拓扑排序和关键路径算法----关键路径算法 (C语言实现)
在学习了拓扑排序之后,我们可以开始学习关键路径了。拓扑排序可以有多个起点和多个终点,跟拓扑排序不同的是,关键路径只能有一个起点、一个终点。
我们使用带有权重的有向图表示,8 -> 0 -> 1 -> 4 -> 5 -> 7这条红色的路径就是关键路径。关键路径的特征是:从起点 (起点是唯一的,入度为0) 到终点 (终点是唯一的,出度为0) 的一个有向图中,该路径上的弧 (有向图的边称之为“弧”) 的权重的和最大。关键路径可能不是唯一的,但不同的关键路径上的权重之和是相同的。
如果把从起点到终点的所有事件看作一个工程,减小非关键路径上的弧的权重不会降低整个工程的时间。减少关键路径上的弧的权重,可以减少整个工程的时间。如果这个工程中有多条关键路径,那么必须同时压缩所有的关键路径,才能减少整个工程的时间。压缩关键路径可能导致的一个问题:关键路径变成非关键路径,而原先的非关键路径变成新的关键路径。
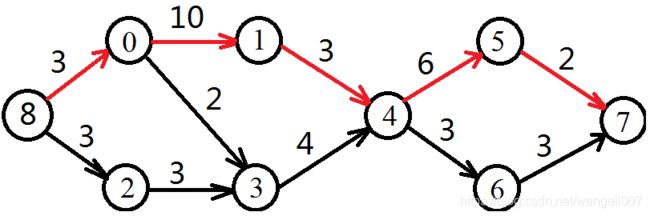 我们发现,这一条关键路径一定是一个拓扑排序的子序列。所以我们就可以用拓扑排序计算关键路径了。但问题是拓扑排序有多种结果,怎么才能拿到关键路径 (权重的和最大) 呢?
我们发现,这一条关键路径一定是一个拓扑排序的子序列。所以我们就可以用拓扑排序计算关键路径了。但问题是拓扑排序有多种结果,怎么才能拿到关键路径 (权重的和最大) 呢?
首先,我们需要计算每个节点的earlyTime (最早开始时间)。终点的earlyTime 就是从起点到终点的最大权重和。
其次,如果我们从终点到起点,进行反向的计算lastTime (最晚开始时间),如果某一条路径的每一个结点的earlyTime 与lastTime都相等,那么这条路径就是关键路径。
怎么计算每个节点的earlyTime呢?我们可以用递推。
例如:从起点开始,有两条路径可以到达3号点。分别是:8 -> 0 -> 3和8 -> 2 -> 3。我们只需要取这两条路径的权重最大值,那就是8 -> 3的权重。递推关系式:
earlyTime(0) = max[earlyTime(0), earlyTime(8) + weight8_0]
earlyTime(2) = max[earlyTime(2), earlyTime(8) + weight8_2]
earlyTime(3) 需要计算两次:
earlyTime(3) = max[earlyTime(3), earlyTime(0) + weight0_3]
earlyTime(3) = max[earlyTime(3), earlyTime(2) + weight2_3]
用同样的方法就可以计算出终点7的earlyTime,也就是从起点到终点的最大权重和。
在得到从起点到终点的最大权重和之后,我们就可以反向计算了。显然,终点的lastTime 和earlyTime是同一个值。那么其它结点的lastTime的初始值是多少呢?可以简单的赋值为∞ (无穷大,inf),或者也同样设置为终点的lastTime。
计算结点的lastTime与计算earlyTime类似,也可以用递推。例如一共有两条路径从终点出发,反向走到结点4,分别是7 -> 5 -> 4和7 -> 6 -> 4。递推关系式:
lastTime(5) = min[lastTime(5), lastTime(7) - weight5_7]
lastTime(6) = min[lastTime(6), lastTime(7) - weight6_7]
lastTime(4) 需要计算两次:
lastTime(4) = min[lastTime(4), lastTime(5) - weight4_5]
lastTime(4) = min[lastTime(4), lastTime(6) - weight4_6]
用同样的方法就可以计算出所有结点的lastTime。接着对比一下每个结点的earlyTime和lastTime。如果这两个值相等,则这个结点一定是关键路径上的结点,输出这个结点的编号即可。
总体的代码如下:
#include 运行结果如下:
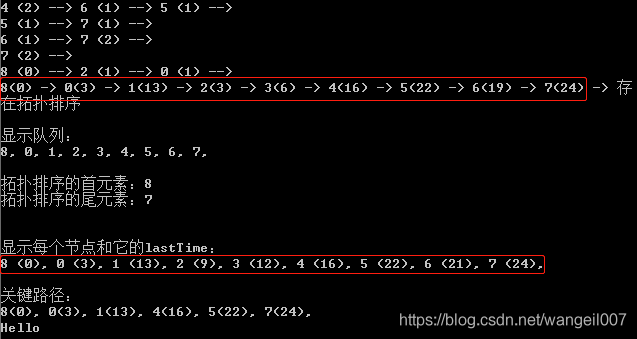 很明显,关键路径上的结点的earlyTime与lastTime都相等。如果一个有向图中有多条关键路径,这个代码不会分别显示。只会把所有结点按照拓扑排序中的次序依次显示。
很明显,关键路径上的结点的earlyTime与lastTime都相等。如果一个有向图中有多条关键路径,这个代码不会分别显示。只会把所有结点按照拓扑排序中的次序依次显示。
这个算法的思路不难,但是过程却比较复杂,代码也相对比较长。代码中大部分是拓扑排序的内容,真正计算关键路径的代码其实不多。另外,这里使用邻接矩阵的方式储存图的边长 (weight),需要两层for循环才能最终确定每一个结点的lastTime,所以关键路径算法的时间复杂度为O(N^2)。
关键路径算法是“图”的最后一个扩展算法。它是运筹学的一部分。根据关键路径,可以明确加快哪些步骤可以加速整个工程的进度。