一、部署Kubernetes集群
1.1 Kubernetes介绍
Kubernetes(K8S)是Google开源的容器集群管理系统,K8S在Docker容器技术的基础之上,大大地提高了容器化部署应用简单高效。并且具备了完整的集群管理能力,涵盖项目周期的各个环节。
Docker与Kubernetes联系:Docker是一个容器引擎,用于运行容器,Kubernetes是一个容器编排系统,不具备容器引擎功能,相比Docker是一个更高级封装,而他们在一起堪称珠联璧合。
1.2 创建Kubernetes集群方式
三种部署集群方式:
1、Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,尝试Kubernetes或日常开发的用户使用。不能用于生产环境。
2、Kubeadm也是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。Kubeadm降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。
3、二进制包,从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。我们这里使用二进制包部署Kubernetes集群,虽然手动部署麻烦点,但学习很多工作原理,更有利于后期维护。
1.3 集群部署架构规划
1.3.1 软件环境
CentOS:AWS
Docker:18.9.5-ce
Kubernetes:1.14.1
Etcd:3.3.12
Calico:3.6.1
1.3.2 服务器角色
| 角色 |
IP |
组件 |
| k8s-master1 |
172.31.50.170 |
kube-apiserver,kube-controller-manager,kube-scheduler,etcd,haproxy,keeplive |
| k8s-master2 |
172.31.50.101 |
kube-apiserver,kube-controller-manager,kube-scheduler,etcd,haproxy,keeplive |
| k8s-master3 |
172.31.58.221 |
kube-apiserver,kube-controller-manager,kube-scheduler,etcd,haproxy,keeplive |
| k8s-node1 |
172.31.55.50 |
kubelet,kube-proxy,docker,calico |
| k8s-node2 |
172.31.55.0 |
kubelet,kube-proxy,docker,calico |
|
|
192.168.10.24 |
masterHA集群的vip |
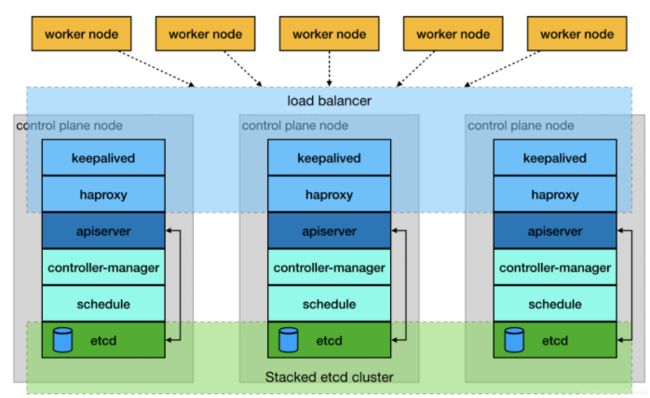
1.3.3 拓扑图
如果不是云环境,可以采用主流的软件负载均衡器,例如LVS、HAProxy、Nginx。这里使用HAProxy作为apiserver负载均衡器,架构图如下:
1.3.4 配置防火墙
1、关闭firewall
systemctl stop firewalld.service && systemctl disable firewalld.service
2、安装iptables防火墙
yum install -y iptables-services
#master节点默认该防火墙配置文件
cat /etc/sysconfig/iptables
*filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A INPUT -p icmp -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT -A INPUT -j REJECT --reject-with icmp-host-prohibited -A FORWARD -j REJECT --reject-with icmp-host-prohibited COMMIT
#node节点清空该配置,后续也不要手动添加规则
echo "" >/etc/sysconfig/iptables
3、重启防火墙
systemctl restart iptables.service && systemctl enable iptables.service
#说明:后续要添加端口,先重启服务器再保存。
service iptables restart && service iptables save
4、关闭selinux
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
cat /etc/selinux/config
注意:不要替换/etc/sysconfig/selinux文件,这是一个软连接,不会生效。
1.3.5 设置主机名
#对每一个节点进行设置主机名
vim /etc/hostname
k8smaster1
注意:aws修改centos主机名需要通过下面命令
hostnamectl set-hostname --static k8smaster
vim /etc/cloud/cloud.cfg #最后一行添加
preserve_hostname: true
#重启机器
reboot
#对每个节点配置IP和域名映射关系
vim /etc/hosts
172.31.50.170 k8smaster1 172.31.50.101 k8smaster2 172.31.58.221 k8smaster3 172.31.55.50 k8snode1 172.31.55.0 k8snode2
1.3.6 同步时间
yum install -y ntp
systemctl enable ntpd
systemctl start ntpd
timedatectl set-timezone Asia/Shanghai
timedatectl set-ntp yes
ntpq -p
1.4 部署etcd集群
在K8s-master1、K8s-master2、K8s-master3三个节点上部署etcd节点,并组成集群。
1.4.1 生成证书
在任意某一个etcd节点上安装即可,主要使用生成的证书,其他节点复制过去即可。使用cfssl来生成自签证书。
1、先下载cfssl工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
mv cfssl_linux-amd64 /usr/bin/cfssl
mv cfssljson_linux-amd64 /usr/bin/cfssljson
mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
2、创建三个文件
makdir etcd_ca
cd etcd_ca
# 创建 Etcd根证书配置文件
cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "87600h" }, "profiles": { "www": { "expiry": "87600h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF
# 创建 Etcd根证书请求文件
cat > ca-csr.json <<EOF { "CN": "etcd CA", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "ST": "Beijing" } ] } EOF
# 创建 Etcd服务证书请求文件
cat > server-csr.json <<EOF { "CN": "etcd", "hosts": [ "172.31.50.170", "172.31.50.101", "172.31.58.221" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing" } ] } EOF
3、生成证书
# 生成 Etcd根证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
# 生成 Etcd服务证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
生成后可以看到生成了4个pem文件
ls *pem

1.4.2 解压etcd
以下部署步骤在规划的三个etcd节点操作一样,唯一不同的是etcd配置文件中的服务器IP要写当前的。
二进制包下载地址:https://github.com/etcd-io/etcd/releases/
cd /usr/local/src/
wget https://github.com/etcd-io/etcd/releases/download/v3.3.12/etcd-v3.3.12-linux-amd64.tar.gz
mkdir /opt/etcd/{bin,cfg,ssl} -p
tar zxvf etcd-v3.3.12-linux-amd64.tar.gz
mv etcd-v3.3.12-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
1.4.3 创建etcd配置文件
cat > /opt/etcd/cfg/etcd <<EOF #[Member] ETCD_NAME="etcd01" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://172.31.50.170:2380" ETCD_LISTEN_CLIENT_URLS="https://172.31.50.170:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.31.50.170:2380" ETCD_ADVERTISE_CLIENT_URLS="https://172.31.50.170:2379" ETCD_INITIAL_CLUSTER="etcd01=https://172.31.50.170:2380,etcd02=https://172.31.50.101:2380,etcd03=https://172.31.58.221:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" EOF
注意:每个节点上标黄的需要调整对应的值。
参数说明:
ETCD_NAME 节点名称
ETCD_DATA_DIR 数据目录
ETCD_LISTEN_PEER_URLS 集群通信监听地址
ETCD_LISTEN_CLIENT_URLS 客户端访问监听地址
ETCD_INITIAL_ADVERTISE_PEER_URLS 集群通告地址
ETCD_ADVERTISE_CLIENT_URLS 客户端通告地址
ETCD_INITIAL_CLUSTER 集群节点地址
ETCD_INITIAL_CLUSTER_TOKEN 集群Token
ETCD_INITIAL_CLUSTER_STATE 加入集群的当前状态,new是新集群,existing表示加入已有集群
1.4.4 systemd管理etcd
vim /usr/lib/systemd/system/etcd.service
[Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=/opt/etcd/cfg/etcd ExecStart=/opt/etcd/bin/etcd \ --name=${ETCD_NAME} \ --data-dir=${ETCD_DATA_DIR} \ --listen-peer-urls=${ETCD_LISTEN_PEER_URLS} \ --listen-client-urls=${ETCD_LISTEN_CLIENT_URLS},http://127.0.0.1:2379 \ --advertise-client-urls=${ETCD_ADVERTISE_CLIENT_URLS} \ --initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS} \ --initial-cluster=${ETCD_INITIAL_CLUSTER} \ --initial-cluster-token=${ETCD_INITIAL_CLUSTER_TOKEN} \ --initial-cluster-state=new \ --cert-file=/opt/etcd/ssl/server.pem \ --key-file=/opt/etcd/ssl/server-key.pem \ --peer-cert-file=/opt/etcd/ssl/server.pem \ --peer-key-file=/opt/etcd/ssl/server-key.pem \ --trusted-ca-file=/opt/etcd/ssl/ca.pem \ --peer-trusted-ca-file=/opt/etcd/ssl/ca.pem Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target
1.4.5 拷贝证书
把刚才生成的证书拷贝到配置文件中的位置。
#在生成证书节点上可直接执行:
cp ~/etcd_ca/*.pem /opt/etcd/ssl/
#其他2个节点远程复制过去:
scp ~/etcd_ca/*.pem [email protected]:/opt/etcd/ssl
scp ~/etcd_ca/*.pem [email protected]:/opt/etcd/ssl
1.4.6 开放防火墙端口
三个节点防火墙都开放端口:2379、2380端口
vim /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 2379 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 2380 -j ACCEPT
#重启防火墙
service iptables restart && service iptables save
1.4.7 启动etcd并设置自启
systemctl daemon-reload
systemctl start etcd && systemctl enable etcd && systemctl status etcd
#注意:如果有问题,查看日志:tail /var/log/messages
1.4.8 验证集群
/opt/etcd/bin/etcdctl \
--ca-file=/opt/etcd/ssl/ca.pem --cert-file=/opt/etcd/ssl/server.pem --key-file=/opt/etcd/ssl/server-key.pem \
--endpoints="https://172.31.50.170:2379,https://172.31.50.101:2379,https://172.31.58.221:2379" \
cluster-health

