Android Gradle学习系列(四)-Gradle高级用法实战
前言
我们上几篇主要讲解了Groovy的基础语法,这一篇我们主要讲解Groovy的高级语法
json操作,xml操作,文件操作
1.Json操作详解
Json相关的操作基本上就两种,一种是把Json字符串转换成实体对象.一种是把我们的实体对象转换成对应的Json字符串.那么在我们Groovy中都有对应的类和方法帮助我们
groovy.json.JsonSlurper:将
json数据转成实体对象 groovy.json.JsonOutput:将实体对象转成json数据
1.1使用自带方法
我们分别写个例子看下效果
第一种:实体对象转换成Json

同时Groovy中还自带直接帮我格式化的方法
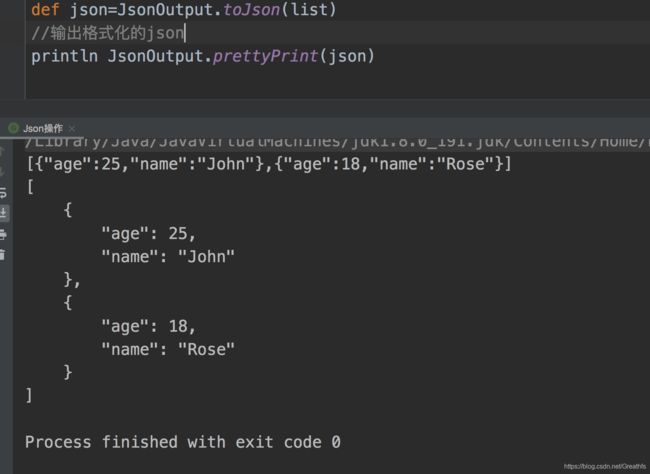
第二种:将json转成实体对象

这个parseText入参是个String,一般我们使用的话可以直接使用parse,这个方法的入参基本上支持任意类型,不单纯是String

1.2 使用第三方库
我们知道Groovy是完全兼容Java的,所以Java能使用的第三方json库(如:gson、fastjson啥的在Groovy中也同样可以导入使用,但是Groovy中自带的其实已经够我们用的了
下面说下怎么导入gson
首先下载gson的jar包,放在我们的libs目录下(下载地址)
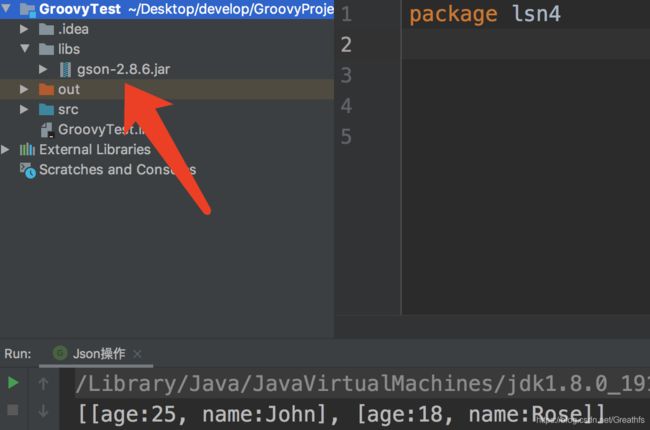
然后在脚本文件中直接导入相应的类使用对应方法即可
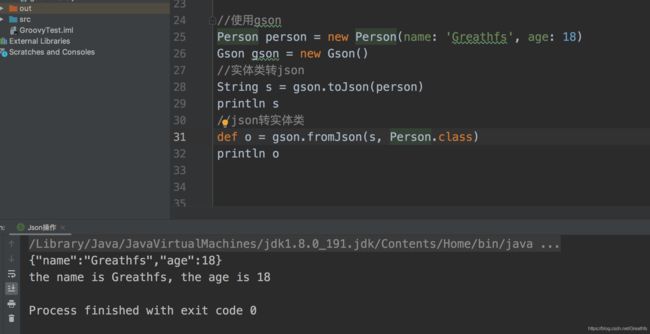
1.3模拟网络请求解析
我们实际基本上都是从服务端请求数据,客户端转化成我们的实体对象,然后将我们的实体对象展现在我们的UI上或者存储本地

