return -1;
}
return pos;//数据找到了,返回位置
}
void SeqlistBinaryFind(Seqlist *plist, ElementType x)
{
assert(plist != NULL);
size_t start = 0;
size_t end = plist->size;
size_t mid = 0;
while (start <= end)//二分查找
{
mid = (start + end) / 2;
if (x < plist->base[mid])//比中间小,往左走,end变为mid-1
{
end = mid - 1;
}
else if (x > plist->base[mid])//比中间大,往右走,start变为mid+1
{
start = mid + 1;
}
else//找到了
{
printf("数据查找成功,为:>%d\n", plist->base[mid]);
return;
}
}
printf("查找失败,数据%d不存在\n", x);//跳出循环,就是数据不存在
}
5.顺序表的排序:顺序表是连续的空间,可以直接值交换的方法进行排序
void SeqlistSort(Seqlist *plist)//数据排序,这里使用qsort
{
assert(plist != NULL);
if (IsEmpty(plist))
{
printf("数据为空,无法排序!\n");
}
qsort(plist->base, plist->size, sizeof(ElementType), cmp);//直接使用qsort库函数
}
//qsort需要自己写一个比较函数,作为参数传为qsort
int cmp(const void *a, const void *b)
{
return *(ElementType *)a - *(ElementType *)b;
}
这里也可以使用冒泡的方法,比较交换。
6.顺序表的逆置:顺序表反向
void SeqlistReverse(Seqlist *plist)//数据倒序
{
assert(plist != NULL);
size_t start = 0;
size_t end = plist->size - 1;
while (start < end)//每一位进行值交换
{
plist->base[end] ^= plist->base[start];
plist->base[start] ^= plist->base[end];
plist->base[end] ^= plist->base[start];
start++, end--;
}
}
数据进行异或会交换比特位,就可以达到交换数据的效果。
比如:

7.删除顺序表中重复的元素
//比如:1 2 2 2 2 3 3 3 4
void SeqlistEraseAll(Seqlist *plist,ElementType x)//删除指定元素
{
assert(plist != NULL);
if (plist->size <= 0)
{
return;
}
SeqlistSort(plist);//排序
size_t pos = SeqlistFind(plist, x);//找到第一个出现的位置
size_t count = 0;//计数有多少个
int tmp = 0;
for (size_t i = pos; i < plist->size; i++)
{
tmp = 1;//标志位
if (x == plist->base[i])
{
tmp = 0;
count++;
}
if (tmp == 1)
{
break;//走到这,说明已经没有相等了,进行跳出
}
}
tmp = count;//保留个数
int number = count + pos;//记住要开始替换的位置
for (; count > 0; count--)
{
plist->base[pos++] = plist->base[number++];//后面的数据往前面覆盖
}
plist->base[pos-1] = plist->base[number-1];//循环做完,会少替换一次
plist->size -= tmp;
}
顺序表的优点:
- 易于实现
- 可以随机访问
如果我们需要的空间大于我们的容量怎么办?
可以使用动态开辟的方式,重新开辟空间,比如:
bool SeqlistInc(Seqlist *plist)//扩容
{
assert(plist != NULL);
ElementType *s = (ElementType *)realloc(plist->base, 2 * plist->capacity * sizeof(ElementType));
if (NULL != s)
{
plist->base = s;
plist->capacity = 2 * plist->capacity;
return true;
}
return false;
}
但是也会有缺点,动态开辟的时候,空间是以二倍的形式增长的,如果仅仅只需要超出一个原空间的容量,就造成了很大的空间浪费。
二、单链表:链表是一种物理存储结构上不连续,非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
下面实现的带头节点的单链表
1.单链表的定义:
typedef struct SlistNode
{
ElementType data;//数据
struct SlistNode *next;//指向下一个的指针
}SlistNode;
2.单链表的初始化:
void SlistIniHead(SList *phead)
{
assert(phead != NULL);
(*phead) = (SlistNode*)malloc(sizeof(SlistNode));//带有头节点,头节点不放数据,不能更改
(*phead)->next = NULL;
}
3.单链表的增:头插,尾插,值插入
void SlistHeadPushFront(SList *phead, ElementType x)//有头节点,头插
{
assert(phead != NULL);
SlistNode *p = (SlistNode *)malloc(sizeof(SlistNode));//申请空间
assert(p != NULL);
p->data = x;
SlistNode *q = *phead;
p->next = q->next;//p的下一个为头的下一个节点
