分布式优化和去中心化优化概述
分布式优化和去中心化优化概述
陆嵩
中科院 数学与系统科学研究院 科学与工程计算国家重点实验室
文章目录
- 分布式优化和去中心化优化概述
- 简介
- 预备知识
- 优化基础理论
- 梯度下降方法(GD)
- Gradient Descent
- 步长选取
- 收敛率
- 约束优化问题的拉格朗日乘数法
- 次梯度算法
- 图谱理论基础
- 平均一致性问题
- 模型问题
- 梯度算法
- 收敛性结果
- 对于去中心化的梯度下降方法
- 凸问题的 DGD 算法
- 一些结论和讨论
- 凸问题的较新方法
- ADMM(原始-对偶)
- 对偶上升
- 对偶分解
- 增广拉格朗日方法
- ADMM 及其收敛性
- 分布式 ADMM 算法
- EXTRA和其他方法
- 非凸问题方法
- DGD(常步长和递减步长)
- 原始-对偶方法
- 随机问题的方法
- 随机梯度下降方法(SGD)
- 去中心化随机梯度下降方法(DSGD or SDGD)
- 分布式优化总结和展望
- 问题设定
- 凸问题方法
- 非凸问题方法
- 复杂度下界
- 最优收敛率算法
- 最近发展和开放性问题
- 联邦学习
- 联邦学习简介
- 联邦学习算法
- FedAvg 算法收敛性分析
简介
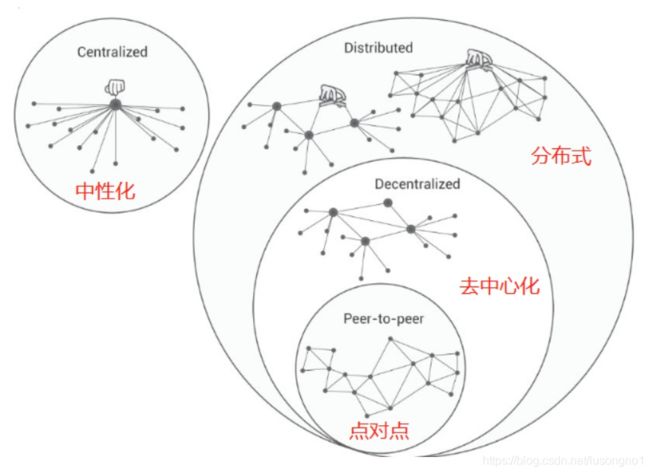
分布式系统的定义:组件分布在联网的计算机上,组件之间通过传递消息通信和动作协调的系统。通俗而言,分布式系统就是多台独立的计算机协同工作以完成任务。
分布式思想,使我们今天在人工智能、大数据、云计算、物联网、区块链等技术上得到了高速发展,尤其是对于物联网来说,分布式的理念显得极为重要。
下面一张图,很好地诠释了中心化和分布式的一个关系。
预备知识
优化基础理论
首先,我们需要用到一些优化的知识,可以参考我之前写的两篇文章。剩下的知识,下面会补充。
优化理论1
优化理论2
梯度下降方法(GD)
Gradient Descent
一般的梯度下降方法,我们写为:
x r + 1 = x r − α r D r ∇ f ( x r ) , r = 0 , 1 , ⋯ \mathbf{x}^{r+1}=\mathbf{x}^{r}-\alpha_{r} \mathbf{D}^{r} \nabla f\left(\mathbf{x}^{r}\right), r=0,1, \cdots xr+1=xr−αrDr∇f(xr),r=0,1,⋯
这里的 D r \mathbf{D}^{r} Dr 是一个 scaling 矩阵。它取为单位矩阵,就是最陡下降法(SD),取为 Hessian 矩阵的逆,就是牛顿方法。
一般人喜欢用最陡下降法:
x r + 1 = x r − α r ∇ f ( x r ) , r = 0 , 1 , ⋯ \mathbf{x}^{r+1}=\mathbf{x}^{r}-\alpha_{r} \nabla f\left(\mathbf{x}^{r}\right), r=0,1, \cdots xr+1=xr−αr∇f(xr),r=0,1,⋯
步长选取
一个重要的问题是,这里的步长怎么选。一个方法是去精确线搜索步长,即在搜索方向上选取是函数值最小的 α \alpha α,但是这个有一个问题,就是计算量很大,工业上一般不用的。
下面我给一个步长:
x r + 1 = x r − 1 L ∇ f ( x r ) \mathrm{x}^{r+1}=\mathrm{x}^{r}-\frac{1}{L} \nabla f\left(\mathrm{x}^{r}\right) xr+1=xr−L1∇f(xr)
理论上能证明,它能保证函数值的重复下降和算法收敛到一个局部极值:
f ( x r + 1 ) ≤ f ( x r ) − 1 2 L ∥ ∇ f ( x r ) ∥ 2 f\left(\mathrm{x}^{r+1}\right) \leq f\left(\mathrm{x}^{r}\right)-\frac{1}{2 L}\left\|\nabla f\left(\mathrm{x}^{r}\right)\right\|^{2} f(xr+1)≤f(xr)−2L1∥∇f(xr)∥2
这里的 L L L 是 ∇ 2 f ( x ) \nabla^{2} f(\mathbf{x}) ∇2f(x) 特征值的一个界,
∇ 2 f ( x ) ⪯ L I \nabla^{2} f(\mathbf{x}) \preceq L \mathbf{I} ∇2f(x)⪯LI
换言之,它也是梯度的一个利普希茨常数。
∥ ∇ f ( x ) − ∇ f ( y ) ∥ ≤ L ∥ x − y ∥ , ∀ x , y ∈ R n \|\nabla f(\mathbf{x})-\nabla f(\mathbf{y})\| \leq L\|\mathbf{x}-\mathbf{y}\|, \forall \mathbf{x}, \mathbf{y} \in \mathbb{R}^{n} ∥∇f(x)−∇f(y)∥≤L∥x−y∥,∀x,y∈Rn
事实上,这里的方向不一定取梯度下降方向,只要取和负梯度方向夹角为锐角的方向,这个步长也能保证收敛到一个稳定点。
收敛率
先给结论,梯度下降法是线性收敛到局部极值的,如果是凸函数,就是收敛到最小值。
我们可以用前后两步的误差比来定义收敛率。言外之意,就是后一步的误差是前一步误差的多少阶无穷小,如果是同阶无穷小,就是线性的,如果是高阶无穷小,就是超线性的,多少阶无穷小,就是多少次收敛。
令 { x k } \left\{x_{k}\right\} {xk} 是 R n \mathbb{R}^{n} Rn 的一个序列,收敛到 x ∗ x^{*} x∗。
- Q-线性收敛说的是存在一个常数 r ∈ ( 0 , 1 ) r\in(0,1) r∈(0,1),使得当 k k k 充分大时,有:
∥ x k + 1 − x ∗ ∥ ∥ x k − x ∗ ∥ ≤ r \frac{\left\|x_{k+1}-x_{*}\right\|}{\left\|x_{k}-x^{*}\right\|} \leq r ∥xk−x∗∥∥xk+1−x∗∥≤r
- Q-超线性收敛指的是, p p p 是大于 1 的常数,当 k k k 充分大的时候:
∥ x k + 1 − x ∗ ∥ ∥ x k − x ∗ ∥ p ≤ β \frac{\left\|x_{k+1}-x^{*}\right\|}{\left\|x_{k}-x^{*}\right\|^p}\leq \beta ∥xk−x∗∥p∥xk+1−x∗∥≤β
- Q-二次收敛指的是,存在一个常数 M M M,使得当 k k k 充分大时,
∥ x k + 1 − x ∗ ∥ ∥ x k − x ∗ ∥ 2 ≤ M \frac{\left\|x_{k+1}-x_{*}\right\|}{\left\|x_{k}-x^{*}\right\|^{2}} \leq M ∥xk−x∗∥2∥xk+1−x∗∥≤M
容易证明,对于强凸函数,GD 是线性收敛到最小值。收敛常数 r = 1 − 1 / cond ( ∇ 2 f ) r = 1-1/\text{cond}(\nabla^2 f) r=1−1/cond(∇2f)。也就是说,Hessian 条件数越小,收敛的越快。
