
分析背景
一家公司负责人想要知道为什么最近公司好多有经验的员工选择辞职,并且预测哪些员工可能离职?
数据来源
Kaggle-HR Analytics
数据说明
此数据为虚拟数据
分析步骤
- 获取数据, 并对数据进行读取
- 了解数据格式, 大小, 内容
- 对数据异常值与缺失值进行清洗处理
- 对数据进行描述性分析
各维度下数据的分布情况
- 对数据进行探索性分析
维度两两之间的关系, 对比分析。
分析过程
1. 获取数据, 并进行读取。
我们从Kaggle上下载数据, 将数据保存到本地, 并用python对数据进行读取。
- 导入数据包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
% matplotlib inline
import seaborn as sns
- 读取数据, 并命名为df
df = pd.read_csv('C:/Users/zhangyu/Desktop/data_test/HR_comma_sep.csv')
2. 了解数据, 大小, 类型, 内容
-
查看数据的大小
df. shape
(14999, 10)
数据有14999行, 10列
-
读取数据前5行
df.head()
 数据前5行
数据前5行
-
读取数据后5行
df.tail(5)
 数据后5行
数据后5行
-
查看数据类型
df.dtypes
satisfaction_level float64
last_evaluation float64
number_project int64
average_montly_hours int64
time_spend_company int64
Work_accident int64
left int64
promotion_last_5years int64
sales object
salary object
dtype: object
-
查看sales列中的唯一值
df['sales'].unique()
array(['sales', 'accounting', 'hr', 'technical', 'support', 'management',
'IT', 'product_mng', 'marketing', 'RandD'], dtype=object)
-
查看salary列中的唯一值
df['salary'].unique()
array(['low', 'medium', 'high'], dtype=object)
3. 对数据进行清洗处理
-
查看数据是否有缺失值
df.any()
satisfaction_level True
last_evaluation True
number_project True
average_montly_hours True
time_spend_company True
Work_accident True
left True
promotion_last_5years True
sales True
salary True
dtype: bool
返回False代表数据有缺失值, 返回True代表数据无缺失值, 此数据源无缺失值。
-
对数据列名进行更换,以便更好的阅读
df = df.rename(columns = {
'satisfaction_level' : '员工满意度', 'last_evaluation' : '考核评分', 'number_project' : '项目数量', 'average_montly_hours':'每月在公司工作时间',
'time_spend_company' : '司龄', 'Work_accident':'工作事故', 'left':'是否离职', 'promotion_last_5years':'五年内是否升职', 'sales' : '部门', 'salary' : '薪水'})
df.head()
 列名更换
列名更换
-
将部门和薪水内容用数值代替
部门和薪水列内的内容是字符而不是数字, 我们要将其列内的字符分别用数字来代替, 以便于后期更好的进行统计分析。
df['部门'].replace(['sales', 'accounting', 'hr', 'technical', 'support', 'management','IT', 'product_mng', 'marketing', 'RandD'],[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