q->next = p;//头的下一个为p
}
void SlistHeadPushBack(SList *phead, ElementType x)//有头节点,尾插
{
assert(phead != NULL);
SlistNode *q = *phead;
while (q->next != NULL)//找到最后一个节点
{
q = q->next;
}
SlistNode *p = (SlistNode *)malloc(sizeof(SlistNode));
p->data = x;
p->next = NULL;//尾部为空
q->next = p;//前面节点指向p
}
void SlistHeadInsertVal(SList *phead, ElementType x)//值插入
{
assert(phead != NULL);
SlistHeadSort(phead);//先排序
SlistNode *p = (SlistNode *)malloc(sizeof(SlistNode));
assert(p != NULL);
p->data = x;
SlistNode *q = (*phead)->next,*prev = NULL;
while (q != NULL && q->data < x)//寻找插入的位置
{
prev = q;//前驱节点
q = q->next;
}
if (prev == NULL)
{
p->next = (*phead)->next;
(*phead)->next = p;
}
else
{
p->next = prev->next;
prev->next = p;
}
}
在值插入这块,因为链表不支持随机访问,所以不能进行位置的插入。
4.单链表的删:头删,尾删,值删
void SlistHeadPopFront(SList *phead)
{
assert(phead != NULL);
if ((*phead)->next == NULL)//链表为空,不能删除
{
return;
}
SlistNode *p = (*phead)->next;//删除头节点的下一个并且指向第一个节点的next
(*phead)->next = p->next;
free(p);//释放,因为链表的节点都是malloc开辟的,所有需要释放
}
void SlistHeadPopBack(SList *phead)//尾删
{
assert(phead != NULL);
if ((*phead)->next == NULL)//链表为空,不能删除
{
return;
}
SlistNode *p = (*phead)->next;
SlistNode *prev = NULL;//前驱
while (p->next != NULL)
{
prev = p;
p = p->next;
}
prev->next = NULL;//前驱的下一个置空
free(p);//释放尾节点
}
void SlistHeadEraseVal(SList *phead, ElementType x)//值删
{
assert(phead != NULL);
SlistNode *p = SlistHeadFind(phead, x);//找到删除值的位置
if (p == NULL)
{
printf("数据不存在,无法删除!\n");
return;
}
SlistNode *q = (*phead)->next,*prev;
if (q == p)//第一个节点就为释放的节点,改变头节点的指向
{
(*phead)->next = q->next;
free(q);
return;
}
else
{
while (q != NULL)
{
prev = q;//前驱
q = q->next;
if (q == p)//相等了
{
prev->next = q->next;
free(q);
return;
}
}
}
}
在单链表删除这块,无论是头删、尾删、值删。都不能改变头节点,并且要注意去删除的节点是否为头节点的下一节点,若删除尾节点,要定位到前驱,将前驱的后继置空。而在值删的时候,可以直接寻找删除值的位置进行删除。
5.单链表的查:值查找,找到返回位置
SlistNode *SlistHeadFind(SList *phead, ElementType x)
{
assert(phead != NULL);
SlistNode *p = (*phead)->next;
while (p != NULL)//循环查找,这里不能做二分查找,因为链表不支持随机访问
{
if (p->data == x)
{
return p;
}
p = p->next;
}
return NULL;
}
6.单链表的排序:单链表的排序和顺序表有所不同,顺序表可直接进行值交换,而在链表中,一般是改变节点之间的指向,来达到排序的目的。
void SlistHeadSort(SList *phead)
{
assert(phead != NULL);
SlistNode *tmp = (*phead)->next,*p = (*phead)->next, *prev = NULL;//p为头节点下一节点
SlistNode *q = p->next;//q为p的下一个节点
p->next = NULL;//将p的next指向断开
while (q != NULL)
{
p = q;
q = q->next;
while (tmp != NULL && p->data > tmp->data)
{
prev = tmp;
tmp = tmp->next;
}
if (prev == NULL)//如果前驱为空,说明p的值比tmp的值要下,头节点的下一节点要更换
{
p->next = (*phead)->next;
(*phead)->next = p;
}
else
{
p->next = prev->next;
prev->next = p;
}
tmp = (*phead)->next;//tmp继续指向头的下一指针
prev = NULL;
}
}
最开始是这样的节点:

将p的尾指针进行断开:

逐个判断tmp节点的值和p的值大小,这里还有一个前驱指针,用来决定当p节点的数据比tmp数据小时,p节点的插入位置。
7.单链表的逆置:和排序差不多,也是同样直接断开,但是不用比较,直接进行交换就行了。
void SlistHeadReverse(SList *phead)//逆置
{
