Word2Vec的原理与实现
词向量表达
word2vec就是将单词嵌入到向量空间中。
独热表达: 每一个单词用不同的ID进行表示,因此可以表示为其中一个维度为1,其他全0的向量。例如:
科学院:[1,0,0] 中科院:[0,1,0] 数据挖掘:[0,0,1]

此种方法相当于将单词看成无语义的ID。在向量空间中考虑,此时单词之间相似性程度一样,不能体现出单词间的语义关系。
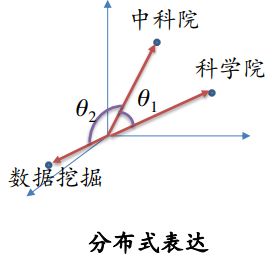
分布式表达
每一个单词表示为一般的向量,可以建模单词之间的语义关系。
例如:科学院:[1.0,0.5,0] 中科院:[0.5,1.0,0] 数据挖掘:[0,0.1,1.0]
word2vec
利用简单的浅层神经网络模型从海量的文档中学习词向量。
其两种变体分别为:连续词袋模型(CBOW)及Skip-Gram模型。从算法角度看,这两种方法非常相似,其区别为CBOW根据源词上下文词汇(‘the cat sits on the’)来预测目标词汇(例如,‘mat’),而Skip-Gram模型做法相反,它通过目标词汇来预测源词汇。Skip-Gram模型采取CBOW的逆过程的动机在于:CBOW算法对于很多分布式信息进行了平滑处理(例如将一整段上下文信息视为一个单一观察量)。很多情况下,对于小型的数据集,这一处理是有帮助的。相形之下,Skip-Gram模型将每个“上下文-目标词汇”的组合视为一个新观察量,这种做法在大型数据集中会更为有效。
例如具有如下的数据集:
the quick brown fox jumped over the lazy dog
目标单词的左右单词视作一个上下文, 使用大小为1的窗口,这样就得到这样一个由(上下文, 目标单词) 组成的数据集:
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox),...
Skip-Gram模型是把目标单词和上下文颠倒过来,所以在这个问题中,举个例子,就是用’quick’来预测 ‘the’ 和 ‘brown’ ,用 ‘brown’ 预测 ‘quick’ 和 ‘brown’ 。因此这个数据集就变成由(输入, 输出)组成的:
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
skip-gram
根据当前单词 w t w_{t} wt预测上下文单词 w t + j , − c ≤ j ≤ c , j ≠ 0 w_{t+j},-c\leq j\leq c ,j\neq 0 wt+j,−c≤j≤c,j̸=0
最大化似然,给定当前单词情况下,最大化相邻单词出现的概率。
L = ∑ t = 1 T ∑ − c ≤ j ≤ c , j ≠ 0 log p ( w t + j ∣ w t ) p ( w t + j ∣ w t ) = exp ( w t T w t + j ) ∑ v = 1 V exp ( w t T w v ) L=\sum_{t=1}^{T}\sum_{-c\leq j\leq c ,j\neq 0}\log p(w_{t+j}|w_{t})\\ p(w_{t+j}|w_{t})=\frac{\exp{(w_{t}^{T} w_{t+j})}}{\sum_{v=1}^{V}\exp{(w_{t}^{T} w_{v})}} L=t=1∑T−c≤j≤c,j̸=0∑logp(wt+j∣wt)p(wt+j∣wt)=∑v=1Vexp(wtTwv)exp(wtTwt+j)
在这里,概率值正比于单词向量的余弦相似性
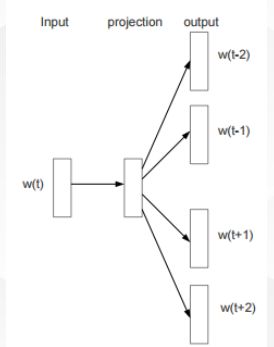
CBOW
根据上下文单词 w t + j , − c ≤ j ≤ c , j ≠ 0 w_{t+j},-c\leq j\leq c ,j\neq 0 wt+j,−c≤j≤c,j̸=0预测单词 w t w_{t} wt

最大化似然,给定相邻单词情况下,最大化当前单词的概率。
L = ∑ t = 1 T p ( w t ∣ w t ∗ ) w t ∗ = w t − c , . . . , w − 1 , w 1 , . . . , w t + c L=\sum_{t=1}^{T}p(w_{t}|w_{t*})\\ w_{t*}=w_{t-c},...,w_{-1},w_{1},...,w_{t+c} L=t=1∑Tp(wt∣wt∗)wt∗=wt−c,...,w−1,w1,...,wt+c
我们的优化目标就是寻找一个单词的分布,使得最大化似然。
以skip-gram为例实现word2vec
初始化:固定单词嵌入空间的维度,假设为128,为每一个单词生成该维度的随机表达。
网络结构分析:
网络为一个只有一个隐藏层的网络,隐藏神经元数量等于要建模的单词数量T=vocabulary_size=5000,转换矩阵维度为[5000,128]。
对于一个输入的样本单词 x x x,首先进行线性转换。之后,将得到的输出值进行softmax+cross_entropy进行计算得到其周围单词的概率:
p ( v i ∣ x ) = exp ( w i x + b ) ∑ t = 1 T exp ( w x t + b ) p(v_{i}|x)=\frac{\exp(w_{i}x+b)}{\sum_{t=1}^{T}\exp{(wx_{t}+b})} p(vi∣x)=∑t=1Texp(wxt+b)exp(wix+b)
但是,当建模的单词达到上万时,使用softmax会非常慢,改进的方法为使用 noise-contrastive estimation (NCE)。主要思路为:对于每一个样本,除了本身的label,同时负采样出N个其他的噪声单词,从而我们只需要计算样本在这N+1个单词上的概率,而不用计算样本在整个语料库上的概率。