如果输出上面截图信息,就说明集群部署成功。
1.4.9 etcdctl命令加入环境变量
vim /etc/profile
export PATH=/opt/etcd/bin:$PATH
#重新加载生效:
source /etc/profile
#下次登入还需要再次执行,所以把source命令添加到/etc/bashrc文件,这样会为每一个用户都执行这个命令。
echo "source /etc/profile" >> /etc/bashrc
1.5 Master节点部署组件
在部署Kubernetes之前一定要确保etcd是正常工作的,无特殊说明则需在三个master节点上操作。
1.5.1 生成证书
之前在master1节点的根目录etcd_ca下生成过etcd的证书,为了避免证书混乱,在根目录下新建目录存放新的证书。
cd
mkdir k8s_ca
cd k8s_ca/
1、生成CA证书
cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "expiry": "87600h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF
cat > ca-csr.json <<EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "ST": "Beijing", "O": "k8s", "OU": "System" } ] } EOF
#执行下面命令生成
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
2、生成apiserver证书
cat > server-csr.json <<EOF { "CN": "kubernetes", "hosts": [ "10.0.0.1", "127.0.0.1", "k8s-api-6443-c8528735cd54031c.elb.cn-north-1.amazonaws.com.cn", "172.31.50.170", "172.31.50.101", "172.31.58.221", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF
说明:10段为虚拟IP段,还需添加上负载均衡IP(aws则需要先配置好1.5节内容),以及apiserver集群IP。
#执行下面命令生成
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
3、生成kube-proxy证书
cat > kube-proxy-csr.json <<EOF { "CN": "system:kube-proxy", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF
#执行下面命令生成
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
4、生成admin证书
cat > admin-csr.json <<EOF { "CN": "admin", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "system:masters", "OU": "System" } ] } EOF
说明:后续 kube-apiserver 使用 RBAC 对客户端(如 kubelet、kube-proxy、Pod)请求进行授权;kube-apiserver 预定义了一些 RBAC 使用的 RoleBindings,如 cluster-admin 将 Group system:masters 与 Role cluster-admin 绑定,该 Role 授予了调用kube-apiserver 的所有 API的权限;O 指定该证书的 Group 为 system:masters,kubelet 使用该证书访问 kube-apiserver 时 ,由于证书被 CA 签名,所以认证通过,同时由于证书用户组为经过预授权的 system:masters,所以被授予访问所有 API 的权限;
注意:这个admin 证书,是将来生成管理员用的kube config 配置文件用的,现在我们一般建议使用RBAC 来对kubernetes 进行角色权限控制,kubernetes 将证书中的CN 字段作为User,O 字段作为 Group。
#执行下面命令生成
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin
5、查看生成的证书
最终生成8个文件
admin-key.pem admin.pem ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem server-key.pem server.pem
![]()
1.5.2 部署apiserver组件
此章节在所有master节点上操作。
下载二进制包页面:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.14.md
下载这个包(kubernetes-server-linux-amd64.tar.gz)就够了,包含了所需的所有组件。地址:https://storage.googleapis.com/kubernetes-release/release/v1.14.1/kubernetes-server-linux-amd64.tar.gz
或者用上传的七牛云:https://img.yiyao.cc/kubernetes-server-linux-amd64.tar.gz
1、拷贝证书
mkdir /opt/kubernetes/{bin,cfg,ssl} -p
#拷贝证书
cp *pem /opt/kubernetes/ssl
#master2节点远程复制过去:
scp *pem [email protected]:/opt/kubernetes/ssl
2、解压文件
cd /usr/local/src
tar zxvf kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin
cp kube-apiserver kube-scheduler kube-controller-manager kubectl /opt/kubernetes/bin
3、创建token文件
cat > /opt/kubernetes/cfg/token.csv <<EOF bd41d77ac7cad4cfaa27f6403b1ccf16,kubelet-bootstrap,10001,"system:kubelet-bootstrap" EOF
说明:
第一列:随机32位字符串,可自己命令生成:head -c 16 /dev/urandom | od -An -t x | tr -d ' '
第二列:用户名
第三列:UID
第四列:用户组
4、创建apiserver配置文件
配置好前面生成的证书,确保能连接etcd;address地址改成当前节点的IP。
vim /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \ --v=4 \ --etcd-servers=https://172.31.50.170:2379,https://172.31.50.101:2379,https://172.31.58.221:2379 \ --bind-address=172.31.50.170 \ --secure-port=6443 \ --advertise-address=172.31.50.170 \ --allow-privileged=true \ --service-cluster-ip-range=10.0.0.0/16 \ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota,NodeRestriction \ --authorization-mode=RBAC,Node \ --enable-bootstrap-token-auth \ --token-auth-file=/opt/kubernetes/cfg/token.csv \ --service-node-port-range=30000-50000 \ --tls-cert-file=/opt/kubernetes/ssl/server.pem \ --tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \ --client-ca-file=/opt/kubernetes/ssl/ca.pem \ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \ --kubelet-client-certificate=/opt/kubernetes/ssl/admin.pem \ --kubelet-client-key=/opt/kubernetes/ssl/admin-key.pem \ --etcd-cafile=/opt/etcd/ssl/ca.pem \ --etcd-certfile=/opt/etcd/ssl/server.pem \ --etcd-keyfile=/opt/etcd/ssl/server-key.pem"
#参数说明:
--logtostderr 启用日志
---v 日志等级
--etcd-servers etcd集群地址
--bind-address 监听地址
--secure-port https安全端口
--advertise-address 集群通告地址
--allow-privileged 启用授权
--service-cluster-ip-range Service虚拟IP地址段
--enable-admission-plugins 准入控制模块
--authorization-mode 认证授权,启用RBAC授权和节点自管理
--enable-bootstrap-token-auth 启用TLS bootstrap功能,后面会讲到
--token-auth-file token文件
--service-node-port-range Service Node类型默认分配端口范围
5、systemd管理apiserver
vim /usr/lib/systemd/system/kube-apiserver.service
[Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-apiserver ExecStart=/opt/kubernetes/bin/kube-apiserver $KUBE_APISERVER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target
6、启动apiserver
systemctl daemon-reload
systemctl enable kube-apiserver
systemctl restart kube-apiserver
systemctl status kube-apiserver
7、开放防火墙端口
kube-apiserver默认启动两个端口6443、8080
vim /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 6443 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 8080 -j ACCEPT
#重启防火墙
service iptables restart && service iptables save
1.5.3 部署schduler组件
1、创建schduler配置文件
vim /opt/kubernetes/cfg/kube-scheduler
KUBE_SCHEDULER_OPTS="--logtostderr=true \ --v=4 \ --master=127.0.0.1:8080 \ --leader-elect"
#参数说明:
--master 连接本地apiserver
--leader-elect 当该组件启动多个时,自动选举(HA)
2、systemd管理schduler组件
vim /usr/lib/systemd/system/kube-scheduler.service
[Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-scheduler ExecStart=/opt/kubernetes/bin/kube-scheduler $KUBE_SCHEDULER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target
3、启动schduler
systemctl daemon-reload
systemctl enable kube-scheduler
systemctl restart kube-scheduler
systemctl status kube-scheduler
4、开放防火墙端口
schduler默认启动端口10251
vim /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 10251 -j ACCEPT
#重启防火墙
service iptables restart && service iptables save
1.5.4 部署controller-manager组件
1、创建controller-manager配置文件
vim /opt/kubernetes/cfg/kube-controller-manager
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=true \ --v=4 \ --master=127.0.0.1:8080 \ --leader-elect=true \ --address=127.0.0.1 \ --service-cluster-ip-range=10.0.0.0/16 \ --cluster-cidr=10.10.0.0/16 \ --cluster-name=kubernetes \ --cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \ --cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \ --root-ca-file=/opt/kubernetes/ssl/ca.pem \ --service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem"
2、systemd管理controller-manager组件
vim /usr/lib/systemd/system/kube-controller-manager.service
[Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-controller-manager ExecStart=/opt/kubernetes/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target
3、启动controller-manager
systemctl daemon-reload
systemctl enable kube-controller-manager
systemctl restart kube-controller-manager
systemctl status kube-controller-manager
4、开放防火墙端口
schduler默认启动端口10257
vim /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 10257 -j ACCEPT
#重启防火墙
service iptables restart && service iptables save
1.5.5 查看集群组件状态
/opt/kubernetes/bin/kubectl get cs