约束优化问题的拉格朗日乘数法
考虑约束优化问题,
minimize f ( x ) s.t. h i ( x ) = 0 , i = 1 , ⋯ , m g j ( x ) ≤ 0 , j = 1 , ⋯ , n \begin{aligned} \operatorname{minimize} & f(x) \\ \text { s.t. } & h_{i}(x)=0, \quad i=1, \cdots, m \\ & g_{j}(x) \leq 0, \quad j=1, \cdots, n \end{aligned} minimize s.t. f(x)hi(x)=0,i=1,⋯,mgj(x)≤0,j=1,⋯,n
它的拉格朗日乘数形式是,引入 λ i ≥ 0 , ν i ∈ R \lambda_{i} \geq 0 \text { ,} \nu_{i} \in \mathbb{R} λi≥0 ,νi∈R
L ( x , λ , ν ) = f ( x ) + ∑ j = 1 n λ j g j ( x ) ⏟ inequality constraints + ∑ i = 1 m ν i h i ( x ) ⏟ equality constraints L(x, \lambda, \nu)=f(x)+\underbrace{\sum_{j=1}^{n} \lambda_{j} g_{j}(x)}_{\text {inequality constraints }}+\underbrace{\sum_{i=1}^{m} \nu_{i} h_{i}(x)}_{\text {equality constraints }} L(x,λ,ν)=f(x)+inequality constraints j=1∑nλjgj(x)+equality constraints i=1∑mνihi(x)
这里,不等式约束前面的系数要大等于 0。
它的拉格朗日对偶是,取使 L L L 取得最小的用引入参数来表示的 x x x,即,
L ∗ ( λ , ν ) = inf x ∈ X L ( x , λ , ν ) = inf x ∈ X f ( x ) + ∑ j = 1 n λ j g j ( x ) + ∑ i = 1 m ν i h i ( x ) L^{*}(\lambda, \nu)=\inf _{x \in X} L(x, \lambda, \nu)=\inf _{x \in X} f(x)+\sum_{j=1}^{n} \lambda_{j} g_{j}(x)+\sum_{i=1}^{m} \nu_{i} h_{i}(x) L∗(λ,ν)=x∈XinfL(x,λ,ν)=x∈Xinff(x)+j=1∑nλjgj(x)+i=1∑mνihi(x)
那么,对偶问题就是,
max λ , ν L ∗ ( λ , ν ) , s.t. λ ≥ 0 \max _{\lambda, \nu} L^{*}(\lambda, \nu), \quad \text { s.t. } \lambda \geq 0 λ,νmaxL∗(λ,ν), s.t. λ≥0
这里的拉格朗日对偶是一个凸函数,即使 f f f 是个非凸函数,这也就体现了求解对偶问题的优势所在。另外, L ∗ ( λ , ν ) ≤ f ∗ L^{*}(\lambda, \nu) \leq f^{*} L∗(λ,ν)≤f∗,即 L ∗ L^{*} L∗ 是 f ∗ f^* f∗的下界。
次梯度算法
次梯度是梯度的一个非可微推广,它是一个“梯度”集合,使得从某一点往附近走一个梯度步,比原来的函数值小。
∂ f ( x ) : = { g ∣ f ( y ) ≥ f ( x ) + ⟨ g , y − x ⟩ , ∀ y } \partial f(x):=\{g \mid f(y) \geq f(x)+\langle g, y-x\rangle, \forall y\} ∂f(x):={g∣f(y)≥f(x)+⟨g,y−x⟩,∀y}
所谓的次梯度算法,就是用次梯度来替代原来梯度算法中的梯度,需要注意的是,次梯度算法不是一个下降算法。
假设 T T T 是迭代次数,那么次梯度算法的收敛率是 O ( 1 / T ) \mathcal{O}(1 / \sqrt{T}) O(1/T),远远差于梯度算法的收敛率 O ( 1 / T ) ) \mathcal{O}(1 / T)) O(1/T))。简单地说,目标函数越光滑,越凸,那么收敛速度就越快。
图谱理论基础
对于一张图,我们可以定义它的关联矩阵(incidence matrix) A ∈ R E × M A \in \mathbb{R}^{E \times M} A∈RE×M, E , M E,M E,M 分别表示边数和点数。 它的每一行对应于每条边,每一列不为 0 的列标表示和这条边相连的节点的标号,值为 1 表示对应的是编号小的点,值为 -1 表示对应的是编号大的点。

用 d d d 表示节点的度,我们可以定义图拉普拉斯矩阵:
L : = P − 1 / 2 A T A P − 1 / 2 , with P = diag [ d 1 , ⋯ , d M ] \mathcal{L}:=P^{-1 / 2} A^{T} A P^{-1 / 2}, \text { with } P=\operatorname{diag}\left[d_{1}, \cdots, d_{M}\right] L:=P−1/2ATAP−1/2, with P=diag[d1,⋯,dM]
其实就是,
[ L ] i j = { 1 if i = j − 1 d i d j if ( i j ) ∈ E , i ≠ j 0 otherwise. [\mathcal{L}]_{i j}=\left\{\begin{array}{ll} 1 & \text { if } i=j \\ -\frac{1}{\sqrt{d_{i} d_{j}}} & \text { if }(i j) \in \mathcal{E}, i \neq j \\ 0 & \text { otherwise. } \end{array}\right. [L]ij=⎩⎪⎨⎪⎧1−didj10 if i=j if (ij)∈E,i=j otherwise.
我们也经常看到没有标准化的图拉普拉斯算子:
L : = A T A [ L ] i j = { d i if i = j − 1 if ( i j ) ∈ E , i ≠ j 0 otherwise. \begin{aligned} L &:=A^{T} A \\ [L]_{i j} &=\left\{\begin{array}{ll} d_{i} & \text { if } i=j \\ -1 & \text { if }(i j) \in \mathcal{E}, i \neq j \\ 0 & \text { otherwise. } \end{array}\right. \end{aligned} L[L]ij:=ATA=⎩⎨⎧di−10 if i=j if (ij)∈E,i=j otherwise.
