第六章,数据可视化--学习笔记
注:小蚊子团队KEN主讲,共分6章。第一章,python与数据分析概况;第二章,python安装和使用;第三章,数据准备; 第四章 数据处理;第五章 数据分析;第六章,数据可视化
6.1散点图
1)、散点图(scatter diagram)是以一个变量为横坐标,另一个变量为纵坐标,利用散点(坐标点)的分布形态反映变量关系的一种图形。一般和相关分析、回归分析结合使用。
2)、散点图绘图函数:plot(x,y.'.',color=(r,g,b))
x,y,X轴和Y轴的序列
‘.'、'o',小点还是大点
color,散点图的颜色,也可以用英文字母定义
RGB颜色的设置:(red,green,blue)
RGB
Python的颜色范围只有0-1,颜色值要除以255
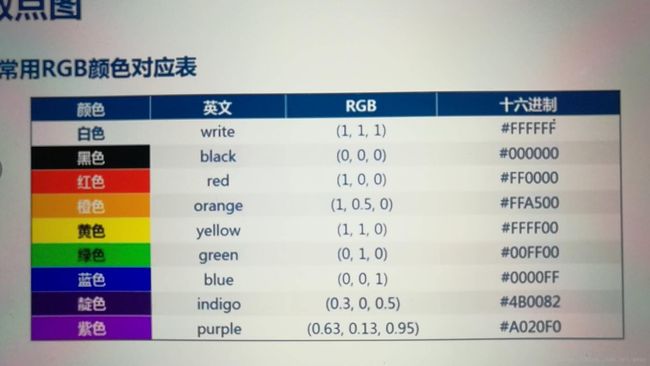
十六进制
3)、两个函数知识点:
plt.xlabel()
plt.tick_params()
4)、编程
1导入模块
2导入数据
3定义主题颜色
4设置字体样式
5绘图
x轴标签设置
y轴标签设置
x轴刻度线样式设置
y轴刻度线样式设置
画图
# -*- coding: utf-8 -*-
import pandas
import matplotlib
import matplotlib.pyplot as plt
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.1\\data.csv'
)
mainColor = (42/256, 87/256, 141/256, 1)
font = {
'size': 20,
'family': 'SimHei'
}
matplotlib.rc('font', **font)
#%matplotlib qt
#plt.grid(True)
#小点
plt.xlabel('广告费用', color=mainColor)
plt.ylabel('购买用户数', color=mainColor)
plt.tick_params(axis='x', colors=mainColor)
plt.tick_params(axis='y', colors=mainColor)
plt.plot(
data['广告费用'],
data['购买用户数'],
'.', color=mainColor
)
#大点
plt.xlabel('广告费用', color=mainColor)
plt.ylabel('购买用户数', color=mainColor)
plt.tick_params(axis='x', colors=mainColor)
plt.tick_params(axis='y', colors=mainColor)
plt.plot(
data['广告费用'],
data['购买用户数'],
"o", color=mainColor
)
1)、定义:也称趋势图,它是用直线段将个数据点连接起来而组成的图形,以折线方式限时数据的变化趋势
2)、折线图绘制函数:plot(x,y,style,color,linewidth)
title('图的标题')
style,划线的样式
color,划线的颜色
linewidth,线的宽度
1 - 连续的曲线
2 -- 连续的虚线
3 -. 连续的用带点的曲线
4 : 由点连成的曲线
5 . 小点,散点图
6 o 大点,散点图
7 , 像素点(更小的点)的散点图
8 * 五角星的点,散点图
3)、编程
1导入模块
2导入数据,必要时对数据格式进行转换
3设置主体颜色
4设置字体
5设置x轴、y轴标签
6设置x轴、y轴刻度样式
7设置图的标题
8画图
9显示图形
import pandas
import matplotlib
from matplotlib import pyplot as plt
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.2\\data.csv'
)
#对日期格式进行转换
data['购买日期'] = pandas.to_datetime(
data['日期']
)
mainColor = (42/256, 87/256, 141/256, 1);
font = {
'size': 20,
'family': 'SimHei'
}
matplotlib.rc('font', **font)
#%matplotlib qt
plt.xlabel(
'购买日期',
color=mainColor
)
plt.ylabel(
'购买用户数',
color=mainColor
)
plt.tick_params(
axis='x',
colors=mainColor
)
plt.tick_params(
axis='y',
colors=mainColor
)
#'-' 顺滑的曲线
plt.plot(
data['购买日期'],
data['购买用户数'],
'-', color=mainColor
)
plt.title('购买用户数')
plt.show()
#设置线条粗细
plt.plot(
data['购买日期'],
data['购买用户数'],
'-', color=mainColor,
lineWidth=10
)
#'--' 虚线
plt.plot(data['购买日期'], data['购买用户数'], '--');
#'-.' 线加点
plt.plot(data['购买日期'], data['购买用户数'], '-.');
#':' 由点组成的曲线
plt.plot(data['购买日期'], data['购买用户数'], ':');
#'.' 散点图
plt.plot(data['购买日期'], data['购买用户数'], '.');
#',' 像素点的散点图
plt.plot(data['购买日期'], data['购买用户数'], ',');
#'o' 大点的散点图
plt.plot(data['购买日期'], data['购买用户数'], 'o');
#'v' 下三角标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], 'v');
#'^' 上上角标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], '^');
#'<' 左角标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], '<');
#'>' 右角标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], '>');