assert(phead != NULL);
SlistNode *p = (*phead)->next;
SlistNode *q = p->next;
p->next = NULL;
while (q != NULL)
{
p = q;
q = q->next;
p->next = (*phead)->next;
(*phead)->next = p;
}
}
8.删除单链表中重复的值
void SlistHeadEraseAll(SList *phead, ElementType x)
{
assert(phead != NULL);
SlistHeadSort(phead);//先进行排序
SlistNode *p = (*phead)->next, *tmp = NULL, *prev = *phead;
while (p != SlistHeadFind(phead, x))//找到第一个出现x的节点,prev等于出现这个节点的前驱
{
prev = p;
p = p->next;
}
while (p != NULL && p->data == x)//进行逐个释放
{
tmp = p;
p = p->next;
free(tmp);
}
prev->next = p;//前驱的下一个等于不为x的节点
}
在单链表中,因为不用考虑头节点的变换,所以实现要简单一点。若没有头节点,在进行排序逆置中,要考虑第一个节点的变化问题。并且链表不能随机访问。
三、单循环链表:和单链表类似,不过就是在尾节点指向不为空,而是又重新指向了头节点。
1.单循环链表的创建:
typedef struct SCListNode
{
ElementType data;
struct SCListNode *next;
}SCListNode;
typedef SCListNode* SCList;
2.单循环链表的初始化:
void SCListHeadIni(SCList *phead)//链表初始化
{
*phead = _BuyNode(0);//这里这个buynode是进行开辟节点时定义的一个函数
(*phead)->next = *phead;
}
SCListNode *_BuyNode(ElementType v)
{
SCListNode *_s = (SCListNode *)malloc(sizeof(SCListNode));
_s->data = v;
_s->next = _s;
return _s;
}
3.单循环链表的增:头插、尾插、值插入
void SCListHeadPushFront(SCList *phead, ElementType x)//头插法
{
assert(phead != NULL);
SCListNode *p = _BuyNode(x);
assert(p != NULL);
SCListNode *head = *phead;
if (head->next != *phead)//判断头节点是否为单循环
{
p->next = (*phead)->next;
(*phead)->next = p;
}
else
{
p->next = *phead;
(*phead)->next = p;
}
}
void SCListHeadPushBack(SCList *phead, ElementType x)//尾插法
{
assert(phead != NULL);
SCListNode *p = _BuyNode(x);
assert(p != NULL);
SCListNode *head = (*phead)->next;
while (head->next != *phead)//找到最后一个节点
{
head = head->next;
}
head->next = p;
p->next = *phead;//节点下一个指向头
}
void SCListHeadInsertVal(SCList *phead, ElementType x)//插入,插入前先排序
{
assert(phead != NULL);
SCListHeadSort(phead);
SCListNode *s = _BuyNode(x);
SCListNode *p = (*phead)->next, *prev = NULL;
while (p != *phead && p->data < x)//找到插入位置
{
prev = p;
p = p->next;
}
if (prev == NULL)//第一个位置就可插入
{
s->next = (*phead)->next;
(*phead)->next = s;
}
else//找到了插入位置,也有前驱,可以插入了
{
s->next = prev->next;
prev->next = s;
}
}
4.单循环链表的删:头删、尾删、值删
void SCListHeadPopFront(SCList *phead)//头删
{
assert(phead != NULL);
SCListNode *p = (*phead)->next;
if (p == *phead)//就只有一个头节点,不能删除
{
return;
}
(*phead)->next = p->next;//改变指向
free(p);
}
void SCListHeadPopBack(SCList *phead)//尾删
{
assert(phead != NULL);
SCListNode *p = (*phead)->next, *prev = NULL;
if (p == *phead)//只有头节点
{
return;
}
while (p->next != *phead)//找到尾节点
{
prev = p;
p = p->next;
}
if (prev == NULL)//只有两个节点,更换头节点指向
{
(*phead)->next = *phead;
free(p);
}
else
{
prev->next = *phead;//改变指向,释放
free(p);
}
}
void SCListHeadEraseVal(SCList *phead, ElementType x)//删除
{
assert(phead != NULL);
SCListNode *p = (*phead)->next, *prev=NULL;
if (p == *phead)
{
return;
}
while (p != *phead && p->data != x)//找到要删除节点的位置
{
prev = p;