这里和我们的Java有点区别,Java中你需要定义一个具体的实体类来解析,解析完之后拿到对应的数据,但是Groovy中是不需要定义具体的实体类的,我们可以直接拿到我们想要的数据
2.xml操作详解

上面的思维导图是Java中处理xml格式数据的两种方式,而我们Groovy中直接提供了相应的xml处理工具
groovy.xml.XmlSlurper:将xml原数据转成实体对象 groovy.xml.MarkupBuilder:将实体对象转成xml数据
下面我们就分别使用下
2.1 Groovy解析xml
我们首先定义一个xml
final String xml = '''
<response version-api="2.0">
<value>
<books id="1" classification="android">
<book available="20" id="1">
<title>疯狂Android讲义title>
<author id="1">李刚author>
book>
<book available="14" id="2">
<title>第一行代码title>
<author id="2">郭林author>
book>
<book available="13" id="3">
<title>Android开发艺术探索title>
<author id="3">任玉刚author>
book>
<book available="5" id="4">
<title>Android源码设计模式title>
<author id="4">何红辉author>
book>
books>
<books id="2" classification="web">
<book available="10" id="1">
<title>Vue从入门到精通title>
<author id="4">李刚author>
book>
books>
value>
response>
'''
之前在Json操作有个JsonSlurper,那么对应的xml就偶遇个XmlSlurper,它同样有个parse方法,使用起来基本和上面你的JsonSlurper一样
比如我们想输出第一本书的名字:疯狂Android讲义,我们应该怎么做呢?
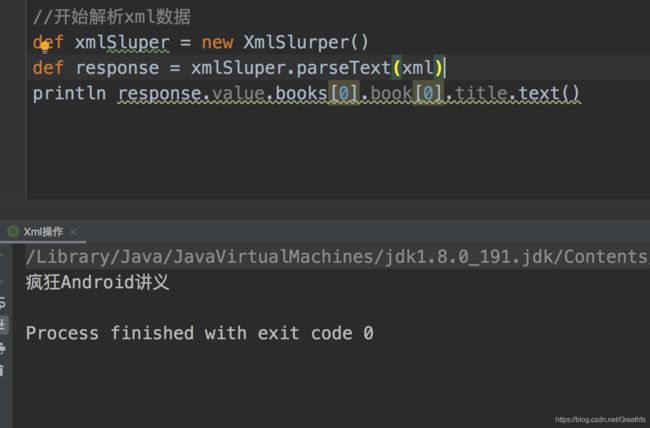
我们发现很简单,比我们Java方便多了,那我们要是想输出标签属性呢?比如获取比一本书的available属性

2.2遍历xml
如果我们想获取这个xml中所有作者是李刚的书的集合应该怎么做呢?
这里我们的逻辑应该就是一层一层的找,找到第一层books的集合response.value.books,然后遍历这个books,找到每一本book,取它的author,看看是不是叫李刚
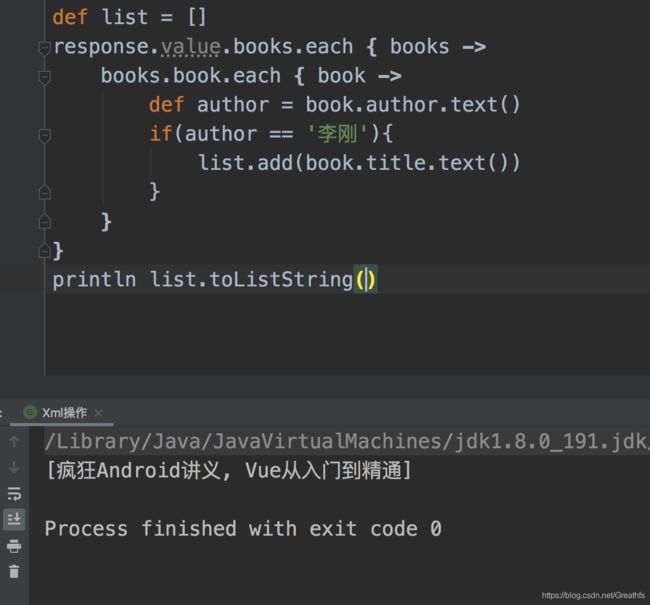
我们看见输出的结果就是我们正确的结果,但是Groovy其实提供了更加简单的遍历方法
深度遍历depthFirst,我们用这种方式实现下上面的效果