如上输出说明组件都正常。另一个Master节点部署方式一样。
可以把kubectl命令加入到环境变量
vim /etc/profile
export PATH=/opt/kubernetes/bin:$PATH
#重新加载生效
source /etc/profile
1.6 Master高可用
所谓的Master HA,其实就是APIServer的HA,Master的其他组件controller-manager、scheduler都是可以通过etcd做选举(--leader-elect),而APIServer设计的就是可扩展性,所以做到APIServer很容易,只要前面加一个负载均衡轮训转发请求即可。如果是aws可以采用负载均衡器实现,如果是实体机可以采用Haproxy+keeplive实现。下面分别对这两种方法进行验证。
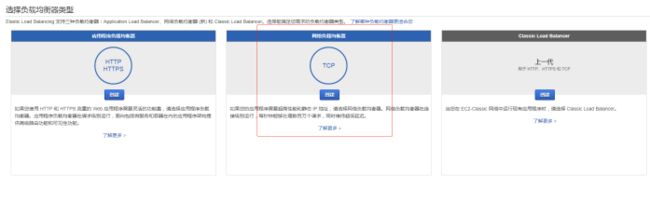
1.6.1 方法一:aws负载均衡器
1、配置aws负载均衡
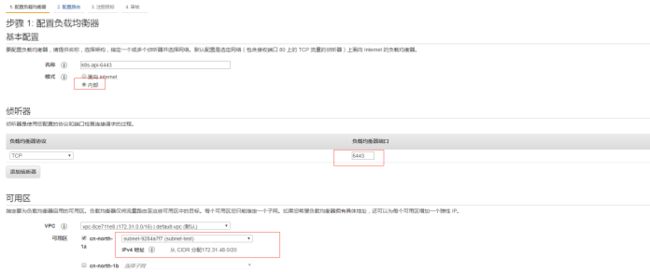
2、配置路由
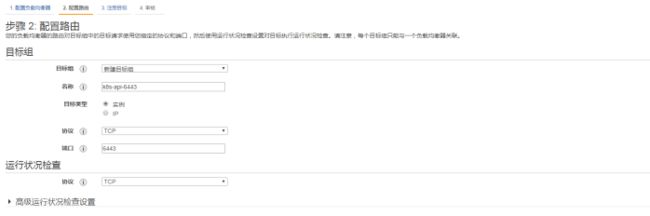
3、配置路由,选择实例中的6443端口
4、注册目标,选择3个master实例
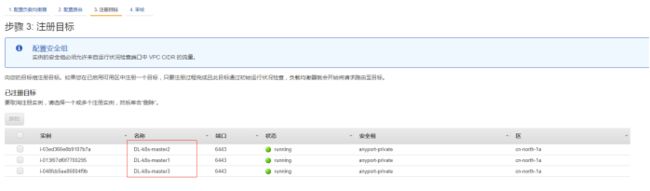
5、下一步审核即可,最后会创建一个lb,并且会分配到一个域名
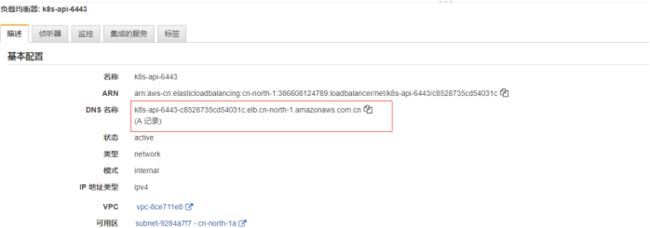
6、本地用tcping命令测试,可发现已经代理了6443端口
tcping k8s-api-6443-c8528735cd54031c.elb.cn-north-1.amazonaws.com.cn 6443

后续kubelet指定apiserver的地址时候,可以写该域名。
1.6.2 方法二:Haproxy+keepalive
在所有Master节点上部署Haproxy+keepalive。(适应于非云平台部署,因云平台不支持keepalive)
1、部署haproxy
所有master节点上部署,配置保持一样。
1)安装haproxy
yum -y install haproxy
2)修改配置文件
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg-back
vim /etc/haproxy/haproxy.cfg
global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults mode tcp log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 frontend main *:16443 acl url_static path_beg -i /static /images /javascript /stylesheets acl url_static path_end -i .jpg .gif .png .css .js use_backend static if url_static default_backend kube-apiserver backend static balance roundrobin server static 127.0.0.1:4331 check backend kube-apiserver balance roundrobin server matser1 172.31.50.170:6443 check server master2 172.31.50.101:6443 check
#注意:修改标红的地方
1、defaults 模块中的 mode http 要改为 tcp(或者在下面的 frontend 和 backend 模块中单独定义 mode tcp )如果不改,后续 kubectl get node 会处于 NotReady 状态。
2、frontend 端口需指定非 6443 端口,要不然其他 master 节点会启动异常(如果 haproxy 单独主机,则可用 6443 端口)
说明:配置文件可以拷贝其他节点,配置文件保持一样。
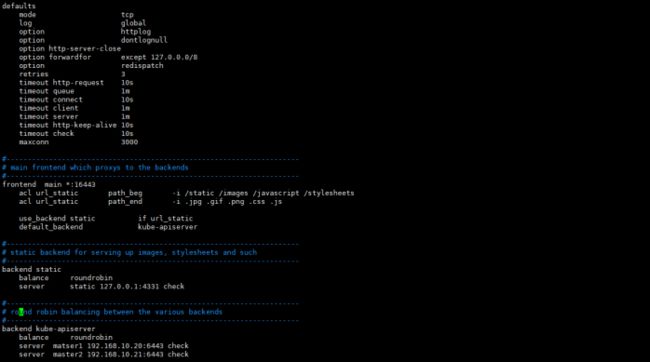
3)启动haproxy
systemctl start haproxy
systemctl enable haproxy
systemctl status haproxy
4)配置防火墙
vim /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 16443 -j ACCEPT
#重启防火墙
service iptables restart && service iptables save
2、 部署keepalive
1)安装keepalive
yum install -y keepalived
2)修改配置文件
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf-back
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id LVS_1 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.10.24/24 } }
说明:
1、global_defs 只保留 router_id(每个节点都不同);
2、修改 interface(vip绑定的网卡),及 virtual_ipaddress(vip地址及掩码长度);
3、删除后面的示例
4、其他节点只需修改 state 为 BACKUP,优先级 priority 低于100即可。
3)启动keeplive
systemctl start keepalived
systemctl enable keepalived
systemctl status keepalived
4)配置防火墙
防火墙要对vrrp协议进行开放
vim /etc/sysconfig/iptables
-A INPUT -p vrrp -j ACCEPT
#重启防火墙
service iptables restart && service iptables save
5)查看状态
ip addr show ens33
可以看到vip只在一台机器上;如果两个机器都有vip,可能是防火墙拦截了vrrp协议。