p = p->next;
}
if (prev == NULL)//头节点的下一个删除
{
(*phead)->next = p->next;
free(p);
}
else//找到中间的删除位置
{
prev->next = p->next;
free(p);
}
}
单循环链表删除这块,要注意尾节点,最后删除的时候,要将前驱再指向头节点。
5.单循环链表的查:返回节点位置
SCListNode* SCListHeadFind(SCList *phead, ElementType x)//查找数据
{
assert(phead != NULL);
SCListNode *p = (*phead)->next;
while (p != *phead)
{
if (p->data == x)
{
return p;
}
p = p->next;
}
return NULL;
}
6.单循环链表的排序:采用节点之间指向来更改顺序
void SCListHeadSort(SCList *phead)//链表排序
{
assert(phead != NULL);
if (SCListLength(phead) <= 1)
{
return;
}
SCListNode *p = (*phead)->next,*tmp= (*phead)->next,*prev=NULL;
SCListNode *q = p->next;
p->next = *phead;//断开,指向头
while (q != *phead)
{
p = q;
q = q->next;
while (tmp != *phead && p->data > tmp->data)//寻找插入位置
{
prev = tmp;
tmp = tmp->next;
}
if (prev == NULL)//第一个位置插入
{
p->next = (*phead)->next;
(*phead)->next = p;
}
else//中间插入
{
p->next = prev->next;
prev->next = p;
}
tmp = (*phead)->next;//tmp继续指向头的下一个
prev = NULL;
}
}
7.单循环链表的逆置:
void SCListHeadReverse(SCList *phead)//链表逆置
{
assert(phead != NULL);
if (SCListLength(phead) <= 1)
{
return;
}
SCListNode *p = (*phead)->next;
SCListNode *q = p->next;
p->next = *phead;//断开
while (q != *phead)
{
p = q;
q = q->next;
p->next = (*phead)->next;//更改指向
(*phead)->next = p;
}
}
8.删除单循环链表中重复的值:先排序
void SCListHeadEraseAll(SCList *phead, ElementType x)//清除重复元素
{
assert(phead != NULL);
SCListHeadSort(phead);//排序
SCListNode *p = (*phead)->next, *prev = NULL,*q=NULL;
while (p != SCListHeadFind(phead, x))//找到第一个清除位置
{
prev = p;
p = p->next;
}
while (p != *phead && p->data == x)//清除
{
q = p;
p = p->next;
free(q);
}
if (prev == NULL)//第一个就可以清除
{
(*phead)->next = p;
}
else//中间位置
{
prev->next = p;
}
}
单循环链表中,需要注意的是,最后的节点一定要循环回来,否则就会导致错误。
四、双循环链表:双循环链表是每个节点都有两个指针,一个前驱,一个后继。
带头节点的双循环链表:
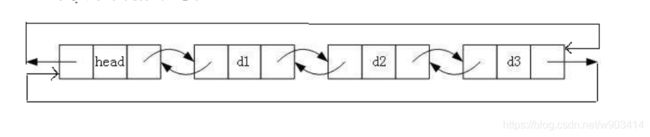
1.双循环链表的定义:
typedef struct DCListNode
{
ElementType data;
struct DCListNode *prev;//前驱
struct DCListNode *next;//后继
}DCListNode;
typedef DCListNode* DCList;
2.双循环链表的初始化
void DCListHeadIni(DCList *phead)//链表初始化
{
*phead = _BuyNode(0);//头节点
}
DCListNode *_BuyNode(ElementType v)
{
DCListNode *_s = (DCListNode *)malloc(sizeof(DCListNode));
_s->data = v;
_s->next = _s->prev = _s;
return _s;
}
3.双循环链表的增:头插、尾插、值插入
void DCListHeadPushFront(DCList *phead, ElementType x)//头插法
{
assert(phead != NULL);
DCListNode *p = *phead;
DCListNode *s = _BuyNode(x);
assert(s != NULL);
s->next = p->next;//插入的节点后继等于头节点的后继
s->prev = p;//前驱等于头节点
s->next->prev = s;//下一个节点的前驱等于s
s->prev->next = s;//前驱的后继等于s
}
void DCListHeadPushBack(DCList *phead, ElementType x)//尾插法
{
assert(phead != NULL);
DCListNode *p = *phead;
DCListNode *s = _BuyNode(x);
assert(s != NULL);
s->prev = p->prev;//插入节点的前驱等于头节点的前驱
s->next = p;//插入节点的后继等于头节点
s->prev->next = s;//s前驱的后继等于s
s->next->prev = s;s的后继的前驱等于s
}
void DCListHeadInsertVal(DCList *phead, ElementType x)//插入,插入前先排序