样本在每个单词上的概率最终用了Logistic的sigmoid损失函数。
p ( v i ∣ x ) = 1 1 + exp ( − ( w i x + b ) p(v_{i}|x)=\frac{1}{1+\exp{(-(w_{i}x+b)}} p(vi∣x)=1+exp(−(wix+b)1
此时的目标就是优化单词嵌入向量和NCE转移矩阵,使得在样本目标单词上具有较大概率,其他噪声单词概率很低,也就是最大化训练集样本-目标单词出现的似然。
使用gensim库实现word2vec
from gensim.test.utils import common_texts,get_tmpfile
from gensim.models import Word2Vec
print(common_texts)
'''
[['human', 'interface', 'computer'],
['survey', 'user', 'computer', 'system', 'response', 'time'],
['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'],
['user', 'response', 'time'], ['trees'],
['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey']]
'''
model = Word2Vec(common_texts, size=2, window=5, min_count=1, workers=4)
print(model.wv['computer'])
# [0.19709973 0.03296339]
Word2Vec函数参数注解:
- sentences:要分析的语料,是一个列表
- size:词向量的维度,默认值是100。
- windows:词向量上下文最大距离,默认为5
- sg:如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
- hs:如果是0, 则是Negative Sampling,是1为Hierarchical Softmax
- negative:即使用Negative Sampling时负采样的个数,默认是5。
- min_count:需要计算词向量的最小词频,默认是5。小语料库可以调小。
- iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
- alpha: 在随机梯度下降法中迭代的步长,默认是0.025
- min_alpha: 算法在迭代的过程中逐渐减小到的最小步长
使用tensorflow实现Word2vec
需要导入的库:
import tensorflow as tf
import numpy as np
import collections
import math
import random
import zipfile
import urllib.request
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import os
下载数据集:
url = "http://mattmahoney.net/dc/"
# 下载数据
def maybe_download(filename, expected_btyes):
if os.path.exists(filename) is False:
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_btyes:
print("Find and verify:" + filename)
else:
print(statinfo.st_size)
raise Exception("Faise to verify:" + filename)
return filename
filename = maybe_download("text8.zip", 31344016)
语料集的预处理:
def read_data(filename):
with zipfile.ZipFile(filename, 'r') as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
# data为所有的单词编号,count为单词对应出现的次数的列表
# index_dict为单词对应的编号(编号就是出现次数排名)
def build_dataset(words, vocabulary_size):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
index_dict = {}
# 给单词的频数排名
k = 0
for word, _ in count:
index_dict[word] = k
k = k + 1
# data列表记录对应word列表单词的排名
data = []
unk_count = 0
for word in words:
if word in index_dict:
index = index_dict[word]
else:
index = 0
unk_count += 1
data.append(index)
count[0][1] = unk_count
# index_dict反转
reverse_index_dict = dict(zip(index_dict.values(), index_dict.keys()))
return data, count, index_dict, reverse_index_dict
