1、结论
测量误差(测量)服从高斯分布的情况下, 最小二乘法等价于极大似然估计。
2、最大似然估计概念
最大似然估计就是通过求解最大的(1)式得到可能性最大的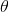 作为真的估计,其中 L 函数称为参数的似然函数,是一个概率分布函数。
作为真的估计,其中 L 函数称为参数的似然函数,是一个概率分布函数。
似然估计的思想是:测量值 X 是服从概率分布的,求概率模型中的参数,使得在假设的分布下获得该组测量出现概率最大:
例如:通过一次测量得到1.9、1.9、2.0、2.1、2.0、1.9、1.5、2.5、2.0、2.0,
通过直觉我们发现这组测量比较符合期望为2的高斯分布。
要不然,为什么取值都在2附近呢,为啥测量数据中没有(很少)1.0、5.0呢?也就是说,可以认为我的这些测量
是符合某个概率分布的(这个例子中为高斯分布),测量值中得到2附近值的概率比较大。
例如:一个箱子里有红球和黑球,通过10次放回抽取实验得到的结果为:8次黑球、2次红球。问箱子中黑球的比例?
这个例子中箱子里只有红球和黑球,可以假设黑球的比例为 p ,那么红球的概率为(1-p),
那么10次实验中8次黑球、两次红球的概率为:。通过即可求出 p = 0.8。
3、最大似然估计求法
a、样本从高斯分布中采样获得。高斯概率分布函数为:
通过测量获得 N 个测量值,,它们符合高斯概率分布,此时它们的似然估计为:
通过最大化似然估计函数 L ,即可求出 、
、 :
:
但是,(4)式中目标函数为乘积的形式,求导结果复杂,这里对目标函数取对数,这样做不影响单调性:
(4)中似然函数取对数后的函数称为似然函数,通过对似然函数取对数可以简化似然函数的求解。
对似然函数求导并等于0,即可求出最大似然下的、:
得到:
b、服从泊松分布和均匀分布下的最大似然估计可参阅:http://blog.sciencenet.cn/blog-491809-400893.html
c、最大对数似然估计一般求解过程:
写出最大似然估计表达式:
对每个求偏导并等于0:
d、与最大似然估计对等的还有一个 矩估计方法。
矩估计法,是利用样本矩来估计总体中相应的参数。矩估计法的基本思想是用样本矩代替总体矩。
最简单的矩估计法是用一阶样本原点矩来估计总体的期望而用二阶样本中心矩来估计总体的方差。
4、最大似然估计与最小二乘之间的关系
这部分内容来自:http://www.zhihu.com/question/20447622
本部分内容需要以下知识:
a、高斯分布、拉普拉斯分布、最大似然估计、最大后验估计(MAP)
b、按照李航博士的观点,机器学习三要素为:模型、策略、算法。一个模型有多种求解策略,
每一种求解策略可能最终又有多种计算方法。下面的内容主要讲解算法。
从概率论的角度:
a、最小二乘(Least Square)的解析解可以用Gaussian分布以及最大似然估计求得
b、Ridge回归可以用Gaussian分布和最大后验估计解释
c、LASSO回归可以用Lapace分布和最大后验估计解释
假设线性回归模型具有如下形式:
其中,,误差。
当前已知,,如何求 呢?
呢?
策略1:假设 ,即
,即 ,那么用最大似然估计推导:
,那么用最大似然估计推导:



公式(11)式就是最小二乘。
策略2:假设,,那么用最大后验估计推导:
公式(14)式就是Ridge回归。
策略3:假设,,同样采用后验估计推导:
公式(17)式LASSO。