{
assert(phead != NULL);
DCListHeadSort(phead);//排序
DCListNode *s = _BuyNode(x);
DCListNode *p = (*phead)->next;
DCListNode *q = p->next;
while (p->data < x && p != *phead)//寻找插入位置
{
p = p->next;
}
s->next = p;//插入节点的后继等于p
s->prev = p->prev;//s的前驱等于p的前驱
s->prev->next = s;//s的前驱的后继等于s
s->next->prev = s;//s的后继的前驱等于s
}
双向循环链表因为有前驱和后继两个指针,所以在实现的时候特别方便,只需要知道该节点,就可以找到该节点的前驱和后继,在插入,删除和排序中很好实现。
4.双循环链表的删:头删、尾删、值删
void DCListHeadPopFront(DCList *phead)//头删
{
assert(phead != NULL);
DCListNode *p = (*phead)->next;
if (p != *phead)
{
p->prev->next = p->next;//直接改变指向
p->next->prev = p->prev;
free(p);
}
}
void DCListHeadPopBack(DCList *phead)//尾删
{
assert(phead != NULL);
DCListNode *p = (*phead)->prev;
if (p != *phead)
{
p->prev->next = p->next;//改变指向
p->next->prev = p->prev;
free(p);
}
}
void DCListHeadEraseVal(DCList *phead, ElementType x)//删除
{
assert(phead != NULL);
DCListNode *p = DCListHeadFind(phead, x);//查找该节点的位置
if (p == NULL)
{
return;
}
p->prev->next = p->next;//删除
p->next->prev = p->prev;
free(p);
}
双循环链表的的删除节点,只需要定位到该节点的位置,然后让前驱的后继指向后继,后继的前驱指向前驱。
5.双循环链表的查:值查,返回位置
DCListNode* DCListHeadFind(DCList *phead, ElementType x)//查找数据
{
assert(phead != NULL);
DCListNode *p = (*phead)->next;
while (p->data != x && p != *phead)//查找位置
{
p = p->next;
}
if (p == *phead)//为头节点,返回null
{
return NULL;
}
return p;
}
6.双循环链表的排序:
void DCListHeadSort(DCList *phead)//链表排序
{
assert(phead != NULL);
if (DCListHeadLength(phead) <= 1)
{
return;
}
DCListNode *p = (*phead)->next;
DCListNode *q = p->next;
p->next = p->prev;//断开
p->prev->prev = p;//断开,两个节点自循环
while (q != *phead)
{
p = q;
q = q->next;
DCListNode *tmp = (*phead)->next;
while (p->data > tmp->data && tmp != *phead)//查找插入位置
{
tmp = tmp->next;
}
p->prev = tmp->prev;//进行插入
p->next = tmp;
p->prev->next = p;
p->next->prev = p;
}
}
这块的排序,就当于值插入一样,先两个断开,再比较后序值的大小,然后进行插入。
7.双循环链表的逆置:
void DCListHeadReverse(DCList *phead)//链表逆置
{
assert(phead != NULL);
if (DCListHeadLength(phead) <= 1)
{
return;
}
DCListNode *p = (*phead)->next;
DCListNode *q = p->next;
p->next = p->prev;
p->prev->prev = p;//断开,两个节点自循环
while (q != *phead)
{
p = q;
q = q->next;
p->prev = *phead;//插入
p->next = (*phead)->next;
p->prev->next = p;
p->next->prev = p;
}
}
这块的逆置和头插法相似,直接将节点插入到头节点的后面。
8.删除双循环重复的值:
void DCListHeadEraseAll(DCList *phead, ElementType x)//清除和输入值在链表中一样的元素
{
assert(phead != NULL);
DCListHeadSort(phead);//排序
DCListNode *p = (*phead)->next;
if (p == *phead)//只有一个头节点
{
return;
}
while (p->data != x && p != *phead)//寻找删除位置
{
p = p->next;
}
while (p->data == x)//节点值相等,就一直删除
{
DCListNode *tmp = NULL;;
p->prev->next = p->next;//改变前驱的指向
p->next->prev = p->prev;//改变后的指向
tmp = p;
p = p->next;
free(tmp);//释放
}
}
双循环链表这块实现很方便,但是结构是最复杂的。
有需要的可以在这里下载代码(链表有无头节点):代码
总结:在顺序表这块实现很方便,但是容量是有限的,如果多开辟了空间,就会造成空间上的浪费。在链表这块,结构比较多,有无头节点链表,单,单循环,双,双循环,链表比较常用的是无头节点的单链表和带头节点的双循环链表。