#'1' 伞形下的标记散点图
#'2' 伞形上的标记散点图
#'3' 伞形左的标记散点图
#'4' 伞形右的标记散点图
plt.plot(data['购买日期'], data['购买用户数'], '4');
#'s' 正方形标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], 's');
#'p' 五角形标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], 'p');
#'*' 五角星标记的散点图
plt.plot(data['购买日期'], data['购买用户数'], '*');
#'h' 多边形标记的散点图
#'H' hexagon2 marker
plt.plot(data['购买日期'], data['购买用户数'], 'h');
#'+' plus marker
#'x' x marker
#'D' diamond marker
#'d' thin_diamond marker
plt.plot(data['购买日期'], data['购买用户数'], 'D');
#'|' vline marker
#'_' hline marker
plt.plot(data['购买日期'], data['购买用户数'], '|');
1)、定义:又称圆形图,是一个划分为几个扇形的圆形统计图,它能够直观地反映个体与总体的比例关系,它经常和结构分析一起使用
2)、饼图绘图函数:pie(x,labels.colors,explode,autopct)
x,进行绘图的序列
labels,饼图的各部分标签序列
colors,饼图的各部分颜色,使用RGB标颜色
explode,需要突出的块状序列,为0保持原状,非0则突出
autopct,饼图占比的显示格式,%.2f:保留两位小数
3)、知识准备
figure()函数:
plt.figure(figsize=(30, 30), dpi=80)
使用绝对路径获取字体的名称的方法:
fontProp = font_manager.FontProperties(
fname="C:\\Windows\\Fonts\\FZSTK.TTF"
)
matplotlib.rc('font', **font)
4)、编程
1导入模块
2读取数据
3数据分组统计
4设置长宽分辨率
5设置字体
6设置为横轴和纵轴等长的饼图
7设置突出的部分
8绘图
9显示图形
# -*- coding: utf-8 -*-
import numpy
import pandas
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as font_manager
#%matplotlib qt
#设置不在交互式命令行绘图,在弹出新的窗口进行绘图
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.3\\data.csv'
)
result = data.groupby(
by=['通信品牌'],
as_index=False
)['号码'].agg({
'用户数': numpy.size
})
#设置长宽分辨率
plt.figure(figsize=(30, 30), dpi=80)
#使用绝对路径获取字体的名称的方法
fontProp = font_manager.FontProperties(
fname="C:\\Windows\\Fonts\\FZSTK.TTF"
)
#设置字体
font = {
'family': fontProp.get_name(),
'size': 20
}
matplotlib.rc('font', **font)
#设置为横轴和纵轴等长的饼图
#也就是圆形的饼图,而非椭圆形的饼图
plt.axis('equal')
plt.pie(
result['用户数'],
labels=result['通信品牌'],
autopct='%.2f%%'
)
#设置突出的部分
explode = (0.1, 0.2, 0.3)
plt.axis('equal')
plt.pie(
result['用户数'],
labels=result['通信品牌'],
autopct='%.2f%%',
explode=explode,
startangle=67
)
plt.show()1)、定义:是一直以长方形的单位长度,根据数据大小写绘制的统计图,用来比较两个或者两个以上的数据(时间或者类别)
2)、柱形图绘图函数:竖向柱形图bar(left,height,width,color)
横向柱形图barh(bottom,width,height,lolor)
left,x轴的数值序列,一般采用arange函数产生一个序列
height,y轴的数值序列,即柱形图的高度,一般是指展示的数据
width,柱形图的宽度,一般设置为1
color,柱形图填充颜色
3)、种类
分组柱形图
位置偏移量
堆积柱形图(多维条形图)
bottom参数
双向柱形图
数值改为负值
4)、知识准备
图例函数legend()
5)、编程
1导入模块
2设置字体
3读取数据
4数据分组统计
5生成x轴数据
6绘图
单分组
1增加柱形图的颜色
2配置x轴可刻度
3对数据排序后再绘图
多分组
1数据分组
2设置每个分组柱形图的颜色
3使用排列的方式,把数据排列放好,即为多维条形图
4优化
堆积柱形图
数据分组
使用bottom参数堆叠数据
双向柱形图
7显示图像
# -*- coding: utf-8 -*-
import numpy
import pandas
import matplotlib
from matplotlib import pyplot as plt
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.4\\data.csv'
)
result = data.pivot_table(
values='月消费(元)',
index='手机品牌',
columns='通信品牌',
aggfunc=numpy.sum
)
index = numpy.arange(len(result))
minColor = (42/256, 87/256, 141/256, 1/3)
midColor = (42/256, 87/256, 141/256, 2/3)
maxColor = (42/256, 87/256, 141/256, 3/3)
result = result.sort_values(
by="神州行", ascending=False
)
#使用排列的方式,把数据堆叠放好,即为多维条形图
plt.bar(