结果是以一样的,但是下面这种方式使用起来更为简单
有深度遍历自然就有广度遍历children(),比如我们想获取标签属性id是2的那本书的名字

2.3 生成xml
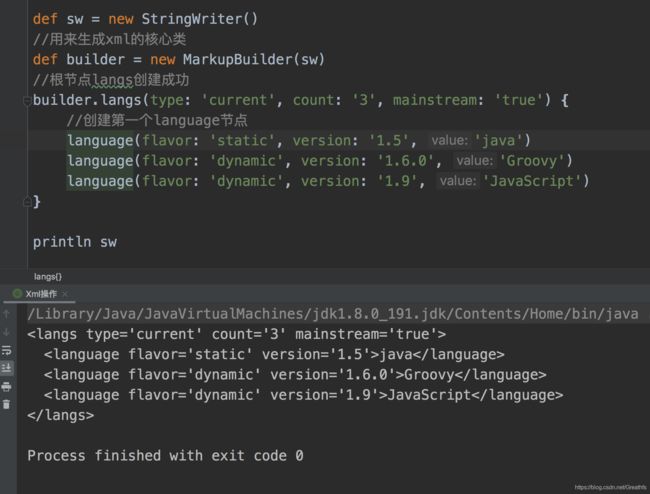
Groovy中还可以生成你想要的xml,比如我们想想生成下面的那个xml我们应该怎么做呢?
/**
* 生成xml格式数据
* <langs type='current' count='3' mainstream='true'>
* <language flavor='static' version='1.5'>javalanguage>
* <language flavor='dynamic' version='1.6.0'>Groovylanguage>
* <language flavor='dynamic' version='1.9'>JavaScriptlanguage>
* langs>
*/
首先我们先分析下我们想要生成的这个xml,它有两个节点,一个是langs,属性分别是:type,count.mainstream,langs节点下面还有另外一个节点language,属性是:flavor,version,然后就是对应的value
分析清除之后我们就开始着手写了,这里会用到一个MarkupBuilder类,这个类是生成xml数据的核心类
如果language下面还有节点怎么弄?和我们指定language节点一样
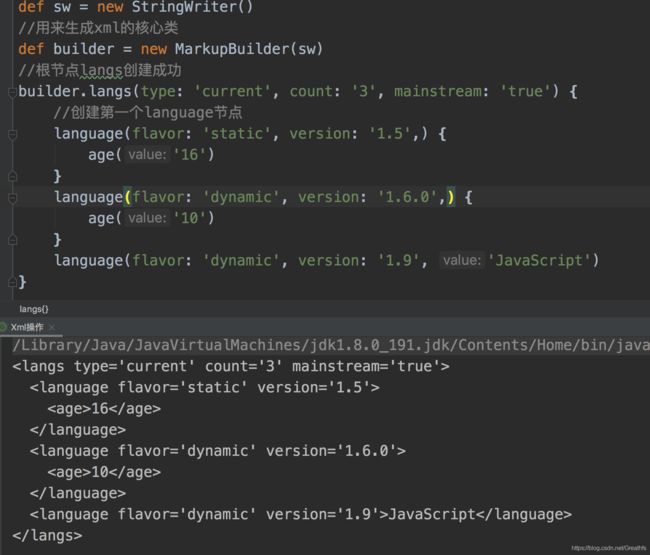
但我们一般在实际开发中,往往都是将实体对象转成xml,写法跟上面差不多
我们先建一个Language类
//对应xml中的language节点
class Language {
String flavor
String version
String value
}
然后在建一个Langs类
//对应xml中的langs节点
class Langs {
String type = 'current'
int count = 3
boolean mainstream = true
def languages = [
new Language(flavor: 'static', version: '1.5', value: 'java'),
new Language(flavor: 'dynamic', version: '1.6.0', value: 'Groovy'),
new Language(flavor: 'dynamic', version: '1.9', value: 'JavaScript')
]
}
然后我们仿照我们上面的写法生成一个xml,

