2020中兴捧月·图灵赛道TOP2分享·加密文本匹配
摘要
文本匹配(text matching)技术广泛应用于信息检索、智能问答、对话等业务场景。尽管当前该技术已经相对有了长足的进步,但是随着领域的拓展,标注数据的缺乏,以及用户描述上的多样性,如何精准的匹配用户意图,变得越来越困难。随着5G时代的应用与发展,文本匹配技术应用越来越广泛,要求越来越高。
针对赛题数据,笔者知道所有文本数据都经过清洗与脱敏处理,被统一分词并编码成词表ID序列。为此,采用预训练模型的方式,先对数据无监督学习,预训练出一个基于比赛方提供的2G无标签数据的BERT[1]模型;在模型构建部分使用了得到的预训练模型,并通过预训练模型多层表示的动态权重融合方式对预训练模型进行修改,而后下接BILSTM和GRU两种异构模型来实现文本匹配;对于模型融合部分,用多异构单模的结果投票的方式融合,最终线上最高成绩为89.100,线上的最终排名为第2名。
关键词
文本匹配,预训练模型,动态融合,多异构模型融合
1 赛题分析
赛题给定一定数量的标注语料和大量的未标注语料,要求选手设计算法和模型预测给定句对语义层面的关系,实现精准匹配,官方提供的数据中包含25万的标注数据与2G大小的的无监督数据以及1.2万条测试集数据,其中数据字段如图1所示。

图1:数据字段
针对赛题数据集,本团队进行了较为详细的统计和分析。数据集中2G大小的无监督数据长度都在512以上,训练集与测试集的文本长度则在64以内。
2 数据处理
2.1无监督数据
由于训练与测试文本的长度均小于64以及硬件设备GPU性能受限,笔者通过滑动窗口(窗口大小为64),滑动切割出长度为128的文本作为预训练BERT的语料。因为滑动窗口小于128,我们在获取语料过程中,也也赋予了上下文信息给语料,更好得利用了文本信息。
笔者使用google开源的BERT预训练代码,在16G显存的GPU下对得到的128长度的语料进行预训练180W步,并按照没30W万步进行保存,得到多个阶段的预训练模型。其中,由于NSP(Next Sentence Prediction)在后续发表的预训练文章中如roberta[2]等,被证明对预训练下游任务并没有产生有益的价值。因此,笔者在预训练BERT的过程中,删除了NSP任务。
BERT原文指出,BERT预训练的注意力与序列长度成平方的关系,原文作者先是对128长度的文本进行90%的步数预训练,而后再对512长度的文本进行10%步数的预训练。笔者后来也想效仿这种做法,在后续60W步的预训练过程中采用256长度的语料进行预训练,但是由于比赛时间有限,只是生成了256长度的语料,并没有时间进行预训练。
2.2有监督数据
因为训练集与测试集都是加密文本,因此,笔者无从得知文本中是否含有噪声,加之文本长度只有64,我们只需将其预处理好,灌入我们训练好的预训练模型中进行文本匹配即可。
3模型方法
笔者尝试使用得到的预训练模型,并分别下接Average Pooling、BiGRU与BILSTM三种结构来构建文本匹配模型。最后,我们采用异构单模的结果投票进行多模融合。
3.1 BERT-Average Pooling
该异构单模推断速度快,且效果与后面介绍的两个异构单模成绩相当,并可以增加后期模型融合异构单模的多样性,模型结构如图二所示。
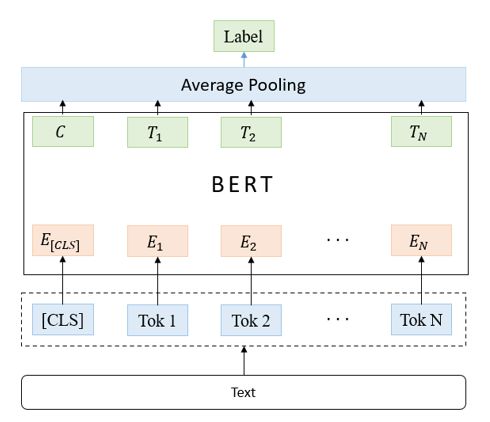
图2:BERT-Average Pooling
3.2 BERT-BiGRU与BERT-BiLSTM
BERT预训练模型学习到的token向量输入这两种模型进行进一步学习,让模型更好的理解文本的上下关系,最终通过averagepooling层并softmax输出分类结构。它们在增加异构单模多样性的同时,性能相比3.1节介绍的模型稍强,模型结构如图3所示。

图3:BERT-BiGRU/BiLSTM-Average Pooling
3.3 BERT多层表示的动态权重融合
Ganesh Jawahar等人[3]通过实验验证了BERT每一层对文本的理解都有所不同。为此,我们对BERT进行了改写,将BERT的十二层transformer生成的表示赋予一个权重,权重的初始化如公式(1)所示,而后通过训练来确定权重值,并将每一层生成的表示加权平均,再通过一层全连接层降维至512维如公式(2)所示,最后结合之前的Bi-GRU和Bi-LSTM模型来获得多种异构单模。BERT多层表示的动态权重融合结构如图4所示。其中为BERT每一层输出的表示,为权重BERT每一层表示的权重值。

图4 BERT动态融合
最后,笔者通过实验发现,BERT的动态融合作为模型embedding的成绩会优于BERT最后一层向量作为模型的embedding。因此,本次比赛笔者使用的异构单模均是使用BERT的动态融合向量作为模型的embedding。
3.4模型融合
通过前几节的介绍,我们得到了多种类别的异构模型,并通过投票的方式进行融合。
4总结与展望
本次比赛笔者将预训练BERT模型,Bi-GRU和BI-LSTM多模异构融合,BERT多层表示动态融合等方法,最终在线上排名第2名。
针对当前方案,笔者未来希望在如下几个方面进行改进:
1) 正如前文所提到的,笔者的预训练并不算充分,在未来条件允许的情况下,笔者将继续预训练长度为256的语料,让预训练模型学习得更加充分。
2) 对BERT模型进行剪枝和蒸馏,以降低模型的时间与空间复杂度。
5 求个赞
关注我的微信公众号【阿力阿哩哩】~不定期更新相关专业知识~
喜欢就点个赞吧~
致谢
感谢中兴提供的这次比赛机会,让我们在参赛的过程中不断进步成长,收获新的知识。感谢自己的不懈努力,使得比赛有了一个较为圆满的结果。最后再次感谢中兴的工作人员努力为比赛营造了公平公正的竞赛环境。
参考文献
[1] Jacob Devlin, Ming-WeiChang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectionaltransformers for language understanding. arXiv preprint arXiv:1810.04805.
[2] Liu Y , Ott M , Goyal N , etal. RoBERTa: A Robustly Optimized BERT Pretraining Approach[J]. 2019.
[3] Ganesh Jawahar, BenoîtSagot, Djamé Seddah. What does BERT learn about the structure of language?. ACL2019 - 57th Annual Meeting of the Association for Computational Linguistics,Jul 2019, Florence, Italy. ffhal-02131630