index, result['神州行'],
color = maxColor
)
plt.bar(
index, result['动感地带'],
bottom=result['神州行'],
color = midColor
)
plt.bar(
index, result['全球通'],
bottom=result['神州行']+result['动感地带'],
color = minColor
)
plt.xticks(index, result.index)
plt.legend(['神州行', '动感地带', '全球通'])
plt.show()
优化
# -*- coding: utf-8 -*-
import numpy
import pandas
import matplotlib
from matplotlib import pyplot as plt
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.4\\data.csv'
)
result = data.groupby(
by=['手机品牌'],
as_index=False
)['月消费(元)'].agg({
'月消费': numpy.sum
})
#竖向柱形图
index = numpy.arange(
result.月消费.size
)
plt.bar(index, result['月消费'])
plt.show()
#优化点1、配置颜色
mainColor = (42/256, 87/256, 141/256, 1)
plt.bar(
index, result['月消费'],
color=mainColor
)
plt.show()
#优化点2、配置X轴刻度
plt.bar(
index, result['月消费'],
color=mainColor
)
plt.xticks(index, result.手机品牌)
plt.show()
#优化点3、对数据排序后再绘图
sgb = result.sort_values(
by="月消费",
ascending=False
)
plt.bar(
index, sgb.月消费,
color=mainColor
)
plt.xticks(index, sgb.手机品牌)
plt.show()
#横向柱形图
plt.barh(
index, sgb.月消费,
color=mainColor
)
plt.yticks(index, sgb.手机品牌)
plt.show()# -*- coding: utf-8 -*-
import numpy
import pandas
import matplotlib
from matplotlib import pyplot as plt
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.4\\data.csv'
)
result = data.pivot_table(
values='月消费(元)',
index='手机品牌',
columns='通信品牌',
aggfunc=numpy.sum
)
index = numpy.arange(len(result))
minColor = (42/256, 87/256, 141/256, 1/3)
midColor = (42/256, 87/256, 141/256, 2/3)
maxColor = (42/256, 87/256, 141/256, 3/3)
#使用排列的方式,把数据排列放好,即为多维条形图
plt.bar(
index, result['全球通'],
color=minColor, width=1/4
)
plt.bar(
index+1/4, result['动感地带'],
color=midColor, width=1/4
)
plt.bar(
index+2/4, result['神州行'],
color=maxColor, width=1/4
)
plt.xticks(index+1/3, result.index)
plt.legend(['全球通', '动感地带', '神州行'])
plt.show()
#优化一下,对数据进行一个排序
result = result.sort_values(
by="神州行", ascending=False
)
plt.bar(
index, result['神州行'],
color=maxColor, width=1/4
)
plt.bar(
index+1/4, result['动感地带'],
color=midColor, width=1/4
)
plt.bar(
index+2/4, result['全球通'],
color=minColor, width=1/4
)
plt.xticks(index+1/3, result.index)
plt.legend(['神州行', '动感地带', '全球通'])
plt.show()# -*- coding: utf-8 -*-
import numpy
import pandas
import matplotlib
from matplotlib import pyplot as plt
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
#解决负号是一个矩形的问题
matplotlib.rcParams['axes.unicode_minus']=False
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.4\\data.csv'
)
result = data.pivot_table(
values='月消费(元)',
index='手机品牌',
columns='通信品牌',
aggfunc=numpy.sum
);
index = numpy.arange(len(result));
minColor = (42/256, 87/256, 141/256, 1/3)
midColor = (42/256, 87/256, 141/256, 2/3)
maxColor = (42/256, 87/256, 141/256, 3/3)
result = result.sort_values(
by="神州行",
ascending=False
)
#使用排列的方式,把数据堆叠放好,即为多维条形图
plt.barh(
index,
result['动感地带'],
color = minColor
)
plt.barh(
index,
-result['神州行'],
color = maxColor
)