# 生成样本数据,返回batch_size组batch[]对应label[]的数据
def generate_batch(batch_size, skip_window, num_skips):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
# 初始填充buffer数据
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
# 对每一个目标单词生成数据
for i in range(batch_size // num_skips):
target_to_avoid = [skip_window]
# 只是为了给target初值
target = skip_window
# 对确定的目标单词buffer[skip_window]生成样本数据
for j in range(num_skips):
while target in target_to_avoid:
target = random.randint(0, span - 1)
batch[i * num_skips + j] = buffer[target]
labels[i * num_skips + j] = buffer[skip_window]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
tensorflow计算图搭建:
vocabulary_size = 50000
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.device('/cpu:0'):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1,
keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = \
tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(
valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.global_variables_initializer()
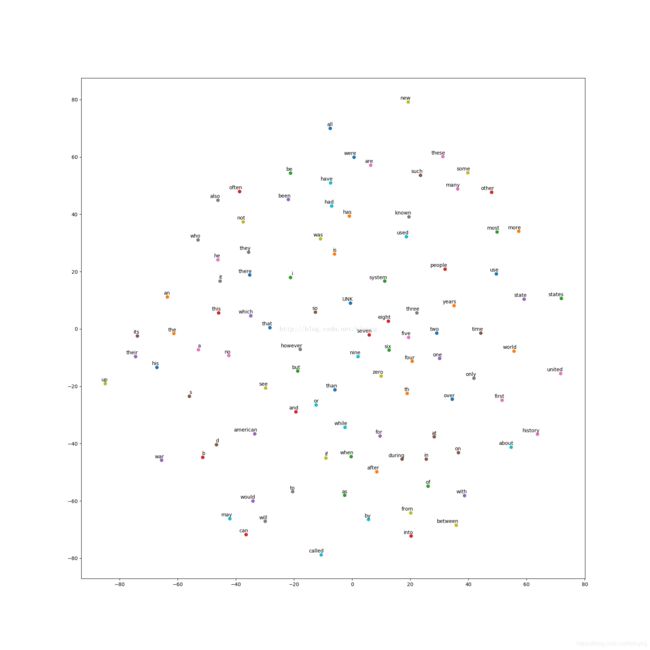
在二维空间中的可视化:
def plot_with_labels(low_dim_embs, labels, filename='tsne,png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than enbeddings"
plt.figure(figsize=(18, 18))
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
# (x,y)点注释,以描点为参考,向左偏移5,向上偏移2,
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.savefig(filename)
训练和可视化:
if __name__ == '__main__':
words = read_data('text8.zip')
# print('Data size:', len(words))
# 保留top50000的单词
data, count, index_dict, reverse_index_dict = build_dataset(words, 50000)
# 删除单词列表,节省空间
del words
data_index = 0
with tf.Session(graph=graph) as sess:
sess.run(init)
average_loss = 0.0
for step in range(100001):
batch_inputs, batch_labels = \
generate_batch(batch_size, skip_window, num_skips)
_, loss_val = sess.run([optimizer, loss],
feed_dict={train_inputs: batch_inputs,
train_labels: batch_labels})
average_loss += loss_val
if step % 2000 == 0:
print("Average loss at step:",
step, ":", average_loss / 2000)
average_loss = 0.0
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_index_dict[valid_examples[i]]
# 展示最近的8个单词,标号为0的为单词本身
nearest = (-sim[i, :]).argsort()[1: 9]
print(sim[i, :])
log_str = "Nearest to " + valid_word + " :"
for k in range(8):
close_word = reverse_index_dict[nearest[k]]
log_str = log_str + close_word + ','
print(log_str)
final_embeddings = normalized_embeddings.eval()
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 100
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_index_dict[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs, labels)