inplace = True)
# inplace = True , 原数据也会改变
df['薪水'].replace(['low', 'medium', 'high'],[1, 2, 3], inplace = True)
df.head()
 字符用数字进行替换
字符用数字进行替换
4. 对数据进行描述性分析
-
对数据整体进行基本的描述统计
#round(2)保留小数点后两位
#T行变列, 列变行
df.describe().round(2).T
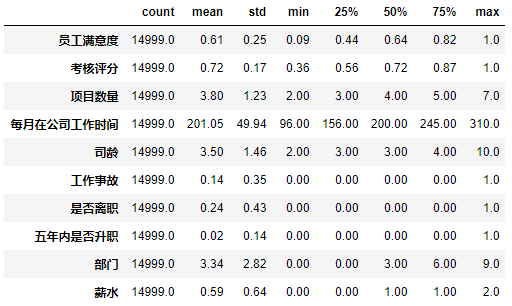 描述统计
描述统计
-
数据中在职与离职人数占比
# value_counts 计算每列中各数字出现的次数
在离职占比 = df['是否离职'].value_counts()/ 14999
在离职占比
0 0.761917
1 0.238083
Name: 是否离职, dtype: float64
得知:
在职人数占总人数的76.2%, 离职人数占总人数的23.8%
-
数据中不同薪水占比
不同薪水占比 = df['薪水'].value_counts()/ 14999
不同薪水占比
0 0.487766
1 0.429762
2 0.082472
Name: 薪水, dtype: float64
得知:
数据中薪水较低的人数占48.8%, 薪水中等的人数占43%, 拿高薪水的人数只占8.2%。
-
在职与离职员工在不同维度下的平均值对比
# 用groupby 函数对数据进行分组计算
groupby = df.groupby('是否离职').mean()
groupby
 对比
对比
从数据中, 我们可以看出:
离职员工比在职员工 的平均项目数量更多, 每月在公司工作时间更长,工作事故更少, 升职机率更低,薪水更低, 员工满意度也低。 那是否就说明离职员工受到了不公正的待遇呢, 我们需要从更多的维度对比来说明。
5. 对数据进行探索性分析
-
维度两两之间的关系
通过计算得出两两维度之间的相关性
df['考核评分'].corr(df['每月在公司工作时间'])
0.33974179983835895
考核评分与每月在公司工作时间之间的相关性约为0.34, 属于中度相关
展现数据全部维度之间的相关系
corr = df.corr()
corr
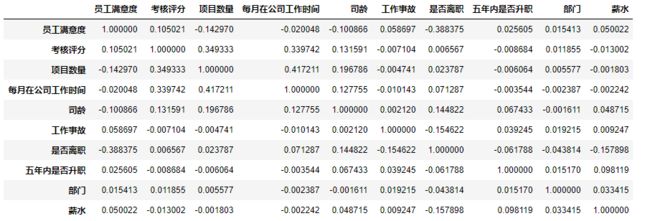 数据维度之间的相关性
数据维度之间的相关性
从上表可以得出:
- 工作事故与五年内是否离职两个维度与其他维度之间的相关系数较低, 将数据中工作事故和五年内是否升职两列删除
-
删除两列
del df['工作事故']
del df['五年内是否升职']
-
用热力图来展现
数值体现相关性不是很直观, 我们可以用热力图来直观展现维度之间的相关性。
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 显示负号
plt.rcParams['axes.unicode_minus']=False
corr = df.corr()
sns.heatmap(corr)
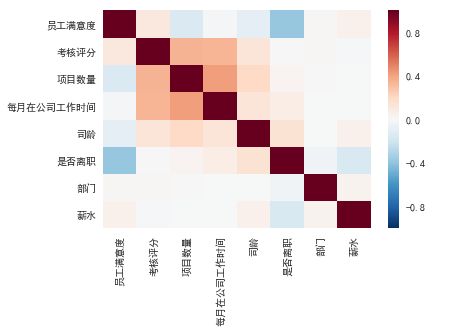 数据维度间的热力图
数据维度间的热力图
从图中我们可以看到:
- 每月在公司工作时间与项目数量、考核评分 之间的相关性较高,且呈正相关
- 是否离职与员工满意度 之间相关性较高, 且呈负相关。
- 员工对公司的满意度越低, 员工更容易离职。
-
项目数量与是否离职之间的关系
使用柱形图来对不同项目数量在离职员工数量进行对比
ax = sns.countplot(x="项目数量", hue="是否离职", data=df, palette="Set2")
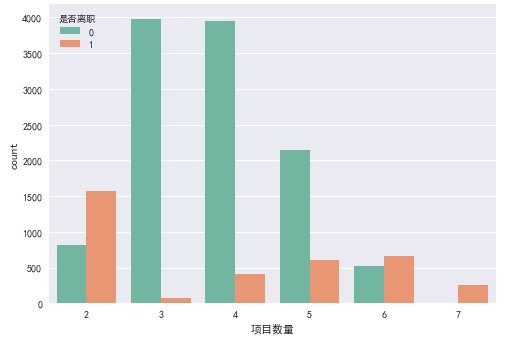 项目数量与是否离职之间关系图
项目数量与是否离职之间关系图
从图中可以得出:
- 当项目数量为2,6,7时, 员工更容易离职。
- 项目数量为7 的员工全部离职
- 当项目数量在3个以上时, 随着项目数量的增加, 员工更容易离职
思考:
- 为什么项目数为2的员工更容易离职, 是因为不努力工作的原因吗, 工作环境是什么样的。
- 为什么当项目数量在3个以上时, 项目增加,员工更容易离职, 是因为项目越多,公司加班越严重,工作太累了吗?