那么,图拉普拉斯算子有一些性质。
[ L v ] i = 1 d i ∑ j : j ∼ i ( v ( i ) d i − v ( j ) d j ) [\mathcal{L} v]_{i}=\frac{1}{\sqrt{d_{i}}} \sum_{j: j \sim i}\left(\frac{v(i)}{\sqrt{d_{i}}}-\frac{v(j)}{\sqrt{d_{j}}}\right) [Lv]i=di1j:j∼i∑(div(i)−djv(j))
[ L v ] i = ∑ j : j ∼ i ( v ( i ) − v ( j ) ) [L v]_{i}=\sum_{j: j \sim i}(v(i)-v(j)) [Lv]i=j:j∼i∑(v(i)−v(j))
v T L v = ∑ i ∼ j ( v ( i ) − v ( j ) ) 2 ≥ 0 v^{T} L v=\sum_{i \sim j}(v(i)-v(j))^{2} \geq 0 vTLv=i∼j∑(v(i)−v(j))2≥0
假设, λ 0 ≤ λ 1 ≤ λ 2 ≤ ⋯ , ≤ λ M \lambda_{0} \leq \lambda_{1} \leq \lambda_{2} \leq \cdots, \leq \lambda_{M} λ0≤λ1≤λ2≤⋯,≤λM
是 $ \mathcal{L}$ 的特征值。 λ min \lambda_{\min } λmin是非零最小特征值。
那么我们可以定义谱隙(Eigengap)为:
ξ ( L ) = λ min ( L ) / λ M ≤ 1 \xi(\mathcal{L})={\lambda}_{\min }(\mathcal{L}) / \lambda_{M}\leq 1 ξ(L)=λmin(L)/λM≤1
某种意义上,它是矩阵条件数的倒数。
那么,对于图拉普拉斯矩阵,有如下的一些额外性质:
- P 1 / 2 1 P^{1 / 2} 1 P1/21 是 L \mathcal{L} L 的对应于 0 特征值的特征向量。
- λ 1 = inf f ⊥ P 1 / 2 1 ‾ ∑ u ∼ v ( f ( u ) − f ( v ) ) 2 ∑ v f ( v ) 2 d v \lambda_{1}=\inf _{f \perp P^{1 / 2} \underline{1}} \frac{\sum_{u \sim v}(f(u)-f(v))^{2}}{\sum_{v} f(v)^{2} d_{v}} λ1=inff⊥P1/21∑vf(v)2dv∑u∼v(f(u)−f(v))2
- ∑ i λ i ≤ M \sum_{i} \lambda_{i} \leq M ∑iλi≤M
- λ i ≤ 2 , for all i ≤ M \lambda_{i} \leq 2, \text { for all } i \leq M λi≤2, for all i≤M
- λ 1 ≥ 1 D × Vol ( G ) \lambda_{1} \geq \frac{1}{D \times \operatorname{Vol}(G)} λ1≥D×Vol(G)1,这里的 D D D是图的最长路径, vol ( G ) = ∑ i = 1 M d i \operatorname{vol}(G)=\sum_{i=1}^{M} d_{i} vol(G)=∑i=1Mdi。
平均一致性问题
模型问题
好,有了一些预备知识,我们来看一下分布式优化的一些东西。考虑一个无约束多代理优化问题,
minimize x ∑ i = 1 m f i ( x ) x ∈ R \operatorname{minimize}_{x} \sum_{i=1}^{m} f_{i}(x) \quad x \in \mathbb{R}^{} minimizexi=1∑mfi(x)x∈R
这表示有 m 个代理节点,每个节点都有自己的一个优化目标函数,但是他们的优化变量 x x x 是shared 的。
容易想到,如果我们用梯度下降方法(在分布式优化中叫做 DGD),因为每个 f i f_i fi 的最优值点在不同的位置,我们很难找到一个 x x x,使得每个 ∇ f i ( x ) = 0 \nabla f_i(x)= 0 ∇fi(x)=0。这个后面还会提到。
梯度算法
考虑分布式的次梯度算法,
x i ( k + 1 ) = ∑ j = 1 m w i j ( k ) x j ( k ) ⏟ Consensus Step − α × d i ( k ) ⏟ Subgradient Step x_{i}(k+1)=\underbrace{\sum_{j=1}^{m} w_{i j}(k) x_{j}(k)}_{\text {Consensus Step }}-\underbrace{\alpha \times d_{i}(k)}_{\text {Subgradient Step }} xi(k+1)=Consensus Step j=1∑mwij(k)xj(k)−Subgradient Step α×di(k)
这里的一致性步骤,其实就把其他点的 x i x_i xi 值做一个线性组合作为作为自身的 x i x_i xi 值,注意到,这里的 d i d_i di,其实还是一致性步骤之前对应的梯度值。写成矩阵的形式,其实就是,
x ( k + 1 ) = W ( k + 1 ) x ( k ) + α × d ( k ) x(k+1)=W(k+1) x(k)+\alpha \times d(k) x(k+1)=W(k+1)x(k)+α×d(k)
这里的 W W W其实是某种意义下的邻接矩阵,如果节点 i i i 和节点 j j j 有连接,那么 w i j w_{ij} wij(矩阵的第 i i i 行第 j j j 列)就大于零,否则等于零。这里也可以看到 W W W 在迭代中可以是变化的。
收敛性结果
为了后续的分析,我们定义个转移矩阵,
Φ ( k , s ) = W ( k ) W ( k − 1 ) ⋯ W ( s + 1 ) W ( s ) \Phi(k, s)=W(k) W(k-1) \cdots W(s+1) W(s) Φ(k,s)=W(k)W(k−1)⋯W(s+1)W(s)
一个向量,非负且和为 1,那么我们称之为随机向量,如果矩阵的每一行是一个随机向量,我们称之为随机矩阵,如果随机矩阵的每一列都是随机向量,那么我们称之为双随机矩阵。
我们可以定义每一步的边集,
ξ ( W ( k ) ) = { ( j , i ) ∣ w i j ( k ) > 0 , i , j = 1 , ⋯ , m } for all k \xi(W(k))=\left\{(j, i) \mid w_{i j}(k)>0, i, j=1, \cdots, m\right\} \text { for all } k ξ(W(k))={(j,i)∣wij(k)>0,i,j=1,⋯,m} for all k
这里我们需要对 W W W做一些假设。
假设1:
- 双随机
- 正对角
- 存在 η > 0 \eta > 0 η>0,当 w i j > 0 w_{ij}>0 wij>0,则 w i j ≥ η w_{ij}\geq \eta wij≥η
假设2(保证连接足够频繁):
存在一个正整数 B B B,对每一个 k k k ,我们有图
G : = ( N , ξ ( W ( k B ) ) ∪ ⋯ ∪ ξ ( W ( ( k + 1 ) B − 1 ) ) ) G:=(\mathcal{N}, \xi(W(k B)) \cup \cdots \cup \xi(W((k+1) B-1))) G:=(N,ξ(W(kB))∪⋯∪ξ(W((k+1)B−1)))
是全连接的。换言之,我们要让连接足够多,从而保证 B B B 长度窗口内的图的合并是全连接的。
在这两个假设之下,考虑简单的情况,即目标函数的梯度是 0 0 0,迭代可以写成,
x ( k + 1 ) = W ( k ) x ( k ) , k = 1 , 2 , ⋯ x(k+1)=W(k) \boldsymbol{x}(k), \quad k=1,2, \cdots x(k+1)=W(k)x(k),k=1,2,⋯
那么迭代最后会收敛到每个分量都等于开始时迭代变量在分量上的平均值。而且收敛的速度非常快。更一般的情况,我们其实也可以证明 Φ ( k , s ) \Phi(k, s) Φ(k,s) 收敛到平均 x ˉ ( 0 ) \bar{x}(0) xˉ(0)。转移矩阵收敛了,意味着算法其实就收敛了。有以下定理,

对于去中心化的梯度下降方法
凸问题的 DGD 算法
我们前面提到了,对于求解凸目标函数
minimize x ∑ i = 1 m f i ( x ) x ∈ R \operatorname{minimize}_{x} \sum_{i=1}^{m} f_{i}(x) \quad x \in \mathbb{R}^{} minimizexi=1∑mfi(x)x∈R
它的 DGD 算法,
x ( k + 1 ) = W ( k + 1 ) x ( k ) + α × d ( k ) x(k+1)=W(k+1) x(k)+\alpha \times d(k) x(k+1)=W(k+1)x(k)+α×d(k)
是很难刚好得到使得每个 f i f_i fi 都是极值的 x x x 的。这个在直觉上非常好理解,这种点可能就不存在。那么对目标函数求和的这个极小要怎么达到呢?