1.7 Node节点部署组件
Master apiserver启用TLS认证后,Node节点kubelet组件想要加入集群,必须使用CA签发的有效证书才能与apiserver通信,当Node节点很多时,签署证书是一件很繁琐的事情,因此有了TLS Bootstrapping机制,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。
1.7.1 认证流程
认证大致工作流程如图所示:

1.7.2 用户绑定系统集群角色
在msater1上面执行,将kubelet-bootstrap用户绑定到系统集群角色:
/opt/kubernetes/bin/kubectl create clusterrolebinding kubelet-bootstrap \ --clusterrole=system:node-bootstrapper \ --user=kubelet-bootstrap

1.7.3 创建kubeconfig文件
在mster1生成kubernetes证书的目录下执行以下命令生成kubeconfig文件,其他节点拷贝过去即可。
cd /root/k8s_ca/
1、创建bootstrapping kubeconfig文件
1)指定apiserver 内网负载均衡地址端口(vip:port),以及token值
KUBE_APISERVER="https://k8s-api-6443-c8528735cd54031c.elb.cn-north-1.amazonaws.com.cn:6443" BOOTSTRAP_TOKEN=bd41d77ac7cad4cfaa27f6403b1ccf16
说明: KUBE_APISERVER 参数对应的就是 AWS 中设置的负载均衡地址,或者对应 keepalive 的 vip 地址。
2)设置集群参数
/opt/kubernetes/bin/kubectl config set-cluster kubernetes \ --certificate-authority=./ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=bootstrap.kubeconfig
3)设置客户端认证参数
/opt/kubernetes/bin/kubectl config set-credentials kubelet-bootstrap \ --token=${BOOTSTRAP_TOKEN} \ --kubeconfig=bootstrap.kubeconfig
4)设置上下文参数
/opt/kubernetes/bin/kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig
5)设置默认上下文
/opt/kubernetes/bin/kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
2、创建kube-proxy kubeconfig文件
1)设置集群参数
/opt/kubernetes/bin/kubectl config set-cluster kubernetes \ --certificate-authority=./ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-proxy.kubeconfig
2)设置客户端认证参数
/opt/kubernetes/bin/kubectl config set-credentials kube-proxy \ --client-certificate=./kube-proxy.pem \ --client-key=./kube-proxy-key.pem \ --embed-certs=true \ --kubeconfig=kube-proxy.kubeconfig
3)设置上下文参数
/opt/kubernetes/bin/kubectl config set-context default \ --cluster=kubernetes \ --user=kube-proxy \ --kubeconfig=kube-proxy.kubeconfig
4)设置默认上下文
/opt/kubernetes/bin/kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
3、查看生成的kubeconfig文件
ls *kubeconfig
bootstrap.kubeconfig kube-proxy.kubeconfig
![]()
4、拷贝kubeconfig文件
将这两个文件拷贝到Node节点/opt/kubernetes/cfg目录下。
需要在node节点上新建目录
mkdir /opt/kubernetes/{bin,cfg,ssl} -p
scp *kubeconfig [email protected]:/opt/kubernetes/cfg
scp *kubeconfig [email protected]:/opt/kubernetes/cfg
1.7.4 Node节点安装Docker
在所有node节点安装docker。
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install docker-ce -y
systemctl start docker
systemctl enable docker
注意:得提前安装好docker环境,要不然kubelet启动不起来。
1.7.5 部署kubelet组件
无特殊说明,则默认在所有node节点上都部署。
1、拷贝kubelet和kube-proxy文件
从msater1上下载解压的二进制包中的kubelet和kube-proxy拷贝到node节点的/opt/kubernetes/bin目录下。
cd /usr/local/src
wget https://img.yiyao.cc/kubernetes-server-linux-amd64.tar.gz
tar -zxvf kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin
scp kubelet kube-proxy [email protected]:/opt/kubernetes/bin
scp kubelet kube-proxy [email protected]:/opt/kubernetes/bin
2、创建kubelet配置文件
vim /opt/kubernetes/cfg/kubelet
KUBELET_OPTS="--logtostderr=true \ --v=4 \ --hostname-override=k8snode1 \ --kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \ --bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \ --config=/opt/kubernetes/cfg/kubelet.config \ --cert-dir=/opt/kubernetes/ssl \ --client-ca-file=/opt/kubernetes/ssl/ca.pem \ --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"
并且需要拷贝ca证书到/opt/kubernetes/ssl目录下。
参数说明:
--hostname-override 在集群中显示的主机名
--kubeconfig 指定kubeconfig文件位置,会自动生成
--bootstrap-kubeconfig 指定刚才生成的bootstrap.kubeconfig文件
--cert-dir 颁发证书存放位置
--pod-infra-container-image 管理Pod网络的镜像
3、创建kubelet.config配置文件
注意格式缩进
vim /opt/kubernetes/cfg/kubelet.config
kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 address: 172.31.55.50 port: 10250 readOnlyPort: 10255 cgroupDriver: cgroupfs clusterDNS: ["10.0.0.2"] clusterDomain: cluster.local. failSwapOn: false authentication: anonymous: enabled: true webhook: enabled: false
4、systemd管理kubelet组件
vim /usr/lib/systemd/system/kubelet.service
[Unit] Description=Kubernetes Kubelet After=docker.service Requires=docker.service [Service] EnvironmentFile=/opt/kubernetes/cfg/kubelet ExecStart=/opt/kubernetes/bin/kubelet $KUBELET_OPTS Restart=on-failure KillMode=process [Install] WantedBy=multi-user.target
5、启动kubelet组件
systemctl daemon-reload
systemctl enable kubelet #开机自启
systemctl restart kubelet #启动
systemctl status kubelet #启动状态
会占用10250端口(需要在iptables设置开放,协议为tcp),要不然进入容器会报错:
Error from server: error dialing backend: dial tcp 172.31.55.50:10250: connect: no route to host
这里是把所有 node 节点的iptables配置文件都清空的,默认所有端口开放,所以不用单独设置。
6、在Master审批Node加入集群
启动后还没加入到集群中,需要手动允许该节点才可以。
1)在Master节点查看请求签名的Node:
/opt/kubernetes/bin/kubectl get csr

可以看到有两个节点的签名请求,如果执行命令后提示:No resources found,可去node节点查看messages日志。
2)在Master节点批准签名
/opt/kubernetes/bin/kubectl certificate approve node-csr-SJvxb_b-sBqfsLo-ILzaQm_6S9DH_w3THpLGCLNkLDU
/opt/kubernetes/bin/kubectl certificate approve node-csr-bF-v5M0Nv3niDVVEGf1YdlwYvRoRrjhR82jlPiXiOvU