plt.yticks(index, result.index)
plt.legend(['动感地带', '神州行'])
plt.show()
6.5直方图
1)、定义:是用一系列等宽不等高的长方形来绘制,宽度表示数据范围的间隔,高度表示在给定间隔内数据出现的频数,变化的高度形态表示数据的发布情况2)、作用
显示各组频数分布的情况,给人整体的印象
对比各组频数数据的差异
3)、直方图绘图函数:hist(x,color,bins,cumulative=False)
x,需要进行绘制的向量
color,直方图的填充颜色
bins,设置直方图的分组个数
cumulative,设置是否累积计数,默认是False
4)、编程
1导入模块
2读入数据
3设置字体
4设置主题颜色
5绘图
# -*- coding: utf-8 -*-
import pandas
import matplotlib
from matplotlib import pyplot as plt
font = {
'family' : 'SimHei'
}
matplotlib.rc('font', **font)
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.5\\data.csv'
)
mainColor = (200/256, 87/256, 141/256, 1)
plt.hist(data['购买用户数'], color=mainColor)
plt.show()
plt.hist(data['购买用户数'], bins=20, color=mainColor)
plt.show()
plt.hist(
data['购买用户数'], bins=20,
cumulative=True, color=mainColor
)
plt.show()1)定义:是指按一定的比例运用符号、颜色、文字标记等庙会显示地球表面的自然地理、行政区域、社会经济状况的图形
2)、地图绘制的步骤
1绘制需要展示的地图,获取地图对象,获取每个区域的名字以及顺序
2在每个区域的名字和顺序后面,加上我们需要展示的数据以及经纬度(关键)
3根据数据的大小,设置每个区域展示的颜色的深浅,以区分每个区域(对数据进行标准化处理,使用[0,1]的值,代表颜色的透明度)
4根据颜色进行填色
5根据经纬度进行标注地图的名字
3)、函数:basemap(llcrnrlon,llcrnrlat,urcrnrlon,urcrnrlat)
llcrnrlon,所需的地图域(度)的左下角的经度
llcrnrlat,所需的地图域(度)的左下角的纬度
urcrnrlon,所需的地图域(度)的右上角的经度
urcrnrlat, 所需的地图域(度)的右上角的纬度。
4)、知识准备
basemap安装
readshapefile()
zip()
Polygon()
add_collection()
PatchCollection()
lambda
5)、编程
1安装的模块
2设置字体
3生成一个子图
4生成basemap对象
5加载地图数据
6设置主题颜色
7获取地图中的数据
8根据地区名称填充颜色
9读取地图对应的属性数据,如人口
注意人口数据有时候是字符型的,需要转换
数值每三位有个逗号需要去除
10设置主题颜色
11根据属性值给地图填色
12给每个地区标注名称
13显示地图
import numpy;
import matplotlib.pyplot as plt;
from matplotlib.patches import Polygon;
from mpl_toolkits.basemap import Basemap;
from matplotlib.collections import PatchCollection
#http://www.lfd.uci.edu/~gohlke/pythonlibs/#basemap
'''
参数意义
llcrnrlon
所需的地图域(度)的左下角的经度。
llcrnrlat
所需的地图域(度)的左下角的纬度。
urcrnrlon
所需的地图域(度)的右上角的经度。
urcrnrlat
所需的地图域(度)的右上角的纬度。
'''
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=73.55770111084013,
llcrnrlat=18.159305572509766,
urcrnrlon=134.7739257812502,
urcrnrlat=53.56085968017586
)
chinaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\6.6\\china\\CHN_adm1',
'china'
)
mainColor = (42/256, 87/256, 141/256, 1);
cInfo = basemap.china_info
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NAME_1']=='Liaoning':
patches.append(
Polygon(
numpy.array(shape),
True
)
)
ax.add_collection(
PatchCollection(
patches,
facecolor=mainColor,
edgecolor=mainColor,
linewidths=1.,
zorder=2
)
)
mainColor = (42/256, 87/256, 141/256, 1/2);
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NAME_1']=='Guangdong':
patches.append(Polygon(numpy.array(shape), True))
ax.add_collection(
PatchCollection(
patches,
facecolor=mainColor,
edgecolor=mainColor,
linewidths=1.,
zorder=2
)
)
plt.show()import numpy
import pandas
import matplotlib
#http://www.lfd.uci.edu/~gohlke/pythonlibs/#python-levenshtein
import Levenshtein
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=73.55770111084013,
llcrnrlat=18.159305572509766,
urcrnrlon=134.7739257812502,