为了保证 DGD 算法的收敛,除了上述的假设 1、假设 2,我们还需要有假设 3:目标函数的次梯度是一致有界的,即
∥ g ∥ ≤ L for all g ∈ ∂ f i ( x ) \|g\| \leq L \quad \text { for all } g \in \partial f_{i}(x) ∥g∥≤L for all g∈∂fi(x)
通过定义辅助变量以及观察方差等手段,我们最后可以证明如下的定理:

一些结论和讨论
也就是说,在一定的假设下(1 2 3),DGD 算法其实是收敛到解的一个领域。这使得后来有些人设计了一些算法,通过减少步长到 0 的方法,使得能够收敛到精确解,但是收敛速度是很慢的。除了减少步长,当然也有一些其他的方法,可以使解收敛到精确值,比如说 ADMM 方法 EXTRA 方法。
另外,上面提到的 DGD 收敛性分析只对凸问题,一些非凸问题上,也有人做了一些工作,在一定的假设之下, DGD 算法呢,在凸情形下能收敛到全局极小值,非凸问题能收敛到某个稳定点。
凸问题的较新方法
ADMM(原始-对偶)
对偶上升
考虑问题
minimize x f ( x ) subject to A x = b \begin{array}{ll} \text { minimize }_{x} & f(x) \\ \text { subject to } & A x=b \end{array} minimize x subject to f(x)Ax=b
它的对偶上升其实就是利用梯度上升的方法求解它的对偶问题:
x k + 1 = argmin x { L ( x , y k ) = f ( x ) + ( y k ) T ( A x − b ) } y k + 1 = y k + α k ( A x k + 1 − b ) \begin{array}{l} x^{k+1}=\operatorname{argmin}_{x}\left\{L\left(x, y^{k}\right)=f(x)+\left(y^{k}\right)^{T}(A x-b)\right\} \\ y^{k+1}=y^{k}+\alpha^{k}\left(A x^{k+1}-b\right) \end{array} xk+1=argminx{L(x,yk)=f(x)+(yk)T(Ax−b)}yk+1=yk+αk(Axk+1−b)
对偶分解
考虑分布式的优化,对偶分解模型问题是把原来的目标函数,分解成几个目标函数的求和,是一个子问题:
minimize x ∑ i = 1 m f i ( x i ) subject to A x = b \begin{array}{ll} \text { minimize }_{x} & \sum_{i=1}^{m} f_{i}\left(x_{i}\right) \\ \text { subject to } & A x=b \end{array} minimize x subject to ∑i=1mfi(xi)Ax=b
那么我们再用对偶上升的方法,其实会发现,原来的拉格朗日函数关于 i i i 就是可分的,我们可以把对偶上升中,关于 x x x 的最小化,分成若干个 x i x_i xi 的最小化:
x i k + 1 = argmin x i { L i ( x i , y k ) = f i ( x i ) + ( y k ) T A i x i − ( 1 / m ) ( y k ) T b } y k + 1 = y k + α k ( A x k + 1 − b ) \begin{aligned} \boldsymbol{x}_{i}^{k+1} &=\underset{\boldsymbol{x}_{i}}{\operatorname{argmin}}\left\{L_{i}\left(\boldsymbol{x}_{i}, \boldsymbol{y}^{k}\right)=f_{i}\left(\boldsymbol{x}_{i}\right)+\left(\boldsymbol{y}^{k}\right)^{T} A_{i} \boldsymbol{x}_{i}-(1 / m)\left(\boldsymbol{y}^{k}\right)^{T} b\right\} \\ \boldsymbol{y}^{k+1} &=\boldsymbol{y}^{k}+\alpha^{k}\left(A \boldsymbol{x}^{k+1}-b\right) \end{aligned} xik+1yk+1=xiargmin{Li(xi,yk)=fi(xi)+(yk)TAixi−(1/m)(yk)Tb}=yk+αk(Axk+1−b)
增广拉格朗日方法
上面提到的对偶方法,有个好处就是可以梯度下降步,分成 m m m 个梯度下降,缺点在于需要目标函数的强凸性,才能保证算法的收敛。如果不是强凸的,只是凸的,怎么办?可以总增广拉格朗日方法。
同样是的问题,多了个一个惩罚项,
minimize x f ( x ) + ρ 2 ∥ A x − b ∥ 2 subject to A x = b \begin{array}{ll} \text { minimize }_{x} & f(x)+\frac{\rho}{2}\|A x-b\|^{2} \\ \text { subject to } & A x=b \end{array} minimize x subject to f(x)+2ρ∥Ax−b∥2Ax=b
同样利用对偶上升,得到
x k + 1 = argmin x { L ρ ( x , y k ) = f ( x ) + ( y k ) T ( A x − b ) + ρ 2 ∥ A x − b ∥ 2 } ⏟ Augmented Lagrangian y k + 1 = y k + α k ( A x k + 1 − b ) \begin{aligned} \boldsymbol{x}^{k+1}=\underset{\boldsymbol{x}}{\operatorname{argmin}}\{\underbrace{\left.L_{\rho}\left(\boldsymbol{x}, \boldsymbol{y}^{k}\right)=f(\boldsymbol{x})+\left(\boldsymbol{y}^{k}\right)^{T}(A \boldsymbol{x}-b)+\frac{\rho}{2}\|A \boldsymbol{x}-b\|^{2}\right\}}_{\text {Augmented Lagrangian }}\\ \boldsymbol{y}^{k+1}=\boldsymbol{y}^{k}+\alpha^{k}\left(A \boldsymbol{x}^{k+1}-b\right) \end{aligned} xk+1=xargmin{Augmented Lagrangian Lρ(x,yk)=f(x)+(yk)T(Ax−b)+2ρ∥Ax−b∥2}yk+1=yk+αk(Axk+1−b)
可以看到,这里就不能分解每一步的求最小值了。
ADMM 及其收敛性
交替方向乘子法,考虑的是两个凸的有各自的变量的函数求和作为目标函数,如果只有一个优化变量,是可以引入一个变量,根据约束强行凑成这种形式,
minimize x , z f ( x ) + g ( z ) subject to A x + B z = c \begin{array}{l} \text { minimize }_{x, z} f(x)+g(z) \\ \text { subject to } A x+B z=c \end{array} minimize x,zf(x)+g(z) subject to Ax+Bz=c
它的增广拉格朗日是,