我们也可以和我们的Json结合在一起,Json字符串通过JsonSlurper生成实体类,然后在通过MarkupBuilder生成对应的xml
3.文件操作详解
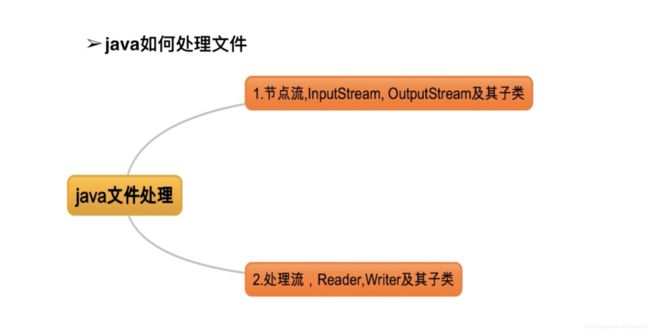
上面的思维导入是我们Java中对文件的处理,在Groovy中这些方法你都能使用,同时Groovy还扩展了许多更加快捷和强大的方法(ResourceGroovyMethods)
接下来我们就通过几个例子来具体实践下

我们接下里来的例子都是以这个文件为例,它是项目创建的时候自动生成的
创建File对象和我们的Java一模一样

3.1遍历文件
我们首先输出下这个文件里面的内容,这里就需要用到eachLine这个方法

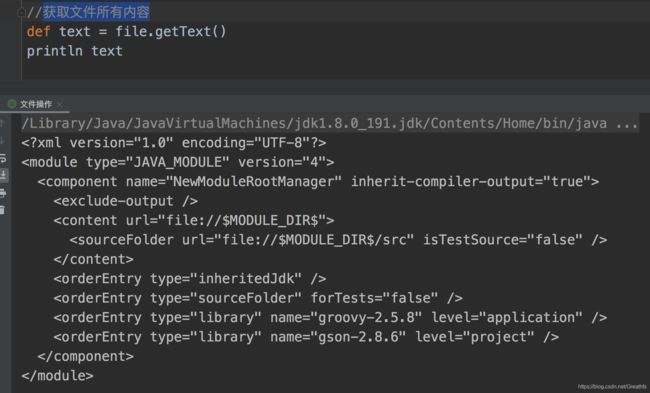
3.2 获取文件所有内容
这个和我们上面的输出内容一样
3.3获取每一行文本组成的list

