网络信息检索(一)检索模型:布尔,向量,概率检索
文章结构
- 一、基本概念
- 1.为什么要建模?
- 2.什么是检索模型
- 3.检索模型的形式特征
- 二、General method-共享词袋
- 1.索引词
- 2.词的权重
- 3.经典的检索模型
- 三、布尔模型
- 1.Case
- 2.相似度测量
- 3.检索步骤
- 4.检索实例
- 5.布尔模型的讨论:
- 四、向量空间模型-最主流
- 1.相似度测量
- 2.向量空间模型要考虑的问题
- 3.向量空间和基向量
- (1)基向量的选择
- (2)向量系数
- 4.TF-IDF权重方法
- (1)Tf因子:词频:文档d中k出现的频率
- (2)Idf因子:逆向文件频率:文档集合中词k出现的频率的倒数
- (3)权重方法
- (4)含义
- (5)查询矢量
- 5.相似度计算
- (1)余弦相似度 OR 内积
- 6、向量模型的使用总结
- 五、概率模型-最有可能的发展方向
一、基本概念
1.为什么要建模?
模型是一个过程或者对象的抽象,用于研究属性、得出结论、做出预测。结论的质量依赖于模型表示现实的相近程度
结论的质量依赖于模型表示现实的相近程度,如机器人
2.什么是检索模型
IR的核心问题:预测哪些文档是相关的,哪些文档是不相关的。主要工作在于排序这个核心的问题,如何计算这个排序从而处理文档的相关性。
检索模型描述了如下这些细节
文档表示( Document representation) -对库中的文档进行表示
查询表示( Query representation) -对用户输入的查询进行表示
比较方法(Comparison function)-解决如何对文档进行排序
不同的减缩模型使用的相关性的概念都是不相同的。
3.检索模型的形式特征

二、General method-共享词袋
检索过程判断相关信息十分困难,用户需求十分模糊,包括了上下文,需求等信息,必须尽量简化。
(1)共享词袋假设-最基础的假设-以词决定相关性
所有的词(文档、查询)都来自同一个字典,当二者的某些词相同,就被认为相关。
(2)词袋方法-以词为主(语法结构之类的无关)
把每个文档看作一个装满词的词袋,信息检索就是是文档中的词与查询中的词的匹配。
1.索引词
索引词的定义:从列表、文件或词典中提取的关键性的字(word)或词(phrase),可以反映对材料内容的主要或次要层次上的描述。
一般是文档中的名词,但是名词的识别本来就是一个特别艰巨的任务,因此一般只是去掉停止词,得的地之类的。
现在假设除了停止词以外都是索引词(全文表示),一般数据存储都没问题。
2.词的权重
不是所有词能表达文档的主题思想,以权重来衡量某个词对这篇文档的重要性。注意某个词的权重只在对应的文档中有意义。权重量化了索引词表示文档内容的能力。

3.经典的检索模型

他们如何进行最核心的两个表示一个比较过程?
三、布尔模型
基于集合理论的简单检索模型。
索引词进行二值化处理,出现的词权重为1,不出现则权重为0。
查询是一个布尔表达式。(and or not)比如,我查的词包括信息和学习,信息或者学习等。
And or not对计算机而言有点难以理解,我们一般把一个普通的查询表示为若干个析取范式的合取,以便计算机理解。
1.Case
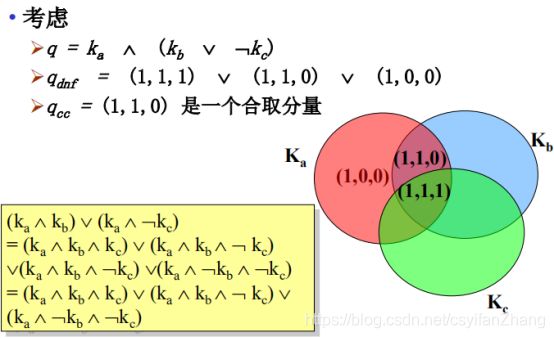
2.相似度测量

文档满足布尔查询,那么相似度为1,否则相似度为0,没有第三种可能。
3.检索步骤
第一步:将文档集中的每个文档表示为索引词的布尔向量-词库的表示
第二步:将查询表示为析取范式-查询的表示
第三步:根据相似度计算公式计算各文档与查询的相似度(0 OR 1);-比较
第四步:如果相似度为1,表示匹配,可将该文 档作为结果输出;如果相似度为0,表示不匹配,认为该文档不满足用户的需求。–输出结果文档
他可以完成两个表示一个比较的工作,只是不能完成排序,只有二值化的输出这个缺点。
4.检索实例