urcrnrlat=53.56085968017586
)
chinaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\6.6\\china\\CHN_adm1',
'china'
)
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.6\\province.csv',
sep="\t"
)
data['总人口'] = data.总人口.str.replace(",", "").astype(int)
data['scala'] = (
data.总人口-data.总人口.min()
)/(
data.总人口.max()-data.总人口.min()
)
#数据处理:如何把JSON格式的数据,转换称为Data Frame的格式化数据
mapData = pandas.DataFrame(basemap.china_info)
#字段匹配第二大招:模糊匹配,从列表中,匹配出最大匹配度的项作为匹配项
def fuzzyMerge(df1, df2, left_on, right_on):
suitSource=[]
suitTarget=[]
suitRatio=[]
df2 = df2.groupby(
right_on
)[right_on].agg({
right_on: numpy.size
})
df2[right_on] = df2.index
for df1Index, df1Row in df1.iterrows():
for df2Index, df2Row in df2.iterrows():
if Levenshtein.ratio(df2Row[right_on], df1Row[left_on])!=0:
suitSource.append(df1Row[left_on])
suitTarget.append(df2Row[right_on])
suitRatio.append(Levenshtein.ratio(df2Row[right_on], df1Row[left_on]))
suitDataFrame = pandas.DataFrame({
right_on: suitTarget,
'suitRatio':suitRatio,
'suitSource':suitSource
})
suitDataFrame = suitDataFrame.drop_duplicates();
suitDataFrame = suitDataFrame.sort(
['suitSource', 'suitRatio'],
ascending=[1, 0]
)
rnColumn = suitDataFrame.groupby(
'suitSource'
).rank(
method='first',
numeric_only=True,
ascending=False
)
suitDataFrame['rn'] = rnColumn;
suitDataFrame = suitDataFrame[suitDataFrame.rn==1]
data = df1.merge(
suitDataFrame,
left_on=left_on,
right_on="suitSource"
)
del data['rn'];
del data['suitRatio'];
del data['suitSource'];
return data;
fData = fuzzyMerge(data, mapData, '地区', 'NL_NAME_1')
def plotProvince(row):
mainColor = (42/256, 87/256, 141/256, row['scala']);
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NL_NAME_1']==row['NL_NAME_1']:
patches.append(Polygon(numpy.array(shape), True))
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor, linewidths=1., zorder=2
)
)
fData.apply(lambda row: plotProvince(row), axis=1)
dataLoc = pandas.read_csv('D://dataloop//python_work//DataAnalysis\\6.6\\provinceLoc.csv');
def plotText(row):
plt.text(row.jd, row.wd, row.city, fontsize=14, fontweight='bold', ha='center',va='center',color='r')
dataLoc.apply(lambda row: plotText(row), axis=1)
plt.show()import numpy
import pandas
import matplotlib
import Levenshtein
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=73.55770111084013,
llcrnrlat=18.159305572509766,
urcrnrlon=134.7739257812502,
urcrnrlat=53.56085968017586
)
chinaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\6.6\\china\\CHN_adm2',
'china'
)
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.6\\city.csv',
sep="\t"
)
data['scala'] = (
data.population-data.population.min()
)/(
data.population.max()-data.population.min()
)
mapInfo = basemap.china_info
suitSource=[]
suitTarget=[]
suitRatio=[]
def matchMapInfo(row):
for info in basemap.china_info:
if Levenshtein.ratio(info['NL_NAME_2'], row['city'])!=0:
suitSource.append(row['city'])