3)查看签名状态
/opt/kubernetes/bin/kubectl get node

状态都为Ready。
1.7.6 部署kube-proxy组件
在所有node节点上部署。
1、创建kube-proxy配置文件
vim /opt/kubernetes/cfg/kube-proxy
KUBE_PROXY_OPTS="--logtostderr=true \ --v=4 \ --hostname-override=k8snode1 \ --cluster-cidr=10.10.0.0/16 \ --kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
注意:cluster-cidr不能与service-cidr还有主机的cidr网段重叠。
2、systemd管理kube-proxy组件
vim /usr/lib/systemd/system/kube-proxy.service
[Unit] Description=Kubernetes Proxy After=network.target [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-proxy ExecStart=/opt/kubernetes/bin/kube-proxy $KUBE_PROXY_OPTS Restart=on-failure [Install] WantedBy=multi-user.target
3、启动kube-proxy组件
systemctl daemon-reload
systemctl enable kube-proxy
systemctl restart kube-proxy
systemctl status kube-proxy
#会占用两个端口:10249、10256
1.7.7 确认node能够访问443端口
tcping 10.0.0.1 443
到此部署node完成。
1.8 部署Calico网络
若无特殊说明,都需在master1节点上操作。配置参考:https://www.jianshu.com/p/5e9e2e5312d9
1.8.1 工作原理
1、特点优势
1) 纯三层的SDN 实现,它基于BPG 协议和Linux自身的路由转发机制,不依赖特殊硬件,容器通信也不依赖iptables NAT(使用直接路由方式实现通行)或Tunnel 等技术,带宽性能接近主机。
2)能够方便的部署在物理服务器、虚拟机或者容器环境下。
3)同时calico自带的基于iptables的ACL管理组件非常灵活,能够满足比较复杂的安全隔离需求。支持Kubernetes networkpolicy概念
4)容器间网络三层隔离,无需要担心arp风暴
5)自由控制的policy规则
6)通过iptables和kernel包转发,效率高,损耗低
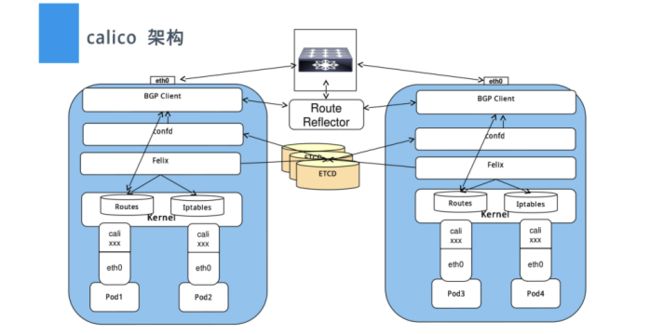
2、calico组件
1)Felix:主要负责路由配置以及ACLS规则的配置以及下发,它存在在每个node节点上。
2)etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
3)BGPClient(BIRD), 主要负责把 Felix写入 kernel的路由信息分发到当前 Calico网络,确保 workload间的通信的有效性;
4)BGPRoute Reflector(BIRD), 大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个 BGPRoute Reflector 来完成集中式的路由分发;
如下图:
1.8.2 配置calico
部署calico需要在kubernetes集群部署好后操作,只需在master1上操作
1、下载yaml文件
mkdir /opt/calico/{bin,deploy} -p
cd /opt/calico/deploy
wget https://docs.projectcalico.org/v3.6/getting-started/kubernetes/installation/hosted/calico.yaml
2、配置calico
部署之前需要检查3处
1)配置ConfigMap中etcd集群etcd_endpoints
etcd_endpoints: "https://172.31.50.170:2379,https://172.31.50.101:2379,https://172.31.58.221:2379"
2)配置Calico访问etcd集群的TLS证书,默认已经给出了访问etcd的TLS文件所在容器路径了,填进去即可(注意:此配置为容器内部读取的变量,所以证书路径为容器路径,而不是宿主机路径,不要修改为别的路径。)。
etcd_ca: "/calico-secrets/etcd-ca" etcd_cert: "/calico-secrets/etcd-cert" etcd_key: "/calico-secrets/etcd-key"

3)在Secret部分中,是采用创建secret的方式来配置TLS文件,在这里我们改用hostPath挂载TLS文件方式
#注释掉的Secret部分的TLS部分,默认为注释可不用改

#设置calico-node以hostpath的方式来挂载TLS文件,找到DaemonSet部分,设置为如下:
- name: etcd-certs
hostPath:
path: /opt/etcd/ssl

#设置calico-kube-controllers以hostpath挂载TLS文件,找到Deployment部分,设置为如下:
- name: etcd-certs
hostPath:
path: /opt/etcd/ssl
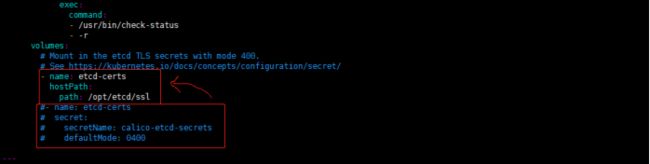
4)修改deamonset部分CALICO_IPV4POOL_CIDR变量
value: "10.10.0.0/16"

说明:
1、CALICO_IPV4POOL_CIDR: Calico IPAM的IP地址池,Pod的IP地址将从该池中进行分配(后续需要更改这个IP池,可参考1.8.9小节)。这个值需要同kube-controller-manager和kebe-proxy定义的--cluster-cidr值一致,但是得和apiserver中的service-cluster-ip-range值不同。
2、ALICO_IPV4POOL_IPIP:是否启用IPIP模式,启用IPIP模式时,Calico将在node上创建一个tunl0的虚拟隧道。
3、FELIX_LOGSEVERITYSCREEN: 日志级别。
4、IP Pool可以使用两种模式:BGP或IPIP。使用IPIP模式时,设置 CALICO_IPV4POOL_IPIP="always",不使用IPIP模式时,设置为"off",此时将使用BGP模式。
5、IPIP:ipip是在宿主机网络不完全支持bgp时,一种妥协的overlay机制,在宿主机创建1个”tunl0”虚拟端口;设置为false时,路由即纯bgp模式,理论上ipip模式的网络传输性能低于纯bgp模式;设置为true时,又分ipip always模式(纯ipip模式)与ipip cross-subnet模式(ipip-bgp混合模式),后者指“同子网内路由采用bgp,跨子网路由采用ipip”
1.8.3 修改kubelet
在每个node节点上操作
#kubelet启动服务中增加--network-plugin、--cni-conf-dir、--cni-bin-dir三个配置参数
vim /opt/kubernetes/cfg/kubelet
--network-plugin=cni \ --cni-conf-dir=/etc/cni/net.d \ --cni-bin-dir=/opt/cni/bin \
#重启kubelet
systemctl daemon-reload && systemctl restart kubelet && systemctl status kubelet
1.8.4 拷贝etcd的TLS授权文件
在各node节点操作,把master上的etcd证书全部复制到所有node的目录下(步骤略),然后重命名一下(这里复制一份,因为后面安装calicoctl工具需要原来的证书名字):
mkdir /opt/etcd/ssl -p
cd /opt/etcd/ssl
cp ca.pem etcd-ca
cp server-key.pem etcd-key
cp server.pem etcd-cert
1.8.5 部署calico组件
#部署calico
kubectl apply -f calico.yaml

#查看calico服务
calico-node用的是daemonset,会在每个node上启动; calico-kube-controllers用的是Deployment,会在某个node启动。
kubectl get deployment,pod -n kube-system

#同时在node节点上可以看到已经生成了tunl0隧道网卡

1.8.6 验证网络功能
新建一个nginx pod
cat > my-nginx.yaml <<EOF apiVersion: apps/v1 kind: Deployment metadata: name: my-nginx spec: replicas: 2 selector: matchLabels: k8s-app: my-nginx template: metadata: labels: k8s-app: my-nginx spec: containers: - name: my-nginx image: nginx:1.9 ports: - containerPort: 80 EOF
#创建pod
kubectl create -f my-nginx.yaml
#创建my-nginx服务
kubectl expose deploy my-nginx
#查看pod
kubectl get svc,pod --all-namespaces -o wide

看到可以给pod分配到IP,说明calico配置好了。(默认所有的pod都是互通的,包括跨node。可以用 route -n 查看有通往其他 node 的 tunl0 路由)
1.8.7 安装管理工具calicoctl
在所有master和node节点上操作
1、下载calicoctl
cd /opt/calico/bin (从节点:mkdir -p /opt/calico/bin && cd /opt/calico/bin)
wget https://github.com/projectcalico/calicoctl/releases/download/v3.6.0/calicoctl
chmod +x calicoctl
#添加calicoctl 命令加入到环境变量
echo "export PATH=/opt/calico/bin:\$PATH" >>/etc/profile
#重新加载生效
source /etc/profile
2、编写calicoctl的配置文件
#默认为下面的路径,不要改动
mkdir /etc/calico
vim /etc/calico/calicoctl.cfg
apiVersion: projectcalico.org/v3 kind: CalicoAPIConfig metadata: spec: datastoreType: "etcdv3" etcdEndpoints: "https://172.31.50.170:2379,https://172.31.50.101:2379,https://172.31.58.221:2379" etcdKeyFile: "/opt/etcd/ssl/server-key.pem" etcdCertFile: "/opt/etcd/ssl/server.pem" etcdCACertFile: "/opt/etcd/ssl/ca.pem"
3、查看calico状态
#查看已注册的节点列表
calicoctl get node

#查看默认IP池
calicoctl get ippool -o wide

#查看节点状态为Established(这个必须要在每个node节点上安装calicoctl,在node上执行,并且只能看到非本节点的)。
calicoctl node status
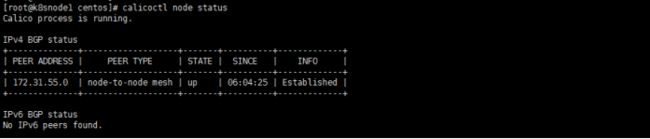
到此部署calico完成。
1.8.8 更换IP池方法
参考官网:https://docs.projectcalico.org/v3.6/networking/changing-ip-pools
1、前提条件
在Kubernetes中,确保以下所有三个参数必须等于或包含Calico IP池CIDR
kube-apiserver: --pod-network-cidr
kube-proxy: --cluster-cidr
kube-controller-manager: --cluster-cidr
说明:我设置了apiserver后,apiserver启动失败,暂不设置。
2、添加新的IP池
#查看默认的IP池
calicoctl get ippool -o wide