- 为什么项目数量为7 的员工全部离职
-
项目数量与员工在公司度过时间之间的关系
从计算的相关系数得知: 项目数量与考核评分习惯系数为0.42, 呈中度相关。 我们用箱形图来进行对比说明。
ax = sns.boxplot(x = '项目数量', y = '每月在公司工作时间',hue = "是否离职", data = df, palette = "Set2")
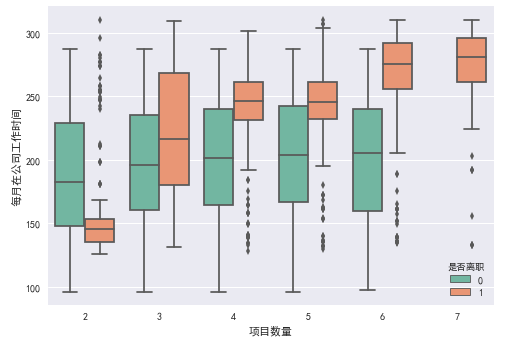 项目数量与工作时间关系图
项目数量与工作时间关系图
从图中可以得知:
- 当项目数量为2时, 离职员工的每月工作时间远远小于在职员工
- 在职员工随着项目的增加, 每月在公司度过的时间并不会发生过大的变化
- 离职员工随着项目的增加, 每月在公司度过的时间会不断增加
思考:
- 为什么随着项目的增加,离职员工每月工作时间会大于在职员工?
-
项目数量与考核评分之间的关系
从计算的相关系数得知: 项目数量与考核评分习惯系数为0.35, 呈中度相关。 我们用箱形图来进行对比说明。
ax = sns.boxplot(x="项目数量", y="考核评分", hue="是否离职",data=df, palette="Set3")
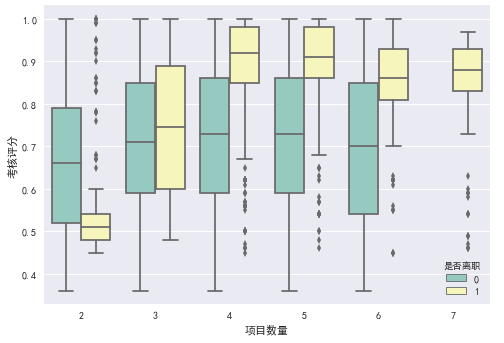 项目数量与最终评价之间的关系
项目数量与最终评价之间的关系
从图中我们可以看出:
- 当项目数量较小时, 离职员工的最终评分远远低于在职员工的评分,说明评分较低的员工更倾向于离开公司
- 读项目数量为3-6个, 在职员工和离职员工完成相同项目的情况下, 离职员工的评分更高
- 考核评分 与员工的项目数量和每月工作时间有一定的关系, 两个图非常相像。
思考:
- 相同项目数量下, 离职员工比在职员工评价更高, 对员工的评价是依据每月工作时间吗?
-
是否离职与员工满意度之间的关系
通过员工满意度的概率密度分布来反映入离职员工的满意度分布, 需要用到核密度估计图。
# 提取在职员工的满意度
df_loc0 = df.loc[(df['是否离职'] == 0), '员工满意度']
# 提取离职员工的满意度
df_loc1 = df.loc[(df['是否离职'] == 1), '员工满意度']
# 用kdeplot 绘制图形
ax = sns.kdeplot(df_loc0, shade = True, label = '在职')
ax = sns.kdeplot(df_loc1, shade = True, lable = '离职')
 在离职员工满意度分布
在离职员工满意度分布
从图中可以看出:
- 离职员工的满意度分为三大部分,0-0.2:极度不满意, 0.25-0.5:比较不满意, 0.7-0.9:很满意。
- 在职员工的满意的主要集中在0.5-0.9, 满意度较高。
思考:
在离职员工中, 极度不满意的员工主要是什么类型, 为什么满意度较高的员工也选择了离职。
-
是否离职与考核评分之间的关系
# 将在职员工的考核分提取出来
df_loc0 = df.loc[(df['是否离职'] == 0), '考核评分']