L ρ ( x , z , y ) = f ( x ) + g ( z ) + y T ( A x + B z − c ) + ρ 2 ∥ A x + B z − c ∥ 2 L_{\rho}(\boldsymbol{x}, \boldsymbol{z}, \boldsymbol{y})=f(\boldsymbol{x})+g(\boldsymbol{z})+\boldsymbol{y}^{T}(A \boldsymbol{x}+B \boldsymbol{z}-c)+\frac{\rho}{2}\|A \boldsymbol{x}+B z-c\|^{2} Lρ(x,z,y)=f(x)+g(z)+yT(Ax+Bz−c)+2ρ∥Ax+Bz−c∥2
同样,利用对偶上升的方法,得到 ADMM 的迭代,
x k + 1 = argmin x L ρ ( x , z k , y k ) z k + 1 = argmin z L ρ ( x k + 1 , z , y k ) y k + 1 = y k + ρ ( A x k + 1 + B z k + 1 − c ) \begin{aligned} \boldsymbol{x}^{k+1} &=\underset{\boldsymbol{x}}{\operatorname{argmin}} L_{\rho}\left(\boldsymbol{x}, \boldsymbol{z}^{k}, \boldsymbol{y}^{k}\right) \\ \boldsymbol{z}^{k+1} &=\underset{\boldsymbol{z}}{\operatorname{argmin}} L_{\rho}\left(\boldsymbol{x}^{k+1}, \boldsymbol{z}, \boldsymbol{y}^{k}\right) \\ \boldsymbol{y}^{k+1} &=\boldsymbol{y}^{k}+\rho\left(A \boldsymbol{x}^{k+1}+B \boldsymbol{z}^{k+1}-c\right) \end{aligned} xk+1zk+1yk+1=xargminLρ(x,zk,yk)=zargminLρ(xk+1,z,yk)=yk+ρ(Axk+1+Bzk+1−c)
这个算法计算的消耗量是很大的,但很快收敛到一定的精度,要收敛到高精度很难。对大规模机器学习问题很够了,而且可以分布式地计算。
在以下两个假设之下,ADMM 在残差、目标函数、对偶变量的收敛性方面是有保证的。
- f f f 和 g g g 分别是扩展的实数函数 R n x → R ∪ { + ∞ } \mathbb{R}^{n_{x}} \rightarrow \mathbb{R} \cup\{+\infty\} Rnx→R∪{+∞}和 g : R n z → R ∪ { + ∞ } g: \mathbb{R}^{n_{z}} \rightarrow \mathbb{R} \cup\{+\infty\} g:Rnz→R∪{+∞},且是closed、proper和convex的。
- 拉格朗日函数 L 0 ( x , z , y ) = f ( x ) + g ( z ) + y T ( A x + B z − c ) L_{0}(\boldsymbol{x}, \boldsymbol{z}, \boldsymbol{y})=f(\boldsymbol{x})+g(\boldsymbol{z})+\boldsymbol{y}^{T}(A \boldsymbol{x}+B \boldsymbol{z}-c) L0(x,z,y)=f(x)+g(z)+yT(Ax+Bz−c)有一个鞍点。
分布式 ADMM 算法
一提到分布式,我们的问题其实就变成了,
minimize x ∑ i = 1 m f i ( x ) \operatorname{minimize}_{x} \sum_{i=1}^{m} f_{i}(x) minimizexi=1∑mfi(x)
为了用上提到的算法,我们有两种问题书写方式。
一个是中心化的分布式优化写法,一个节点负责收集它们的数据进行处理:
minimize x 1 , … , x m , z ∑ i = 1 m f i ( x i ) subject to x i = z , i = 1 , … , m \operatorname{minimize}_{x_{1}, \ldots, x_{m}, z} \sum_{i=1}^{m} f_{i}\left(x_{i}\right) \text { subject to } x_{i}=z, i=1, \ldots, m minimizex1,…,xm,zi=1∑mfi(xi) subject to xi=z,i=1,…,m
把它凑成 ADMM 模型问题的写法,就能得到 ADMM 步骤:
x i k + 1 = argmin x i f i ( x i ) + ρ 2 ∥ x i − z k + u i k ∥ 2 z k + 1 = 1 m ∑ i = 1 m ( x i k + 1 + u i k ) u i k + 1 = u i k + x i k + 1 − z k + 1 \begin{aligned} \boldsymbol{x}_{i}^{k+1} &=\underset{\boldsymbol{x}_{i}}{\operatorname{argmin}} f_{i}\left(\boldsymbol{x}_{i}\right)+\frac{\rho}{2}\left\|\boldsymbol{x}_{i}-\boldsymbol{z}^{k}+\boldsymbol{u}_{i}^{k}\right\|^{2} \\ \boldsymbol{z}^{k+1} &=\frac{1}{m} \sum_{i=1}^{m}\left(\boldsymbol{x}_{i}^{k+1}+\boldsymbol{u}_{i}^{k}\right) \\ \boldsymbol{u}_{i}^{k+1} &=\boldsymbol{u}_{i}^{k}+\boldsymbol{x}_{i}^{k+1}-\boldsymbol{z}^{k+1} \end{aligned} xik+1zk+1uik+1=xiargminfi(xi)+2ρ∥∥xi−zk+uik∥∥2=m1i=1∑m(xik+1+uik)=uik+xik+1−zk+1
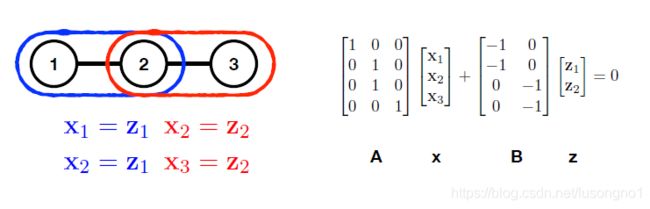
去中心化的优化写法为:
minimize { x i } , { z i j } ∑ i = 1 m f i ( x i ) subject to x i = z i j , x j = z i j , ∀ ( i , j ) ∈ A \begin{array}{l} \text { minimize }\left\{x_{i}\right\},\left\{z_{i j}\right\} \sum_{i=1}^{m} f_{i}\left(x_{i}\right) \\ \text { subject to } x_{i}=z_{i j}, x_{j}=z_{i j}, \forall(i, j) \in \mathcal{A} \end{array} minimize {xi},{zij}∑i=1mfi(xi) subject to xi=zij,xj=zij,∀(i,j)∈A
这表示,相邻的节点的值,都等于同一个值(边上的值)。容易写成如下的标准 ADMM 模型问题表达:
minimize x , z f ( x ) + g ( z ) subject to A x + B z = 0 \begin{array}{l} \text { minimize }_{\boldsymbol{x}, \boldsymbol{z}} f(\boldsymbol{x})+g(\boldsymbol{z}) \\ \text { subject to } A \boldsymbol{x}+B \boldsymbol{z}=0 \end{array} minimize x,zf(x)+g(z) subject to Ax+Bz=0