suitTarget.append(info['NL_NAME_2'])
suitRatio.append(Levenshtein.ratio(info['NL_NAME_2'], row['city']))
data.apply(lambda row: matchMapInfo(row), axis=1)
suitDataFrame = pandas.DataFrame({
'suitSource':suitSource,
'suitTarget':suitTarget,
'suitRatio':suitRatio
})
suitDataFrame = suitDataFrame.drop_duplicates();
suitDataFrame = suitDataFrame.sort(
['suitSource', 'suitRatio'],
ascending=[1, 0]
)
rnColumn = suitDataFrame.groupby(
'suitSource'
).rank(
method='first',
numeric_only=True,
ascending=False
)
suitDataFrame['rn'] = rnColumn
suitDataFrame = suitDataFrame[suitDataFrame.rn==1]
data = data.merge(
suitDataFrame,
left_on="city",
right_on="suitSource"
)
def plotProvince(row):
mainColor = (42/256, 87/256, 141/256, row['scala']);
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NL_NAME_2']==row['suitTarget']:
patches.append(Polygon(numpy.array(shape), True))
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor, linewidths=1., zorder=2
)
)
data.apply(lambda row: plotProvince(row), axis=1)
dataLoc = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.6\\provinceLoc.csv'
)
def plotText(row):
plt.text(
row.jd, row.wd, row.city,
fontsize=14, fontweight='bold',
ha='center',va='center',color='r'
)
dataLoc.apply(lambda row: plotText(row), axis=1)
plt.show()import numpy
import pandas
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=-128,
llcrnrlat=22,
urcrnrlon=-64,
urcrnrlat=53
)
usaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\6.6\\USA\\USA_adm1',
'states', drawbounds=True
)
mainColor = (42/256, 87/256, 141/256, 1);
mapData = pandas.DataFrame(basemap.states_info)
patches = []
for info, shape in zip(
basemap.states_info, basemap.states
):
if info['NAME_1']=='Alabama':
patches.append(
Polygon(
numpy.array(shape), True
)
)
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor,
linewidths=1., zorder=2
)
)
mainColor = (42/256, 87/256, 141/256, 1/2);
patches = []
for info, shape in zip(
basemap.states_info, basemap.states
):
if info['NAME_1']=='Minnesota':
patches.append(
Polygon(
numpy.array(shape), True
)
)
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor,
linewidths=1., zorder=2
)
)
plt.show()import numpy
import pandas
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=-128,
llcrnrlat=22,
urcrnrlon=-64,
urcrnrlat=53
)
usaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\6.6\\USA\\USA_adm1',
'states', drawbounds=True
)
#人口数
data = pandas.read_csv(
"D://dataloop//python_work//DataAnalysis\\6.6\\data.csv"
)
mainColor = (42/256, 87/256, 141/256, 1);
data['2015 population'] = data[
'2015 population'
].str.replace(",", "").astype(int)
data['scala'] = (
data[
'2015 population'
]-data[
'2015 population'
].min()
)/(
data[
'2015 population'
].max()-data[
'2015 population'
].min()
)
def plotProvince(row):
mainColor = (
42/256, 87/256, 141/256,
row['scala']
)
patches = []
for info, shape in zip(
basemap.states_info, basemap.states