df_loc0
# 提取离职员工的考核评分
df_loc1 = df.loc[(df['是否离职'] == 1), '考核评分']
df_loc1
# 用概率密度图将密度分布显示出来
ax = sns.kdeplot(df_loc0, shade = True, label = '在职')
ax=sns.kdeplot(df_loc1, shade = True,label='离职')
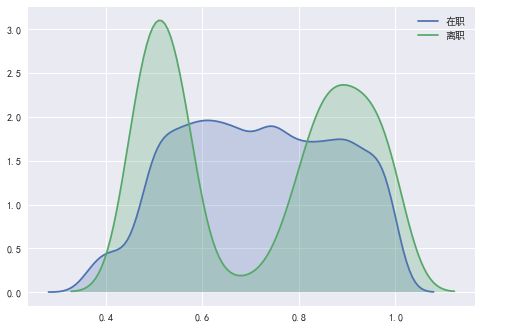 在离职员工评分分布
在离职员工评分分布
从图中,可以得出:
- 离职员工的考核评分主要分为两部分, 一部分考核评分较低,另一部分考核评分较高。 这也说明评分低的员工更容易离开公司,评分较高的员工也容易离开公司。
- 评分成绩在0.6-0.8左右的员工不容易离开公司。
思考:
- 为什么一部分评分较高的员工选择了离职
-
是否离职与每月在公司工作小时之间的关系
df_loc2 = df.loc[(df['是否离职'] == 0), '每月在公司工作时间']
df_loc3 = df.loc[(df['是否离职'] == 1), '每月在公司工作时间']
ax = sns.kdeplot(df_loc2, shade = True, label = '在职')
ax = sns.kdeplot(df_loc3, shade = True, label = '离职')
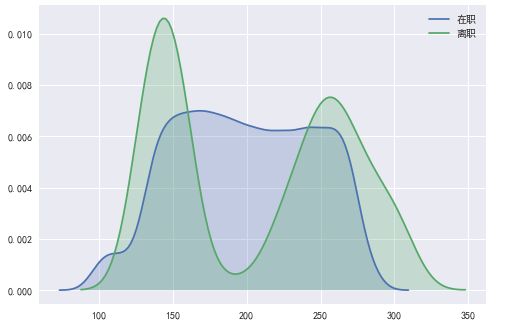 在离职员工工作时间分布
在离职员工工作时间分布
从图中可以得出:
- 工作时间较低的员工和工作时间较高的员工更容易离职。
- 工作时间在160-240小时之间的员工不容易离职。
思考:
- 为什么工作时间较低的员工更容易离职, 是因为工作不够努力吗, 工作环境是怎么样的。
- 为什么工作时间较长的员工更容易离职, 是因为工作时间过长, 压力过大吗?
-
最终评分与每月在公司工作时间 之间的关系
sns.lmplot(x='每月在公司工作时间', y='考核评分', data=df,hue='是否离职', fit_reg = False)
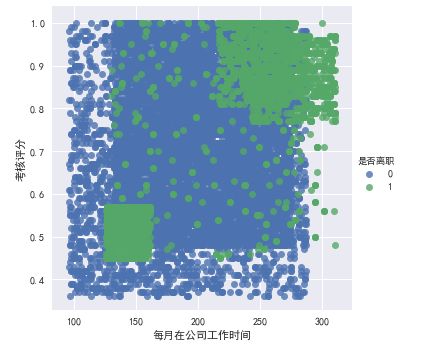 评分与员工每月工作时间 分布图
评分与员工每月工作时间 分布图
从图中可以得出:
- 最终评分与每月在公司工作时间之间没有必然的联系。
- 离职人员集中分布在 工作时间少且评分低的范围 和 工作时间长且评分高的范围
思考:
- 工作时间少且评分低的员工是否更倾向于离开公司。
-
是否离职与司龄之间的关系
ax = sns.countplot(x="司龄", hue="是否离职", data=df, palette="Set2")
 在离职员工司龄分布
在离职员工司龄分布
从图中可以得出:
- 从图中我们可以得知, 司龄在3-5年的员工更容易离职。
- 司龄在3年以下和6年以上的员工不容易离职。
思考:
- 为什么3-5年的员工更容易离职, 是因为职业机会变少,工作内容单一还是其他原因
- 为什么司龄在5年的离职率特别高
-
是否离职与部门之间的关系
