BatchNorm
深度网络参数训练时内部存在协方差偏移(Internal Covariate Shift)现象:深度网络内部数据分布在训练过程中发生变化的现象。
为什么会带来不好影响:训练深度网络时,神经网络隐层参数更新会导致网络输出层输出数据的分布发生变化,而且随着层数的增加,根据链式规则,这种偏移现象会逐渐被放大。这对于网络参数学习来说是个问题:因为神经网络本质学习的就是数据分布(representation learning),如果数据分布变化了,神经网络又不得不学习新的分布。为保证网络参数训练的稳定性和收敛性,往往需要选择比较小的学习速率(learning rate),同时参数初始化的好坏也明显影响训练出的模型精度,特别是在训练具有饱和非线性(死区特性)的网络,比如即采用S或双S激活函数网络,比如LSTM,GRU。(https://zhuanlan.zhihu.com/p/26702482)
BN的主要思想就是对每层输入数据做标准化,使其符合高斯分布,也就是减均值除以标准差。此方法可以加速收敛,因为此方法处理后的参数符合高斯分布,大部分数值落在中间附近,使用sigmoid函数比较容易收敛。具体方法如下图:

要注意,标准化的过程本身是和同一个batch中的相同维度做的。比如对于一个128维的向量,第一维和其他batch里面的第一维做标准化。
最后的γ和β是训练出来的参数,本身目的在于尽可能保留原先数据的分布。举个例子,原先学习到的数据分布就在两侧,bn以后直接归一化到中间。γ和β就是为了再拟合原先的分布。(此处可能理解失误,也可能两个参数的目的是为了保证非线性)
在训练时,每次BN的均值和方差都来自于整个batch。在测试时只有一个图片或者样本,所以可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,因为本来就打算用全局的统计量,只是因为计算量等太大所以才会用Mini-Batch这种简化方式的,那么在推理的时候直接用全局统计量即可。
决定了获得统计量的数据范围,那么接下来的问题是如何获得均值和方差的问题。很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:
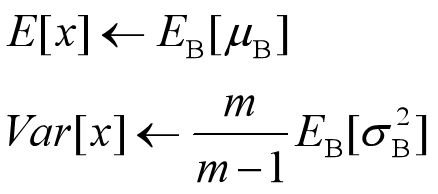
有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算NB进行变换了,在推理过程中进行BN采取如下方式:

这个公式其实和训练时

是等价的,通过简单的合并计算推导就可以得出这个结论。那么为啥要写成这个变换形式呢?我猜作者这么写的意思是:在实际运行的时候,按照这种变体形式可以减少计算量,为啥呢?因为对于每个隐层节点来说:


都是固定值,这样这两个值可以事先算好存起来,在推理的时候直接用就行了,这样比原始的公式每一步骤都现算少了除法的运算过程,乍一看也没少多少计算量,但是如果隐层节点个数多的话节省的计算量就比较多了。
(https://www.cnblogs.com/guoyaohua/p/8724433.html)
caffe中的BN层共存储了3个数值:均值滑动和、方差滑动和、滑动系数和。为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后(https://blog.csdn.net/qq_29573053/article/details/79878437 )
原文中是这样解释的,因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。其实想想也是的,像relu这样的激活函数,如果你输入的数据是一个高斯分布,经过他变换出来的数据能是一个什么形状?小于0的被抑制了,也就是分布小于0的部分直接变成0了,这样不是很高斯了。
反向传播见
https://zhuanlan.zhihu.com/p/26138673
moving average的更新方式:
在训练的过程中,通过每个step得到的mean和variance,叠加计算对应的moving_average(滑动平均),并最终保存下来以便在inference的过程中使用。
其实内部计算比较简单,公式表达如下:
variable = variable * decay + value * (1 - decay)
变换一下:
variable = variable - (1 - decay) * (variable - value)
减号后面的项就是moving_average的更新delta了。
原理:
https://www.jianshu.com/p/ae801c097216
https://www.cnblogs.com/guoyaohua/p/8724433.html
BatchNorm的好处
BatchNorm为什么NB呢,关键还是效果好。①不仅仅极大提升了训练速度,收敛过程大大加快;②还能增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;③另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
“Internal Covariate Shift”问题
从论文名字可以看出,BN是用来解决“Internal Covariate Shift”问题的,那么首先得理解什么是“Internal Covariate Shift”?
论文首先说明Mini-Batch SGD相对于One Example SGD的两个优势:梯度更新方向更准确;并行计算速度快;(为什么要说这些?因为BatchNorm是基于Mini-Batch SGD的,所以先夸下Mini-Batch SGD,当然也是大实话);然后吐槽下SGD训练的缺点:超参数调起来很麻烦。(作者隐含意思是用BN就能解决很多SGD的缺点)
接着引入covariate shift的概念:如果ML系统实例集合
然后提出了BatchNorm的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了。
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。