):
if info['NAME_1']==row['State']:
patches.append(
Polygon(
numpy.array(shape),
True
)
)
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor,
linewidths=1., zorder=2
)
)
data.apply(lambda row: plotProvince(row), axis=1)
dataLoc = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.6\\USALoc.csv'
)
def plotText(row):
plt.text(
row.Longitude, row.Latitude, row.State,
fontsize=14, fontweight='bold',
ha='center',va='center',color='r'
)
dataLoc.apply(lambda row: plotText(row), axis=1)
plt.show()1)、定义:是指以特殊高亮的形式,显示数据地理分布情况的图形
2)、编程
1导入模块
2设置字体
3生成一个子图
4生成basemap对象
5读入地形、人口、坐标等数据
6设置主体颜色
7地图填色
8地图标注
9热力图
10显示地图
import numpy
import pandas
import matplotlib
#http://www.lfd.uci.edu/~gohlke/pythonlibs/#python-levenshtein
import Levenshtein
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
%matplotlib qt
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=73.55770111084013,
llcrnrlat=18.159305572509766,
urcrnrlon=134.7739257812502,
urcrnrlat=53.56085968017586
)
chinaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\3.8\\china\\CHN_adm1',
'china'
)
data = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\3.8\\data.csv',
sep="\t"
)
data['总人口'] = data.总人口.str.replace(
",", ""
).astype(int)
data['scala'] = (
data.总人口-data.总人口.min()
)/(
data.总人口.max()-data.总人口.min()
)
#数据处理:如何把JSON格式的数据,转换称为Data Frame的格式化数据
mapData = pandas.DataFrame(basemap.china_info)
#字段匹配第二大招:模糊匹配,从列表中,匹配出最大匹配度的项作为匹配项
def fuzzyMerge(df1, df2, left_on, right_on):
suitSource=[]
suitTarget=[]
suitRatio=[]
df2 = df2.groupby(
right_on
)[right_on].agg({
right_on: numpy.size
})
df2[right_on] = df2.index
for df1Index, df1Row in df1.iterrows():
for df2Index, df2Row in df2.iterrows():
if Levenshtein.ratio(df2Row[right_on], df1Row[left_on])!=0:
suitSource.append(df1Row[left_on])
suitTarget.append(df2Row[right_on])
suitRatio.append(Levenshtein.ratio(df2Row[right_on], df1Row[left_on]))
suitDataFrame = pandas.DataFrame({
right_on: suitTarget,
'suitRatio':suitRatio,
'suitSource':suitSource
})
suitDataFrame = suitDataFrame.drop_duplicates();
suitDataFrame = suitDataFrame.sort(
['suitSource', 'suitRatio'],
ascending=[1, 0]
)
rnColumn = suitDataFrame.groupby(
'suitSource'
).rank(
method='first',
numeric_only=True,
ascending=False
)
suitDataFrame['rn'] = rnColumn;
suitDataFrame = suitDataFrame[suitDataFrame.rn==1]
data = df1.merge(
suitDataFrame,
left_on=left_on,
right_on="suitSource"
)
del data['rn'];
del data['suitRatio'];
del data['suitSource'];
return data;
fData = fuzzyMerge(data, mapData, '省份', 'NL_NAME_1')
def plotProvince(row):
mainColor = (42/256, 87/256, 141/256, row['scala']);
patches = []
for info, shape in zip(basemap.china_info, basemap.china):
if info['NL_NAME_1']==row['NL_NAME_1']:
patches.append(Polygon(numpy.array(shape), True))
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor, linewidths=1., zorder=2
)
)
fData.apply(lambda row: plotProvince(row), axis=1)
def plotText(row):