#创建新的IP池
calicoctl create -f -<<EOF apiVersion: projectcalico.org/v3 kind: IPPool metadata: name: new-pool spec: cidr: 10.10.0.0/16 ipipMode: Always natOutgoing: true EOF
#查看到有2个IP池

3、禁用旧的IP池
首先将IP池定义保存到本地磁盘
cd /opt/calico/deploy
calicoctl get ippool -o yaml > pool.yaml
#编辑pool.yaml文件,添加disabled: true到default-ipv4-ippoolIP池,最终文件内容如下:
apiVersion: projectcalico.org/v3 items: - apiVersion: projectcalico.org/v3 kind: IPPool metadata: creationTimestamp: 2019-04-29T03:22:59Z name: default-ipv4-ippool resourceVersion: "82916" uid: 16db9294-6a2e-11e9-b48f-0225173d78b8 spec: blockSize: 26 cidr: 10.0.0.0/24 ipipMode: Always natOutgoing: true nodeSelector: all() disabled: true - apiVersion: projectcalico.org/v3 kind: IPPool metadata: creationTimestamp: 2019-05-06T05:32:27Z name: new-pool resourceVersion: "1086435" uid: 55a21a46-6fc0-11e9-bf99-02b325080bdc spec: blockSize: 26 cidr: 10.10.0.0/16 ipipMode: Always natOutgoing: true nodeSelector: all() kind: IPPoolList metadata: resourceVersion: "1086435"
#应用更改
calicoctl apply -f pool.yaml
#再查看IP池状态
calicoctl get ippool -o wide

4、重新创建从旧IP池分配地址的所有现有工作负载
#查看现有的工作负载
kubectl get svc,pod --all-namespaces -o wide
#重新创建所有现有工作负载
kubectl delete pod -n online online-nginx-776bbdf4f8-2fl95
kubectl delete pod -n online online-nginx-776bbdf4f8-sznmg
5、删除旧的IP池
calicoctl delete pool default-ipv4-ippool
1.8.9 卸载calico方法
1、master上执行删除pod
kubectl delete -f calico.yaml
2、node上删除ipip模块(对应的网卡和路由也会被删除)
modprobe -r ipip
3、node上删除生成的文件
rm -rf /etc/cni/net.d/ && rm -rf /opt/cni/bin/
4、重启node
reboot
二、部署CoreDNS
在master1上操作,参考:https://www.zrq.org.cn/post/k8s%E9%83%A8%E7%BD%B2coredns/
2.1 下载配置文件
从官网下载配置文件(https://github.com/coredns/deployment/tree/master/kubernetes),找到 coredns.yam.sed 和 deploy.sh 两个文件,下载后存放在下面的新建目录下
mkdir /opt/coredns && cd /opt/coredns/
wget https://raw.githubusercontent.com/coredns/deployment/master/kubernetes/deploy.sh
wget https://raw.githubusercontent.com/coredns/deployment/master/kubernetes/coredns.yaml.sed
chmod +x deploy.sh
2.2 修改部署文件
由于是二进制部署的集群,不包含kube-dns,故不需从kube-dns转到coredns。
1、先查看集群的CLUSTERIP网段
kubectl get svc

2、修改部署文件
修改$DNS_DOMAIN、$DNS_SERVER_IP变量为实际值,并修改image后面的镜像。
这里直接用deploy.sh脚本进行修改:
./deploy.sh -s -r 10.0.0.0/16 -i 10.0.0.2 -d cluster.local > coredns.yaml
注意:网段为10.0.0.0/16(同apiserver定义的service-cluster-ip-range值,非kube-proxy中的cluster-cidr值),DNS的地址设置为10.0.0.2
3、修改前后的文件对比
diff coredns.yaml coredns.yaml.sed

附:生成的 coredns.yaml文件,注意标黄位置。
apiVersion: v1 kind: ServiceAccount metadata: name: coredns namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: kubernetes.io/bootstrapping: rbac-defaults name: system:coredns rules: - apiGroups: - "" resources: - endpoints - services - pods - namespaces verbs: - list - watch - apiGroups: - "" resources: - nodes verbs: - get --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:coredns roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:coredns subjects: - kind: ServiceAccount name: coredns namespace: kube-system --- apiVersion: v1 kind: ConfigMap metadata: name: coredns namespace: kube-system data: Corefile: | .:53 { errors health ready kubernetes cluster.local 10.0.0.0/16 { pods insecure fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf cache 30 loop reload loadbalance } --- apiVersion: apps/v1 kind: Deployment metadata: name: coredns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/name: "CoreDNS" spec: replicas: 2 strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 selector: matchLabels: k8s-app: kube-dns template: metadata: labels: k8s-app: kube-dns spec: priorityClassName: system-cluster-critical serviceAccountName: coredns tolerations: - key: "CriticalAddonsOnly" operator: "Exists" nodeSelector: beta.kubernetes.io/os: linux containers: - name: coredns image: coredns/coredns:1.5.0 imagePullPolicy: IfNotPresent resources: limits: memory: 170Mi requests: cpu: 100m memory: 70Mi args: [ "-conf", "/etc/coredns/Corefile" ] volumeMounts: - name: config-volume mountPath: /etc/coredns readOnly: true ports: - containerPort: 53 name: dns protocol: UDP - containerPort: 53 name: dns-tcp protocol: TCP - containerPort: 9153 name: metrics protocol: TCP securityContext: allowPrivilegeEscalation: false capabilities: add: - NET_BIND_SERVICE drop: - all readOnlyRootFilesystem: true livenessProbe: httpGet: path: /health port: 8080 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 readinessProbe: httpGet: path: /ready port: 8181 scheme: HTTP dnsPolicy: Default volumes: - name: config-volume configMap: name: coredns items: - key: Corefile path: Corefile --- apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system annotations: prometheus.io/port: "9153" prometheus.io/scrape: "true" labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" kubernetes.io/name: "CoreDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.0.0.2 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP - name: metrics port: 9153 protocol: TCP
#说明:
$DNS_DOMAIN 被修改为:cluster.local
image 这边用的是:coredns/coredns:1.5.0
$DNS_SERVER_IP 被修改为:10.0.0.2
2.3 部署coredns
#部署
kubectl create -f coredns.yaml

#查看
kubectl get svc,pod -n kube-system

2.4 修改kubelet的dns服务参数
在所有node节点上操作,添加以下参数
vim /opt/kubernetes/cfg/kubelet
--cluster-dns=10.0.0.2 \ --cluster-domain=cluster.local. \ --resolv-conf=/etc/resolv.conf \
#重启kubelet 并查看状态
systemctl daemon-reload && systemctl restart kubelet && systemctl status kubelet
2.5 验证CoreDNS服务解析
2.5.1 使用dnstools测试效果
#在master上操作,注意:busybox不能用高版本,要用低版本测试。
kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
nslookup kubernetes.default
nslookup www.baidu.com
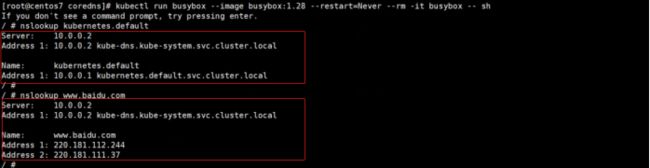
输出结果如上,说明coredns可以解析成功。
cat /etc/resolv.conf