这里的 g = 0 g=0 g=0, A = [ A 1 ; A 2 ] A=\left[A_{1} ; A_{2}\right] A=[A1;A2], B = [ − I 2 E ; − I 2 E ] B=\left[-I_{2 E} ;-I_{2 E}\right] B=[−I2E;−I2E], A 1 , A 2 A_1,A_2 A1,A2表示的是某个边(row)对应的第1个和第二个点的编号(column),细想一下就知道了。
写出它的增广拉格朗日函数,
L ρ ( x , z , y ) = f ( x ) + y T ( A x + B z ) + ρ 2 ∥ A x + B z ∥ 2 L_{\rho}(\boldsymbol{x}, \boldsymbol{z}, \boldsymbol{y})=f(\boldsymbol{x})+\boldsymbol{y}^{T}(A \boldsymbol{x}+B \boldsymbol{z})+\frac{\rho}{2}\|A \boldsymbol{x}+B \boldsymbol{z}\|^{2} Lρ(x,z,y)=f(x)+yT(Ax+Bz)+2ρ∥Ax+Bz∥2
进行如下的 ADMM 更新,
x − update : ∇ f ( x k + 1 ) + A T y k + ρ A T ( A x k + 1 + B z k ) = 0 z − update : B T y k + ρ B T ( A x k + 1 + B z k + 1 ) = 0 y − update: y k + 1 − y k − ρ ( A x k + 1 + B z k + 1 ) = 0 \begin{array}{l} x-\text { update }: \quad \nabla f\left(x^{k+1}\right)+A^{T} y^{k}+\rho A^{T}\left(A x^{k+1}+B z^{k}\right)=0 \\ z-\text { update }: \quad B^{T} y^{k}+\rho B^{T}\left(A x^{k+1}+B z^{k+1}\right)=0 \\ y-\text { update: } \quad y^{k+1}-y^{k}-\rho\left(A x^{k+1}+B z^{k+1}\right)=0 \end{array} x− update :∇f(xk+1)+ATyk+ρAT(Axk+1+Bzk)=0z− update :BTyk+ρBT(Axk+1+Bzk+1)=0y− update: yk+1−yk−ρ(Axk+1+Bzk+1)=0
当然,这里实际操作上有一些细节需要去思考的。
EXTRA和其他方法
对于凸问题,除了 ADMM 算法,还有一些别的现代化算法,比如EXTRA 算法、梯度追踪、梯度推进方法等。
EXTRA 算法可以参考这个链接:EXTRA算法。就不再细述了。
它的收敛性也是需要一些假设来保证的。别的凸优化算法就不再说了。
非凸问题方法
上面提到的 DGD,以及原始-对偶方法都是对于凸问题而言的,那么,对于非凸问题,他们的表现如何呢?
DGD(常步长和递减步长)
和对于凸问题一样,常数步长的 DGD 算法只能收敛到精确稳定点的一个小领域,在一些假设下,递减步长的 DGD 也是可以收敛到某个稳定点的。
对于递减步长,我们可以设计每次迭代的补充,加上一些假设,比如关于 W W W 的一些假设,关于 f f f 的一些假设等等,能保证算法收敛到稳定点。
这个事情比较繁琐,有兴趣的可以参考相关文献,不再细述。
另外需要提到的一点是,一般去中心化对应的方法,比中心化对应的方法,需要更强的假设,才能保证收敛。
原始-对偶方法
我们从简单的星网络(一个中心点连着其他点)开始考虑,
min ∑ i = 1 m g i ( x i ) + h ( x ) subject to x i = x , ∀ i = 1 , ⋯ , m , x ∈ X \begin{array}{c} \min \sum_{i=1}^{m} g_{i}\left(x_{i}\right)+h(x) \\ \text { subject to } x_{i}=x, \forall i=1, \cdots, m, \quad x \in X \end{array} min∑i=1mgi(xi)+h(x) subject to xi=x,∀i=1,⋯,m,x∈X
这里的 h ( x ) h(x) h(x) 可以看成是中心节点的目标函数。
它的增广拉格朗日函数可以写成,
L ( { x k } , x ; y ) = ∑ k = 1 K g k ( x k ) + h ( x ) + ∑ k = 1 K ⟨ y k , x k − x ⟩ + ∑ k = 1 K ρ k 2 ∥ x k − x ∥ 2 L\left(\left\{x_{k}\right\}, x ; y\right)=\sum_{k=1}^{K} g_{k}\left(x_{k}\right)+h(x)+\sum_{k=1}^{K}\left\langle y_{k}, x_{k}-x\right\rangle+\sum_{k=1}^{K} \frac{\rho_{k}}{2}\left\|x_{k}-x\right\|^{2} L({xk},x;y)=k=1∑Kgk(xk)+h(x)+k=1∑K⟨yk,xk−x⟩+k=1∑K2ρk∥xk−x∥2
然后,就可以在其上执行对于一致性问题的经典的 ADMM 算法,那么这个收敛性如何。
找一个例子试一下,你会发现,和凸问题不一样的是,它这里的收敛性是依赖于 ρ \rho ρ 的, ρ \rho ρ 太小,不收敛, ρ \rho ρ 大了,可能收敛。
其实,在一定的假设之下(赘述繁琐,不再说了),可以保证其收敛性。
把星网络,推广到一般的分布式的情况,即考虑非凸的去中心化问题,
min f ( x ) : = ∑ i = 1 m g i ( x i ) subject to x i = x j , ( i , j ) ∈ E \min f(x):=\sum_{i=1}^{m} g_{i}\left(x_{i}\right) \text { subject to } x_{i}=x_{j},(i, j) \in E minf(x):=i=1∑mgi(xi) subject to xi=xj,(i,j)∈E
往星网络的形式靠拢,引入 h h h,
min { x i } ∑ i = 1 m f i ( x i ) + h i ( x i ) \min _{\left\{x_{i}\right\}} \sum_{i=1}^{m} f_{i}\left(x_{i}\right)+h_{i}\left(x_{i}\right) {xi}mini=1∑mfi(xi)+hi(xi)
A x = 0 ( consensus constraint ) A x=0 \quad(\text { consensus constraint }) Ax=0( consensus constraint )
这里的 A A A 就是之前预备知识提到的关联矩阵。
我们考虑更一般的线性约束问题,
min x ∈ R m f ( x ) , subject to A x = b \min _{\boldsymbol{x} \in \mathbb{R}^{m}} f(\boldsymbol{x}), \quad \text { subject to } A \boldsymbol{x}=b x∈Rmminf(x), subject to Ax=b
有所谓的近端原始对偶方法,以及增广拉格朗日算法等等。
和前面的讨论相同,在一些假设之下,这些算法是可以以次线性的速度收敛到稳定点的。
随机问题的方法
随机梯度下降方法(SGD)
这里的随机,不太是随机过程那个随机,更像是神经网络中,mini-batch 随机梯度下降的那个随机,随机有 sample 的含义。
它对于凸和非凸的问题,都有收敛性的保证,但收敛性比起 GD 需要更强的条件。