这个方法返回的是将我们这个文件里面的每一行当成一个元素组成的一个列表
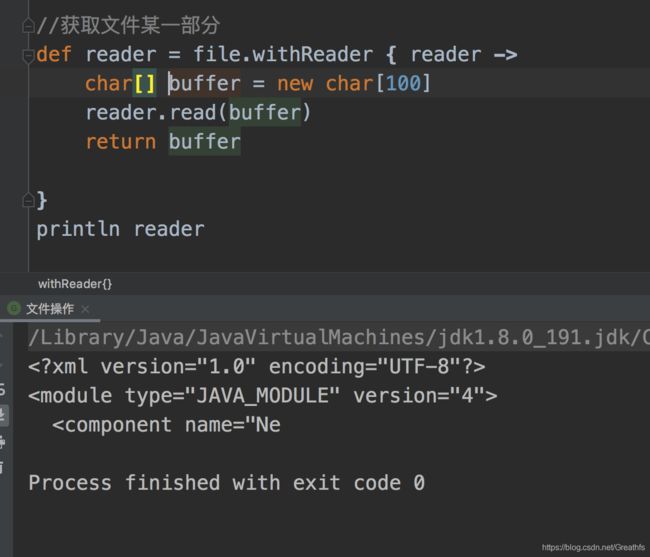
3.4 读取文件某一部分
我们获取文件前100个字符
3.5 复制文件
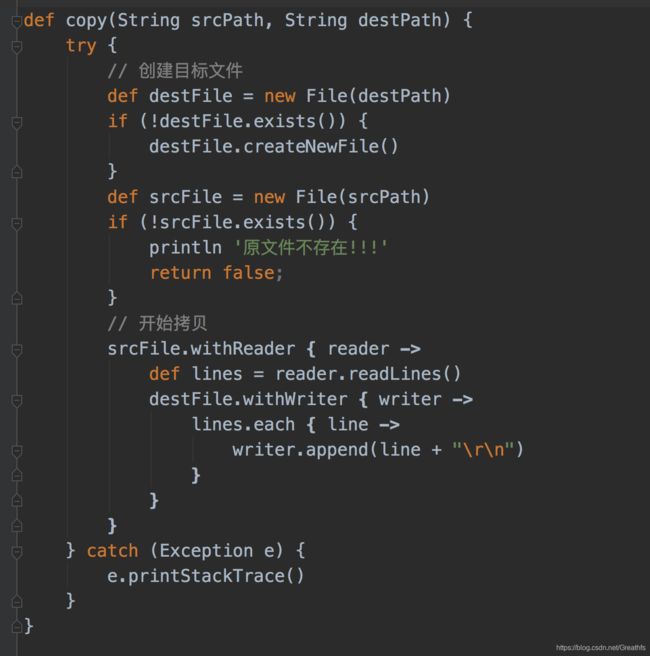
我们这里是一行一行复制过去的,同样我们也可以一次性全部复制过去,我们调用下这个方法
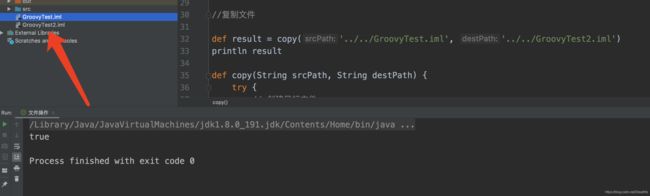
我们看见成功复制过去一个文件,我们打开下这个文件
和源文件内容是一模一样的
这里还有个地方注意下,我们在Java中对文件进行读写操作需要手动关闭流,但是在Groovy中我们可以省略这步骤,因为内部已经帮我们做了
我们先看下withWriter方法

继续往下走
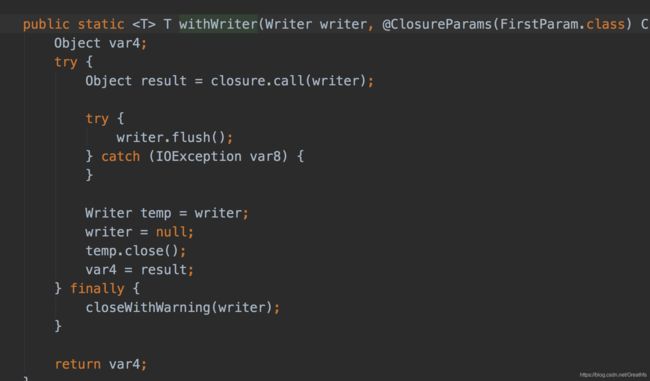
我们看下finally里面的方法

3.6将对象保存到文件
这里用到一个新的方法withObjectOutputStream,我们操作文本用reader和writer,我们操作对象用stream

我们写个例子验证下

这里要注意:这个对象要实现序列化接口,否则会报错

3.7从文件中取出对象

我们就取我们刚才存的那个person
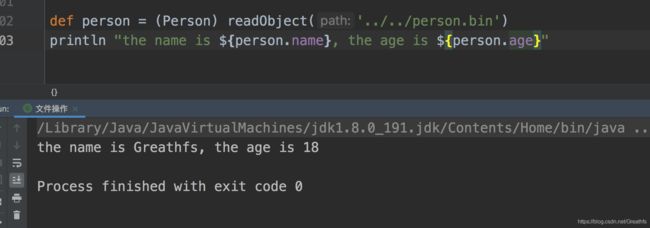
可以看见和我们存进去的是一样的
OK,到这里我们这一样就写完了,下一篇开始我们就开始学习Gradle了,下一篇见