如上,每个pod都会在resolv.conf文件中声明dns地址。
2.5.2 测试namespace域名互通
1.8.7小节已经在默认namespace:default中创建好了my-nginx,现在我们新建一个namespace:online,并创建online-nginx服务
1、创建namespace
kubectl create namespace online
2、部署online-nginx
cat >online-nginx.yaml <<EOF apiVersion: apps/v1 kind: Deployment metadata: name: online-nginx namespace: online spec: replicas: 2 selector: matchLabels: k8s-app: online-nginx template: metadata: labels: k8s-app: online-nginx spec: containers: - name: online-nginx image: nginx:1.9 ports: - containerPort: 80 EOF
kubectl create -f online-nginx.yaml
kubectl expose deploy online-nginx -n online
3、运行curl工具测试
kubectl run curl --image=radial/busyboxplus:curl --namespace="online" --restart=Never --rm -it
nslookup kubernetes.default
curl my-nginx.default
curl online-nginx
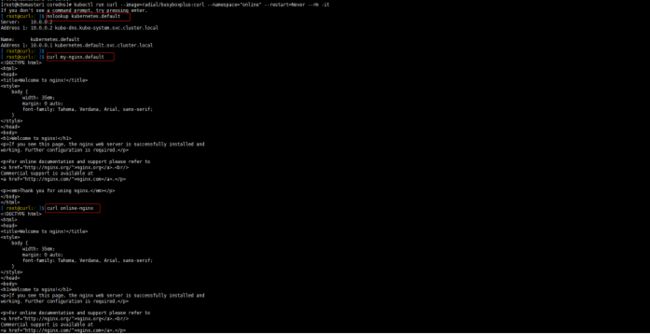
说明:也可以指定namespace,访问之前的my-nginx域名地址,也可以访问同一namespace的pod。说明在不同的namespace上是互通的。
2.6 访问容器报错解决
[root@centos7 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-dbddb74b8-s7lp5 1/1 Running 1 22h
nginx-dbddb74b8-znxz5 1/1 Running 1 22h
如下发现执行查看资源报错,不能进入容器。报错:
[root@centos7 ~]# kubectl exec -it nginx-dbddb74b8-s7lp5 sh
error: unable to upgrade connection: Forbidden (user=system:anonymous, verb=create, resource=nodes, subresource=proxy)
原因:2.7.4中kubelet.config定义了:没有进行身份验证方法的对kubelet的HTTPS端点的请求将被视为匿名请求,并提供用户名system:anonymous 和组system:unauthenticated。所以提示anonymous用户没有权限。
解决(官方推荐):启动apiserver时指定admin账户证书授权
1)配置 kube-apiserver
vim /opt/kubernetes/cfg/kube-apiserver
--kubelet-client-certificate=/opt/kubernetes/ssl/admin.pem \
--kubelet-client-key=/opt/kubernetes/ssl/admin-key.pem \
#重启 kube-apiserver
systemctl daemon-reload && systemctl restart kube-apiserver && systemctl status kube-apiserver
2)配置kubelet,从master复制apiserver中的ca证书到node上
vim /opt/kubernetes/cfg/kubelet
--client-ca-file=/opt/kubernetes/ssl/ca.pem \
#重启 kube-apiserver
systemctl daemon-reload && systemctl restart kubelet && systemctl status kubelet
三、部署高可用Ingress
3.1 Ingress简介
3.1.1需求
coredns是实现pods之间通过域名访问,如果外部需要访问service服务,需访问对应的NodeIP:Port。但是由于NodePort需要指定宿主机端口,一旦服务多起来,多个端口就难以管理。那么,这种情况下,使用Ingress暴露服务更加合适。
3.1.2 Ingress组件说明
使用Ingress时一般会有三个组件:反向代理负载均衡器、Ingress Controller、Ingress
1、反向代理负载均衡器
反向代理负载均衡器很简单,说白了就是 nginx、apache 等中间件,新版k8s已经将Nginx与Ingress Controller合并为一个组件,所以Nginx无需单独部署,只需要部署Ingress Controller即可。在集群中反向代理负载均衡器可以自由部署,可以使用 Replication Controller、Deployment、DaemonSet 等等方式
2、Ingress Controller
Ingress Controller 实质上可以理解为是个监视器,Ingress Controller 通过不断地跟 kubernetes API 打交道,实时的感知后端 service、pod 等变化,比如新增和减少 pod,service 增加与减少等;当得到这些变化信息后,Ingress Controller 再结合下文的 Ingress 生成配置,然后更新反向代理负载均衡器,并刷新其配置,达到服务发现的作用
3、Ingress
Ingress 简单理解就是个规则定义;比如说某个域名对应某个 service,即当某个域名的请求进来时转发给某个 service;这个规则将与 Ingress Controller 结合,然后 Ingress Controller 将其动态写入到负载均衡器配置中,从而实现整体的服务发现和负载均衡
整体关系如下图所示:
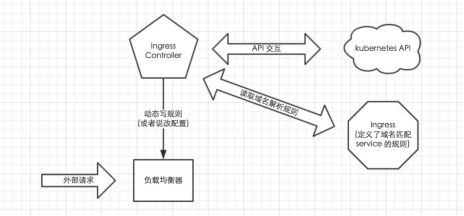
从上图中可以很清晰的看到,实际上请求进来还是被负载均衡器拦截,比如 nginx,然后 Ingress Controller 通过跟 Ingress 交互得知某个域名对应哪个 service,再通过跟 kubernetes API 交互得知 service 地址等信息;综合以后生成配置文件实时写入负载均衡器,然后负载均衡器 reload 该规则便可实现服务发现,即动态映射。
3.1.3 Nginx-Ingress工作原理
ingress controller通过和kubernetes api交互,动态的去感知集群中ingress规则变化;然后读取它,按照自定义的规则,规则就是写明了哪个域名对应哪个service,生成一段nginx配置;再写到nginx-ingress-control的pod里,这个Ingress controller的pod里运行着一个Nginx服务,控制器会把生成的nginx配置写入/etc/nginx.conf文件中;然后reload一下使配置生效。以此达到域名分配置和动态更新的问题。
说明:基于nginx服务的ingress controller根据不同的开发公司,又分为:
k8s社区的ingres-nginx(https://github.com/kubernetes/ingress-nginx)
nginx公司的nginx-ingress(https://github.com/nginxinc/kubernetes-ingress)
3.2.4 Ingress Controller高可用架构
作为集群流量接入层,Ingress Controller的高可用性显得尤为重要,高可用性首先要解决的就是单点故障问题,一般常用的是采用多副本部署的方式,我们在Kubernetes集群中部署高可用Ingress Controller接入层同样采用多节点部署架构,同时由于Ingress作为集群流量接入口,建议采用独占Ingress节点的方式,以避免业务应用与Ingress服务发生资源争抢。
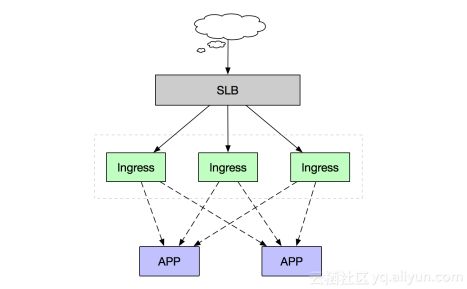
如上述部署架构图,由多个独占Ingress实例组成统一接入层承载集群入口流量,同时可依据后端业务流量水平扩缩容Ingress节点。当然如果您前期的集群规模并不大,也可以采用将Ingress服务与业务应用混部的方式,但建议进行资源限制和隔离。
3.2 部署高可用Ingress
ingress的高可用的话,要可以通过把nginx-ingress-controller运行到指定添加标签的几个node节点上,然后再把这几个node节点加入到LB中,然后对应的域名解析到该LB即可实现ingress的高可用。(注意:添加标签的节点数量要大于等于集群Pod副本数,从而避免多个Pod运行在同一个节点上。不建议将Ingress服务部署到master节点上,尽量选择worker节点添加标签。)
以下无特殊说明,都在master1上操作,参考:https://www.cnblogs.com/terrycy/p/10048165.html
3.2.1 给node添加标签
我这里在2个node上安装nginx-ingress-controller,只需给这两个node添加标签
kubectl label node k8snode1 ingresscontroller=true
kubectl label node k8snode2 ingresscontroller=true
#查看标签
kubectl get nodes --show-labels

附:
#删除标签
kubectl label node k8snode1 ingresscontroller-
#更新标签
kubectl label node k8snode1 ingresscontroller=false --overwrite
3.2.2 下载yaml部署文件
下载地址:https://github.com/kubernetes/ingress-nginx/tree/master/deploy,有如下几个yaml文件,我们只需要下载mandatory.yaml文件即可,它包含了其余4个文件的内容。
mkdir /opt/ingress && cd /opt/ingress/
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
3.2.3 修改yaml文件
1、修改Deployment为DaemonSet,并注释掉副本数
kind: DaemonSet #replicas: 1
说明:默认kind: Deployment,replicas: 1,即在1个节点上启动1个ingress-nginx controller Pod,所以需要修成DaemonSet,即为每一个节点都启动一个pod。
DaemonSet和Deployment区别:Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
2、启用hostNetwork网络,并指定运行节点
hostNetwork暴露ingress-nginx controller的相关业务端口到主机,这样node节点主机所在网络的其他主机,都可以通过该端口访问到此应用程序。
nodeSelector指定之前添加ingresscontroller=true标签的node
hostNetwork: true nodeSelector: ingresscontroller: 'true'
3、修改镜像地址,默认的镜像地址下载了几个小时都没下载好
registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:0.24.1
可提前在node上下载镜像
3.2.4 部署ingress
#部署
kubectl create -f mandatory.yaml