学过机器学习的都很了解 SGD 了,这里简单用期望形式简单描述一下。
考虑问题,
minimize x F ( x ) : = 1 N ∑ i = 1 N f ( x , { a i , b i } ) subject to x ∈ R n \begin{array}{ll} \operatorname{minimize}_{x} & F(\boldsymbol{x}):=\frac{1}{N} \sum_{i=1}^{N} f\left(\boldsymbol{x},\left\{\mathbf{a}_{i}, b_{i}\right\}\right) \\ \text { subject to } & \boldsymbol{x} \in \mathbb{R}^{n} \end{array} minimizex subject to F(x):=N1∑i=1Nf(x,{ai,bi})x∈Rn
和神经网络的 loss function 类比,这里 F ( x ) F(x) F(x)是我们要得到的模型, { a i , b i } \{a_i,b_i\} {ai,bi} 是我们用来训练模型的数据,这里的 N N N,表示采用 N N N 个数据点。如果采用的数据点足够均匀,那么,
F ( x ) = E i [ f ( x , { a i , b i } ) ] F(\boldsymbol{x})=\mathbb{E}_{i}\left[f\left(\boldsymbol{x},\left\{\mathbf{a}_{i}, b_{i}\right\}\right)\right] F(x)=Ei[f(x,{ai,bi})]
随机梯度下降就是,
x r + 1 = x r − η r g r \boldsymbol{x}^{r+1}=\boldsymbol{x}^{r}-\eta^{r} \mathbf{g}^{r} xr+1=xr−ηrgr
这里的 g r \mathbf{g}^{r} gr 是 E [ ∇ f ( x r , ξ ) ] \mathbb{E}\left[\nabla f\left(\boldsymbol{x}^{r}, \xi\right)\right] E[∇f(xr,ξ)] 一个无偏估计。
去中心化随机梯度下降方法(DSGD or SDGD)
为什么要有分布式的随机梯度算法呢?因为现实中,往往计算节点的很多数据都是实时和在线的,我们往往拿步到全部数据,从而计算全导数。即使每个节点能拿到自己的全部数据,当计算节点很多的时候,要计算所有节点的全导数,这个计算量是巨大的。所以,我们再分布式优化中,更需要随机的梯度方法。
假设现在有 m 个节点,每个节点都有自己的模型,以及自己的好多好多个数据,那么,去中心化的随机问题就是,
minimize x F ( x ) : = ∑ i = 1 m E ξ i [ g i ( x , ξ i ) ] : = ∑ i = 1 m f i ( x ) _{x} \quad F(x):=\sum_{i=1}^{m} \mathbb{E}_{\xi_{i}}\left[g_{i}\left(x, \xi_{i}\right)\right]:=\sum_{i=1}^{m} f_{i}(x) xF(x):=∑i=1mEξi[gi(x,ξi)]:=∑i=1mfi(x)
subject to x ∈ R n x \in \mathbb{R}^{n} x∈Rn
对于每个节点,我们不取全部数据,而是有代表性地选取部分数据,来表示 f i f_i fi 的一个无偏估计,那么,就是对应于分布式问题的随机梯度下降方法,算法描述如下:

理论上可以证明,在一些较强的条件假设下,对于分布式问题的 DSGD 算法是收敛的。
对于分布式问题,除了所谓的梯度下降算法,还有 D 2 D^2 D2 算法、随机梯度推进算法、基于梯度追踪的非凸随机去中心化算法等等,他们又很强的相关性,这里不再展开了。
分布式优化总结和展望
问题设定
考虑非凸分布式优化问题,
( P ) min w ∈ R P h ( w ) = 1 M ∑ i = 1 M f i ( w ) (\mathbf{P}) \min _{\mathbf{w} \in \mathbb{R}^{P}} h(\mathbf{w})=\frac{1}{M} \sum_{i=1}^{M} f_{i}(\mathbf{w}) (P)w∈RPminh(w)=M1i=1∑Mfi(w)
引入 M M M 个局部变量,重建一致性问题,
(Q) min x ∈ R M P f ( x ) = 1 M ∑ i = 1 M f i ( x i ) , s.t. A x = 0 \text { (Q) } \min _{\mathbf{x} \in \mathbb{R}^{M P}} f(\mathbf{x})=\frac{1}{M} \sum_{i=1}^{M} f_{i}\left(\mathbf{x}_{i}\right), \quad \text { s.t. } \mathbf{A x}=0 (Q) x∈RMPminf(x)=M1i=1∑Mfi(xi), s.t. Ax=0
这里的 A A A 是关联矩阵,体现了网络的结构,每个节点只能和它的邻居进行通信。
凸问题方法
DGD 算法就是
x r + 1 = W x r − α ∇ f ( x r ) x i r + 1 = ∑ j ∈ N i W i j x j r − α ∇ f i ( x i r ) \begin{array}{c} \mathrm{x}^{r+1}=\mathbf{W} \mathbf{x}^{r}-\alpha \nabla f\left(\mathbf{x}^{r}\right) \\ \mathbf{x}_{i}^{r+1}=\sum_{j \in \mathcal{N}_{i}} \mathbf{W}_{i j} \mathbf{x}_{j}^{r}-\alpha \nabla f_{i}\left(\mathbf{x}_{i}^{r}\right) \end{array} xr+1=Wxr−α∇f(xr)xir+1=∑j∈NiWijxjr−α∇fi(xir)
这里的 W W W 是个随机矩阵,并且它的特征值模是被 1 绊住的。算法收敛到最优值的领域。
EXTRA 算法是,
x 1 = W x 0 − α ∇ f ( x 0 ) x r + 2 = ( W + I ) x r + 1 − W ~ x r − α ( ∇ f ( x r + 1 ) − ∇ f ( x r ) ) \begin{aligned} \mathrm{x}^{1} &=\mathbf{W} \mathbf{x}^{0}-\alpha \nabla f\left(\mathrm{x}^{0}\right) \\ \mathrm{x}^{r+2} &=(\mathbf{W}+\mathbf{I}) \mathrm{x}^{r+1}-\widetilde{\mathbf{W}} \mathrm{x}^{r}-{\alpha\left(\nabla f\left(\mathrm{x}^{r+1}\right)-\nabla f\left(\mathrm{x}^{r}\right)\right)} \end{aligned} x1xr+2=Wx0−α∇f(x0)=(W+I)xr+1−W xr−α(∇f(xr+1)−∇f(xr))
交替方向乘子法,是把问题写成下面这种形式,
min x , z f ( x ) + g ( z ) , s.t. A x + B z = 0 \min _{\mathbf{x}, \mathbf{z}} f(\mathbf{x})+g(\mathbf{z}), \quad \text { s.t. } \mathbf{A} \mathbf{x}+\mathbf{B} \mathbf{z}=0 x,zminf(x)+g(z), s.t. Ax+Bz=0
这里的 A , B A,B A,B 也体现了网络的拓扑结构。