5.布尔模型的讨论:
(1)优点
AND可以表示概念之间的关系。
OR可以表示可选择的词汇。(同义词)
NOT可以表示反义词。
准确,高效(0-1表示,析取范式效率很高),简单优美。
(2)缺点
自然语言是复杂的。AND挖掘了一些不存在的关系,在不同句子,段落中的词被强行绑定在一起。用OR猜测词语是非常困难的,选择近义词也是需要人工训练的。猜测要排斥的词汇更加困难。
全部都是精确匹配:基于二值决策,不存在部分匹配,但IR其实是一个模糊的查询。经常检索出太少或者太多的文档。
结果不排序:无排序的机制,只有相关或者不相关,没有相关级别的变化。
布尔表示查询:让用户使用or not and表示查询。用户负担过大,因此用户构造的查询通常过于简单。
四、向量空间模型-最主流
也称矢量模型。主要思想:在高维空间中,每个东西(文档、查询、语词)都可以表示为一个向量,如:
![]()
每个索引词具有一个非二值化的权重,这些权重可以用来计算查询和文档间的相似程度。结果排序提供更好的匹配或者部分匹配。
1.相似度测量
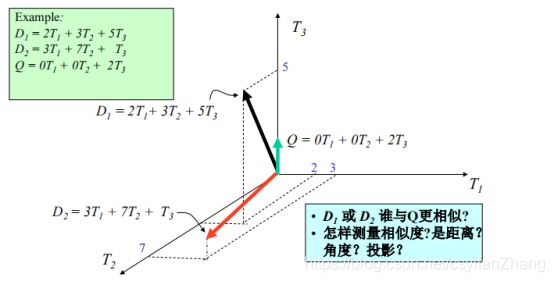
2.向量空间模型要考虑的问题
怎样选择基本的向量(维数)?
• 怎样把对象转换为向量? 语词( Terms) 文档( Documents) 查询( Queries)
• 怎样沿着维选择幅度?
• 怎样比较向量空间中的对象?
3.向量空间和基向量
形式上,向量空间由一组线性不相关的基向量定义。
和向量空间模型中的维度和方向对应,我们希望向量空间是相对静止的,基向量的个数不能经常变化,维度也不能太高。
必须是正交而且线性不相关的。
(1)基向量的选择

所谓的正交,是基与基完全不相关,但是对词语而言往往是具有相关性的,孙杨–游泳,姚明–篮球。然而最终还是使用了词语作为基向量,毕竟一个词对少部分词相关,对大部分词还是不会相关的。
(2)向量系数
向量沿每一维的维度(也就是对每个词的权重)
代表词语出现,重要度或者相关度、
如何设置词语的权重?布尔表示?
4.TF-IDF权重方法
权重=词频?

只考虑词频就够吗?越多就越有意义嘛?但是the,an等词在没一个英文文档都存在很多次,没有太大的意义。因此文档可以用罕有词(在我这里大量出现,在其他地方很少出现)很好的描述,
高的词频是一个很好的证据,低的文档频率使其更有价值。(在本文出现的次数越多,在其他文章出现的越少,对本文越重要。对于 A and B, A and C两个检索,那么B对于第一个显得尤为重要,意义更大,因为A是二者都有的。)
(1)Tf因子:词频:文档d中k出现的频率

(2)Idf因子:逆向文件频率:文档集合中词k出现的频率的倒数

(3)权重方法

(4)含义

(5)查询矢量

加0.5是因为早期的文档库很少,freq参数很可能为0,加0.5之后可能使得有些没有或者很少出现过的词语也能搜索出相关文档,现在的文档库非常的大,一般不需要加0.5。
5.相似度计算
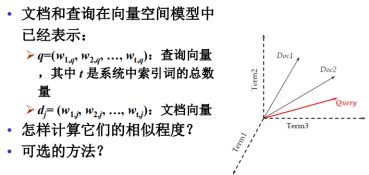
(1)余弦相似度 OR 内积
内积与文档的长度有关,内积使用长度规范化之后,就成了余弦相似度。

6、向量模型的使用总结

(1)优点
简单,基于数学的方法,把所有的东西都向量化,使用向量之间的夹角进行比较。
能够考虑词频的权重,任何形式的权重都能结合进来,既考虑了本地词频也考虑了全局词频。
提供部分匹配机制和排序输出结果。
(2)缺点
丢掉了语义信息,语境信息(没办法)
假设词之间是相互独立的,基向量就是这样。
缺乏布尔模型的控制能力:如果 “A B”是个双字查询,第一个文档频繁出现A但不包含B,第二个文档包含A也包含B,但出现次数少,那么,可能第一个文档被选中的机会大过第二个
五、概率模型-最有可能的发展方向
概率检索模型是当前信息检索领域效果最好的模型之一,它基于对已有反馈结果的分析,根据贝叶斯原理为当前查询排序。
一篇很好地解释