[深度学习论文笔记][Image Classification] ImageNet Classification with Deep Convolutional Neural Networks
1 Why CNN
[Motivation] Even a dataset as large as ImageNet cannot cover the immense complexity of the object recognition task. So our model should have lots of prior knowledge to compensate all data we do not have.
• Capacity can be controlled by varying their depth and breadth.
• Make strong and mostly correct assumptions about the nature of images (namely, stationarity of statistics and locality of pixel dependencies).
• Have much fewer connections and parameters compared with MLP and so they are easier to train.
2 Architecture
[In a Nutshell (60M Parameters)]• Input (3 × 227 × 227).
• conv1 (96@11 × 11, s4, p0, output 96 × 55 × 55).
• relu1, lrn1, pool1 (3 × 3, s2), output 96 × 27 × 27.
• conv2 (256@5 × 5, s1, p2), output 256 × 27 × 27.
• relu2, lrn2, pool2 (3 × 3, s2), output 256 × 13 × 13.
• conv3 (384@3 × 3, s1, p1), output 384 × 13 × 13.
• relu3.
• conv4 (384@3 × 3, s1, p1), output 384 × 13 × 13.
• relu4.
• conv5 (256@3 × 3, s1, p1), output 256 × 13 × 13.
• relu5, pool5 (3 × 3, s2), output 256 × 6 × 6 = 9216.
• fc6 (4096), relu6, drop6.
• fc7 (4096), relu7, drop7.
• fc8 (1000).
[Data Preparation]
• Rescale each image such that the shorter side has length 256.
• Crop the central 256 × 256 patch out.
• Substract the mean activity over the training set from each pixel.
[Input (Data Augmentation)] Random crop/Horizontal flips
• Random crop 227 × 227 patches and their horizaontal reflections from the 256×256 images and train the network on these 227×227 patches.
• During testing, extract five 224 × 224 patches (the four corners and the center) as well as their horizontal reflections (hence ten patches in all), and averaging the predictions.
• This scheme reduce the top-1 error by 1.5%.
[Color jittering]
• PCA on the set of RGB pixel values throughout the ImageNet training set.
• To each training image, jiter the image along the 3 principal components.
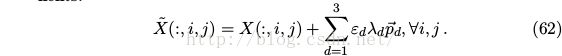
Where ε_d ∼ N(0, 0.1^2), λ_d ’s and p_d ’s are eigenvals and eigenvectors of the 3 × 3 convariance matrix of RGB pixel values.
• Each ε_d is drawn only once for all the pixels of a particular training image until that image is used for training again, at which point it is re-drawn.
• This scheme approximately captures an important property of natural images, namely, that object identity is invariant to changes in the intensity and color of the illumination.
• This scheme reduce the top-1 error by over 1%.
[Final notes]
• Transformed images do not need to be stored on disk because little compuation is needed to produce from original images.
• The transformed images are generated on the CPU while the GPU is training on the previous batch of images.
[ReLU] Six times faster than an equivalent network with tanh neurons.
[Local Response Normalization (LRN)]
• No need to input normalization with ReLUs.
• But still sum over N “adjacent” kernel maps at the same spatial position helps generalization.
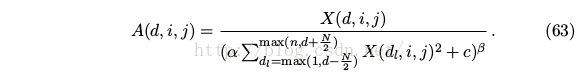
• This scheme reduce the top-1 error by 1.4%.
[Overlapping Pooling] This scheme reduce the top-1 error by 0.4% compared with non-overlapping pooling (2 × 2, s2).
[Dropout]
• Dropout reduces complex co-adaptations of neurons, since a neuron cannot rely on the presence of particular other neurons.
• Therefore, neurons are forced to learn more robust features that are useful in conjunction with many different random subsets of the other neurons.
• Dropout roughly doubles the number of iterations required to converge.
3 Training Details
SGD with momentum of 0.9.
• Batch size 128.
• Weight decay 0.0005.
• weights are initialized from N (0, 0.01 2 ), biases of conv1 and conv3 are initialized to 0, other biases are initialized to 1.
• Base learning rate is 0.01.
• Training 90 epoches.
• Divide the learning rate by 10 when validation error plateaued (3 times).
4 Results
[Results] Winner of ILSVRC-2012, for top-5 error
• 1 CNN: 26.2%.
• 5 CNNs: 16.4%.
• 1 CNN (pretrained on ImageNet 2011 and fine-tuning on ILSVRC-2012): 16.6%.
• 7 CNNs (pretrained on ImageNet 2011 and fine-tuning on ILSVRC-2012): 15.3%.
[FC7 Features] Small in l 2 distance: semantically similar.
It could be made efficient by training an auto-encoder to compress these vectors to short binary codes. This should produce a much better image
retrieval method than applying auto-encoders to the raw pixels, which does not make use of image labels and hence has a tendency to retrieve images
with similar patterns of edges, whether or not they are semantically similar.
[Depth is Really Important] Removing a single convolutional layer degrades the performance of 2% top-1 error.
5 References
[1]. T. Tasci and K. Kim. http://vision.stanford.edu/teaching/cs231b_spring1415/slides/alexnet_tugce_kyunghee.pdf.
[2]. F.-F. Li. https://www.ted.com/speakers/fei_fei_li.
[3]. F.-F. Li, A. Karpathy and J. Johnson. http://cs231n.stanford.edu/slides/winter1516_lecture7.pdf.
[4]. F.-F. Li, A. Karpathy and J. Johnson. http://cs231n.stanford.edu/slides/winter1516_lecture11.pdf.