步骤:
影评文字——数据预处理——features(特征)——深度学习模型——预测——预测结果。
步骤1:读取IMDB数据集;
步骤2:建立token字典;
步骤3:使用token字典将“影评文字”转化为“数字列表”
步骤4:截长补短让所有“数字列表”长度都是100
步骤5:Embedding层将“数字列表”转化为"向量列表";
步骤6:将向量列表送入深度学习模型进行训练
具体:
步骤1:读取IMDB数据集;
下载数据集:网址:http://ai.stanford.edu/~amaas/data/sentiment
1.导入所需模块
import urllib.request #导入urllib模块,将用于下载文件
import os #导入os模块,用于确定文件是否存在
import tarfile #用于解压文件
2.下载数据集
url="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz" #设置下载地址
filepath="data/aclImdb_v1.tar.gz" #设置存储文件的路径
#判断文件不存在就会下载文件
if not os.path.isfile(filepath):
result=urllib.request.urlretrieve(url,filepath)
print('downloaded:',result)
结果截图:

3.解压压缩下载文件
if not os.path.exists("data/aclImdb"): #判断解压压缩文件是否存在
tfile = tarfile.open("data/aclImdb_v1.tar.gz", 'r:gz') #打开压缩文件
result=tfile.extractall('data/') #解压文件到data目录中

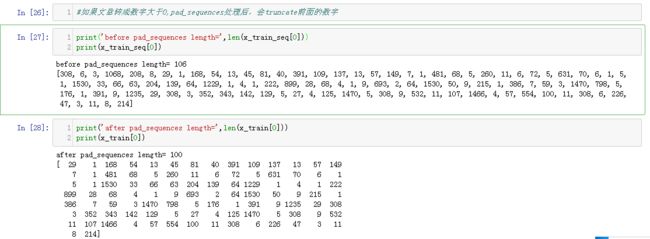
4. 读取数据集
(1)导入所需模块
from keras.datasets import imdb
from keras.preprocessing import sequence #导入sequence模块,用于让”数字列表“长度一致
from keras.preprocessing.text import Tokenizer #导入tokenizer模块,用于建立字典
(2) 创建rm_tag函数删除文字中的HTML标签
import re #导入Regular Expression 模块
def rm_tags(text): #创建rm_tags函数,输入参数text文字
re_tag = re.compile(r'<[^>]+>') #创建re_tag为正规表达式变量
return re_tag.sub('', text) #将文本中符合正则表达式条件的字符替换成空字符
(3)创建read_files函数读取IMDb文件目录
【注:acImdb文件夹分为:train文件夹(12500正(pos),12500负(neg))和test集】
import os
def read
_files(filetype): #读取训练数据时,filetype参数会传入”train“;测试数据传入test
path = "data/aclImdb/"
file_list=[] #创建文件列表
positive_path=path + filetype+"/pos/" #设置正面评价的文件目录为 positive_path
for f in os.listdir(positive_path): #使用for循环将 positive_path目录下所有文件加入file_list
file_list+=[positive_path+f]
#负面评价
negative_path=path + filetype+"/neg/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f]
#显示当前读取的filetype(test或train)目录下的文件个数
print('read',filetype, 'files:',len(file_list))
all_labels = ([1] * 12500 + [0] * 12500)
all_texts = []
for fi in file_list: #fi读取file_list所有文件
with open(fi,encoding='utf8') as file_input: # 打开文件
all_texts += [rm_tags(" ".join(file_input.readlines()))] # file_input.readlines()读取文件;join连接文件内容,rm_tags删除tag,最后加入all_texts list
return all_labels,all_texts
(4) 读取INDb数据目录
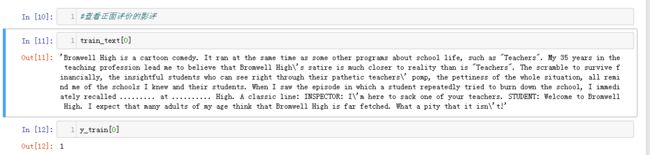
y_train,train_text=read_files("train")
y_test,test_text=read_files("test")
结果:训练集和测试集各25000项文字和25000项标签(1正0负),其中正:0-12499;负:12500-24999

查看IMDB数据结果截图:
步骤2:建立token字典
深度学习模型只能接受数字,所以我们将“影评文字”转化为“数字列表”。
要如何转化呢?当我们把一种语言翻译成另一种语言,必须要有字典。相同的,文字转化为数字,也必须有字典。Keras提供了Tokenizer模块,类似字典功能。
1.建立token
token = Tokenizer(num_words=2000) #建立一个有2000单词的字典
token.fit_on_texts(train_text) #按单词出现次数排序,排序前2000的单词会列入词典中
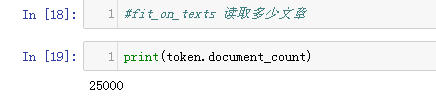
2.查看token读了多少文章
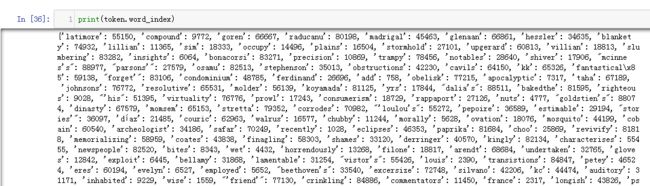
3.查看token.word_index属性
步骤3:使用token字典将“影评文字”转化为“数字列表”
建立token字典后,就可以使用token.word_index字典将文字转化为数字列表。
1.使用token.texts_to_sequences将文字转换为数字
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
2. 查看转化为sequences之后的结果

步骤4:截长补短让所有“数字列表”长度都是100
因为每一则影评文字的字数都不固定,有些170字,有些80字,转换成”数字列表“字数也不固定。
而后续要将数字列表转换为向量列表来学习,所以长度必须固定。
方法:截长补短
1. 使用sequnences.pad_sequences方法截长补短
x_train = sequence.pad_sequences(x_train_seq, maxlen=100)
x_test = sequence.pad_sequences(x_test_seq, maxlen=100)
2.影评文字转化为数字列表后,长度大于100截去
3.如果文章转成数字不足100,pad_sequences处理后,前面会加上0