查看不同部门人数分布, 已知不同部门分别用不同的数值来代替。
[sales', 'accounting', 'hr', 'technical', 'support', 'management','IT', 'product_mng', 'marketing', 'RandD'] 对应 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
# 公司部门人数分布
ax = sns.countplot (x='部门', data = df, paletter = 'Set2'
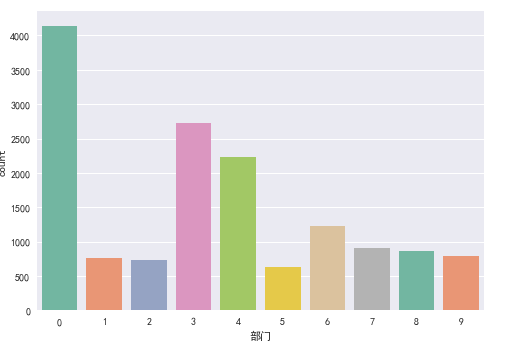 公司部门人数分布图
公司部门人数分布图
从图中可知:
- 数据中销售部门人数最多, 其次是技术部门和支持部门。
ax = sns.countplot(x="部门", hue="是否离职", data=df, palette="Set2")
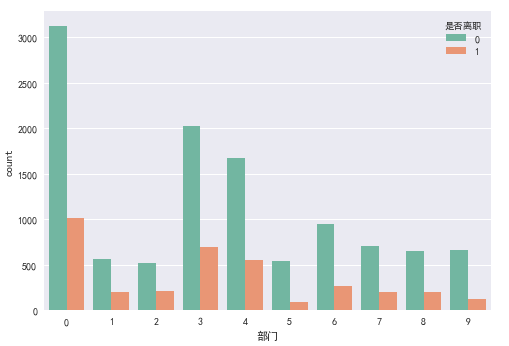 不同部门在离职员工分布
不同部门在离职员工分布
从图中可知:
- 销售部门, 技术部门和支持部门的人员流失率最高,管理部门人员流失率最低。
思考:
不同部门之间应如何分别制定策略降低人员流失
-
是否离职与薪水的关系
ax = sns.countplot(y = "薪水", hue = "是否离职", data = df, palette = "Set2")
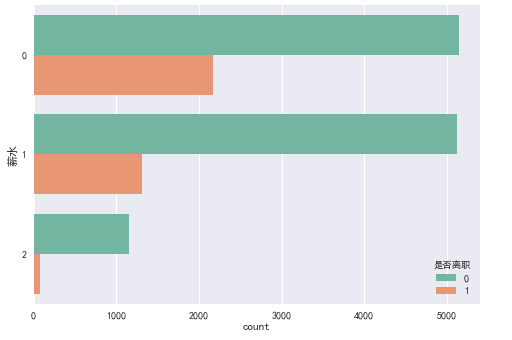 在离职员工不同薪水分布图
在离职员工不同薪水分布图
从图中可知:
- 薪水较高的员工离职的可能性相对较低
-
员工满意度与 最终评分之间的关系
sns.lmplot(x='员工满意度', y='考核评分', data=df,hue='是否离职', fit_reg = False)
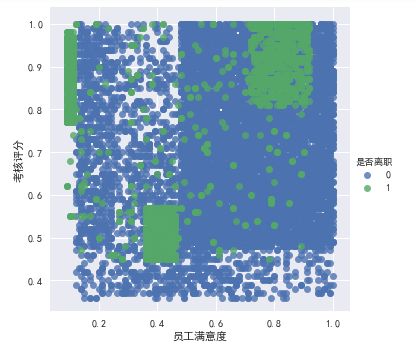 员工满意度与最终评分 分布图
员工满意度与最终评分 分布图
从图中可知:
离职员工分为三种:
- 第一种(努力工作但对公司不满意)
员工满意程度小于0.2,但最终评价大于0.75。 这可能说明 这些离开的员工非常勤奋努力, 但公司让他们沮丧,产生不满, 从而离开公司。
- 第二种(评价不高对公司满意度也低)
员工满意程度在0.35-0.5之间, 评价在0.58以下。 这可能表明 这些评价不高的员工在平时的工作中对公司的满意度也比较低
- 第三种 (评价高且对公司比较满意)
员工满意程度在0.7-0.9 之间, 且评价也在0.8-1.0 之间。这可能说明这个部分的员工是最理想的, 他们对自己工作的满意度比较高且得到的评价也高。
思考:
- 第一种员工:
什么原因使得努力工作的员工感到特别不满, 工作过于辛苦, 员工过于劳累
- 第二种员工:
这个群体是否代表未"表现不佳"的员工
- 第三种员工:
员工离职是否是因为其他的原因, 有了其他的工作机会?
参考:
Human Resources Analytics - Milestone Report
seaborn