plt.text(
row.经度, row.纬度, row.城市,
fontsize=14, fontweight='bold',
ha='center',va='center',color='r'
)
data.apply(lambda row: plotText(row), axis=1)
data['文盲'] = data.文盲.str.replace(
",", ""
).fillna(0).astype(int)
data['sizeScala'] = (
data.文盲-data.文盲.min()
)/(
data.文盲.max()-data.文盲.min()
)
minCircleColor = (1, 0, 0, 0.2)
maxCircleColor = (1, 0, 0, 0.5)
def plotCicle(row):
circle = plt.Circle(
(row.经度, row.纬度),
row.sizeScala,
color=minCircleColor
)
ax.add_artist(circle)
circle = plt.Circle(
(row.经度, row.纬度),
row.sizeScala+0.2,
color=maxCircleColor
)
ax.add_artist(circle)
data.apply(lambda row: plotCicle(row), axis=1)
plt.show()import numpy
import pandas
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
from mpl_toolkits.basemap import Basemap
from matplotlib.collections import PatchCollection
font = {
'family' : 'SimHei'
};
matplotlib.rc('font', **font);
fig = plt.figure()
ax = fig.add_subplot(111)
basemap = Basemap(
llcrnrlon=-128,
llcrnrlat=22,
urcrnrlon=-64,
urcrnrlat=53
)
usaAdm1 = basemap.readshapefile(
'D://dataloop//python_work//DataAnalysis\\6.6\\USA\\USA_adm1',
'states', drawbounds=True
)
#人口数
data = pandas.read_csv(
"D://dataloop//python_work//DataAnalysis\\6.6\\data.csv"
)
dataLoc = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.6\\USALoc.csv'
)
data = data.merge(dataLoc)
mainColor = (42/256, 87/256, 141/256, 1)
data['2015 population'] = data[
'2015 population'
].str.replace(",", "").astype(int)
data['scala'] = (
data[
'2015 population'
] - data[
'2015 population'
].min()
)/(
data[
'2015 population'
].max() - data[
'2015 population'
].min()
)
def plotProvince(row):
mainColor = (
42/256, 87/256, 141/256,
row['scala']
);
patches = []
for info, shape in zip(
basemap.states_info, basemap.states
):
if info['NAME_1']==row['State']:
patches.append(
Polygon(
numpy.array(shape), True
)
)
ax.add_collection(
PatchCollection(
patches, facecolor=mainColor,
edgecolor=mainColor,
linewidths=1., zorder=2
)
)
data.apply(
lambda row: plotProvince(row),
axis=1
)
dataLoc = pandas.read_csv(
'D://dataloop//python_work//DataAnalysis\\6.6\\USALoc.csv'
);
def plotText(row):
plt.text(
row.Longitude, row.Latitude, row.State,
fontsize=14, fontweight='bold',
ha='center',va='center',color='r'
)
dataLoc.apply(lambda row: plotText(row), axis=1)
data['Density(Pop./mi?)'] = data[
'Density(Pop./mi?)'
].str.replace(",", "").astype(int)
data['sizeScala'] = (
data[
'Density(Pop./mi?)'
] - data[
'Density(Pop./mi?)'
].min()
)/(
data[
'Density(Pop./mi?)'
].max() - data[
'Density(Pop./mi?)'
].min()
)
minCircleColor = (1, 0, 0, 0.2)
maxCircleColor = (1, 0, 0, 0.5)
def plotCicle(row):
circle = plt.Circle(
(row.Longitude, row.Latitude),
row.sizeScala,
color=minCircleColor
)
ax.add_artist(circle)
circle = plt.Circle(
(row.Longitude, row.Latitude),
row.sizeScala+0.2,
color=maxCircleColor
)
ax.add_artist(circle)
data.apply(lambda row: plotCicle(row), axis=1)
plt.show()