#查看ingress-controller
kubectl get ds -n ingress-nginx
kubectl get pods -n ingress-nginx -o wide

踩坑:pod无法创建,并且create的时候也没有任何错误。
参考网上文章:https://www.liuyalei.top/1455.html 后,有提示报错:Error creating: pods "nginx-ingress-controller-565dfd6dff-g977n" is forbidden: SecurityContext.RunAsUser is forbidden
解决:需要对准入控制器进行修改,取消SecurityContextDeny 的enable就行,然后重启apiserver:
vim /opt/kubernetes/cfg/kube-apiserver
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \
#重启 kube-apiserver
systemctl daemon-reload && systemctl restart kube-apiserver && systemctl status kube-apiserver
3.3 验证功能
3.3.1 创建测试用pod和server
vim nginx-static.yaml
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-static apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-static labels: name: nginx-static spec: replicas: 1 template: metadata: labels: name: nginx-static spec: containers: - name: nginx-static image: nginx:latest volumeMounts: - mountPath: /etc/localtime name: vol-localtime readOnly: true ports: - containerPort: 80 volumes: - name: vol-localtime hostPath: path: /etc/localtime --- apiVersion: v1 kind: Service metadata: name: nginx-static labels: name: nginx-static spec: ports: - port: 80 protocol: TCP targetPort: 80 name: http selector: name: nginx-static
#创建
kubectl create -f nginx-static.yaml
#查看服务和pod
可以看到部署到了k8smaster2(172.31.50.101)上

3.3.2 配置ingress
vim nginx-static-ingress.yaml
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: submodule-checker-ingress spec: rules: - host: nginx.weave.pub http: paths: - backend: serviceName: nginx-static servicePort: 80
#应用ingress规则
kubectl create -f nginx-static-ingress.yaml
#查看ingress规则
kubectl get ingress -o wide

3.3.3 访问
在其他端访问,需要修改hosts文件,比如修改master1的hosts,给ingress服务端的IP,指定到自定义的域名。
172.31.55.50 k8snode3 nginx.weave.pub
#测试能否解析
curl nginx.weave.pub

访问报错:504 Gateway time out,这是因为nginx连接时间超时,默认是60s,设置大一点。
参考:https://github.com/kubernetes/ingress-nginx/issues/2007
解决:修改nginx-static-ingress.yaml文件,添加标红处:
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: submodule-checker-ingress annotations: kubernetes.io/ingress.class: "nginx" nginx.ingress.kubernetes.io/proxy-connect-timeout: "14400" nginx.ingress.kubernetes.io/proxy-send-timeout: "14400" nginx.ingress.kubernetes.io/proxy-read-timeout: "14400" spec: rules: - host: nginx.weave.pub http: paths: - backend: serviceName: nginx-static servicePort: 80
重新应用
kubectl apply -f nginx-static-ingress.yaml
3.4 总结
1、在实际应用场景,常常会把多个服务部署在不同的namespace,来达到隔离服务的目的,比如A服务部署在namespace-A,B服务部署在namespace-B。这种情况下,就需要声明Ingress-A、Ingress-B两个Ingress分别用于暴露A服务和B服务,且Ingress-A必须处于namespace-A,Ingress-B必须处于namespace-B。否则Controller无法正确解析Ingress的规则。
2、集群内可以声明多个Ingress和多个Ingress Controller,一个Ingress Controller可以监听多个Ingress,Ingress和其定义的服务必须处于同一namespace。
3、快速扩容,随着业务流量不断增长,集群规模不断扩大,只需要简单地通过打标的方式来快速扩容Ingress接入层;然后再把这几个node节点加入到lb中,然后对应的域名解析到该lb即可实现ingress的高可用。
到这里ingress部署完成。
四、node增删
4.1 增加node方法
4.1.1 基本设置
执行 1.3.4-1.3.6 步骤
4.1.2 配置kubelet组件
执行1.7.3~1.7.7,1.8.3-1.8.4,1.8.7,2.4后,还需操作如下:
复制matser上/opt/kubernetes/ssl/ca.pem,到node相同目录
4.1.3 配置calico相关证书
复制matser上/opt/etcd/ssl/{ca.pem,server-key.pem,server.pem},到node相同目录,并重命名node上的etcd证书名称(calico网络需要该证书)
cp ca.pem etcd-ca && cp server-key.pem etcd-key && cp server.pem etcd-cert
重启kubelet组件
systemctl daemon-reload && systemctl restart kubelet && systemctl status kubelet
systemctl daemon-reload && systemctl restart kube-proxy && systemctl status kube-proxy
4.1.4 测试calico网络正常
master节点新建测试文件
cat >> test-nginx.yaml <<EOF apiVersion: apps/v1 kind: Deployment metadata: name: test-nginx spec: replicas: 1 selector: matchLabels: k8s-app: test-nginx template: metadata: labels: k8s-app: test-nginx spec: nodeSelector: kubernetes.io/hostname: "k8snode3" containers: - name: test-nginx image: nginx:1.9 ports: - containerPort: 80 EOF
#创建pod
kubectl create -f test-nginx.yaml
#创建服务
kubectl expose deploy test-nginx
#查看状态
kubectl get svc,pod --all-namespaces -o wide

如果异常,查看日志
kubectl describe pod/test-nginx-747548b77d-8cs65
报错: k8snode3 Failed create pod sandbox: rpc error: code = Unknown desc = [failed to set up sandbox container "360e03c13615b9ad0c1e6d9c7fca1b300311398c038ea6d6587d465fb956f250" network for pod "my-nginx-6ccc5d6cbd-q2v5w": NetworkPlugin cni failed to set up pod "my-nginx-6ccc5d6cbd-q2v5w_default" network: context deadline exceeded, failed to clean up sandbox container "360e03c13615b9ad0c1e6d9c7fca1b300311398c038ea6d6587d465fb956f250" network for pod "my-nginx-6ccc5d6cbd-q2v5w": NetworkPlugin cni failed to teardown pod "my-nginx-6ccc5d6cbd-q2v5w_default" network: context deadline exceeded]
解决:重启该node节点可解决。
4.1.5 测试coredns正常
kubectl run curl --image=radial/busyboxplus:curl --restart=Never --rm -it
curl test-nginx.default
4.1.6 测试ingress正常
vim test-nginx-ingress.yaml
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: test-checker-ingress annotations: kubernetes.io/ingress.class: "nginx" nginx.ingress.kubernetes.io/proxy-connect-timeout: "14400" nginx.ingress.kubernetes.io/proxy-send-timeout: "14400" nginx.ingress.kubernetes.io/proxy-read-timeout: "14400" spec: rules: - host: test-nginx.weave.pub http: paths: - backend: serviceName: test-nginx servicePort: 80
kubectl apply -f test-nginx-ingress.yaml
然后curl测试下
4.2 删除node方法
kubectl get nodes
kubectl cordon k8s-node1 #设置不可调度
kubectl drain k8snode1 --ignore-daemonsets --delete-local-data #驱离pod到其他节点
kubectl get pod --all-namespaces -o wide |grep k8snode1 #查看是否还有pod
kubectl delete node k8snode1 #删除节点
4.3 Node隔离与恢复
在硬件升级、硬件维护的情况下,我们需要将某些Node进行隔离,脱离k8s的调度范围。k8s提供了一套机制,既可以将Node纳入调度范围,也可以将Node脱离调度范围。
kubectl cordon k8s-node1 #将k8s-node1节点设置为不可调度模式
kubectl drain k8s-node1 #将当前运行在k8s-node1节点上的容器驱离
kubectl uncordon k8s-node1 #执行完维护后,将节点重新加入调度
4.4 删除顽固namespace
检查该namespace下是否还有资源:kubectl get all --namespace=ingress-nginx
删除资源:kubectl delete pods
然后编辑namespace:kubectl edit ns ingress-nginx
注释掉finalizers部分,保存即会删除该ns
再次查看已被删除:kubectl get ns