如图所示例子,
增广拉格朗日函数为,
L ( x , z , λ ) = f ( x ) + ⟨ λ , A x + B z ⟩ + c 2 ∥ A x + B z ∥ 2 L(\mathrm{x}, \mathrm{z}, \lambda)=f(\mathrm{x})+\langle\lambda, \mathrm{Ax}+\mathrm{Bz}\rangle+\frac{c}{2}\|\mathrm{Ax}+\mathrm{Bz}\|^{2} L(x,z,λ)=f(x)+⟨λ,Ax+Bz⟩+2c∥Ax+Bz∥2
交替更新步骤是,
x update: ∇ f ( x r + 1 ) + A T λ r + c A T ( A x r + 1 + B z r ) = 0 \nabla f\left(\mathbf{x}^{r+1}\right)+\mathbf{A}^{T} \lambda^{r}+c \mathbf{A}^{T}\left(\mathbf{A} \mathbf{x}^{r+1}+\mathbf{B} \mathbf{z}^{r}\right)=0 ∇f(xr+1)+ATλr+cAT(Axr+1+Bzr)=0
z \mathbf{z} z update: B T λ r + c B T ( A x r + 1 + B z r + 1 ) = 0 \mathbf{B}^{T} \lambda^{r}+c \mathbf{B}^{T}\left(\mathbf{A} \mathbf{x}^{r+1}+\mathbf{B} \mathbf{z}^{r+1}\right)=0 BTλr+cBT(Axr+1+Bzr+1)=0
λ \lambda λ update: λ r + 1 − λ r − c ( A x r + 1 + B z r + 1 ) = 0 \lambda^{r+1}-\lambda^{r}-c\left(\mathbf{A} \mathbf{x}^{r+1}+\mathbf{B} \mathbf{z}^{r+1}\right)=0 λr+1−λr−c(Axr+1+Bzr+1)=0
非凸问题方法
这些简单的方法能不能迁移到非凸问题呢?有一些相关的工作。
原始-对偶方法考虑一致性的问题,
(Q) min x ∈ R M P f ( x ) = 1 M ∑ i = 1 M f i ( x i ) , s.t. A x = 0 \text { (Q) } \min _{\mathbf{x} \in \mathbb{R}^{M P}} f(\mathbf{x})=\frac{1}{M} \sum_{i=1}^{M} f_{i}\left(\mathbf{x}_{i}\right), \quad \text { s.t. } \mathbf{A} \mathbf{x}=0 (Q) x∈RMPminf(x)=M1i=1∑Mfi(xi), s.t. Ax=0
它的增广拉格朗日函数,
L ( x , λ ) = f ( x ) + ⟨ λ , A x ⟩ + ρ 2 ∥ A x ∥ 2 L(\mathbf{x}, \lambda)=f(\mathbf{x})+\langle\lambda, \mathbf{A} \mathbf{x}\rangle+\frac{\rho}{2}\|\mathbf{A} \mathbf{x}\|^{2} L(x,λ)=f(x)+⟨λ,Ax⟩+2ρ∥Ax∥2
算法更新为,
x r + 1 = arg min x ⟨ ∇ f ( x r ) + A T λ r + ρ A T A x r , x − x r ⟩ ⏟ linearizes the entire AL function. + β 2 ∥ x − x r ∥ 2 + ρ λ max ( A T A ) 2 ∥ x − x r ∥ 2 ⏟ λ r + 1 = λ r + ρ A x r + 1 \begin{aligned} \mathrm{x}^{r+1}=& \arg \min _{\mathrm{x}} \underbrace{\left\langle\nabla f\left(\mathrm{x}^{r}\right)+\mathrm{A}^{T} \lambda^{r}+\rho \mathrm{A}^{T} \mathrm{A} \mathrm{x}^{r}, \mathrm{x}-\mathrm{x}^{r}\right\rangle}_{\text {linearizes the entire AL function. }} \\ &+\underbrace{\frac{\beta}{2}\left\|\mathrm{x}-\mathrm{x}^{r}\right\|^{2}+\frac{\rho \lambda_{\max }\left(\mathrm{A}^{T} \mathrm{A}\right)}{2}\left\|\mathrm{x}-\mathrm{x}^{r}\right\|^{2}} \\ \lambda^{r+1}=& \lambda^{r}+\rho \mathrm{Ax}^{r+1} \end{aligned} xr+1=λr+1=argxminlinearizes the entire AL function. ⟨∇f(xr)+ATλr+ρATAxr,x−xr⟩+ 2β∥x−xr∥2+2ρλmax(ATA)∥x−xr∥2λr+ρAxr+1
它有如下的等价形式,
x r + 1 = ( I − α A T A ) ( 2 x r − x r − 1 ) − α ( ∇ f ( x r ) − ∇ f ( x r − 1 ) ) \mathbf{x}^{r+1}=\left(\mathbf{I}-\alpha \mathbf{A}^{T} \mathbf{A}\right)\left(2 \mathbf{x}^{r}-\mathbf{x}^{r-1}\right)-\alpha\left(\nabla f\left(\mathbf{x}^{r}\right)-\nabla f\left(\mathbf{x}^{r-1}\right)\right) xr+1=(I−αATA)(2xr−xr−1)−α(∇f(xr)−∇f(xr−1))
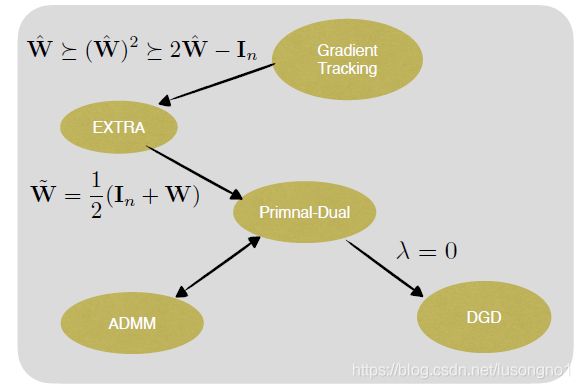
这里,如果我们选择 W = I − α A T A \mathbf{W}=\mathbf{I}-\alpha \mathbf{A}^{T} \mathbf{A} W=I−αATA,就变成了 EXTRA 算法,
x r + 1 = ( I + W ) x r − 1 2 ( I + W ) x r − 1 − α ( ∇ f ( x r ) − ∇ f ( x r − 1 ) ) \mathbf{x}^{r+1}=(\mathbf{I}+\mathbf{W}) \mathbf{x}^{r}-\frac{1}{2}(\mathbf{I}+\mathbf{W}) \mathbf{x}^{r-1}-\alpha\left(\nabla f\left(\mathbf{x}^{r}\right)-\nabla f\left(\mathbf{x}^{r-1}\right)\right) xr+1=(I+W)xr−21(I+W)xr−1−α(∇f(xr)−∇f(xr−1))
如果我们令 λ ≡ 0 \lambda \equiv 0 λ≡0,就变成了 DGD 算法,
x r + 1 = ( I − α A T A ) ⏟ : = W x r − α ∇ f ( x r ) \mathbf{x}^{r+1}=\underbrace{\left(\mathbf{I}-\alpha \mathbf{A}^{T} \mathbf{A}\right)}_{:=\mathbf{W}} \mathbf{x}^{r}-\alpha \nabla f\left(\mathbf{x}^{r}\right) xr+1=:=W (I−αATA)xr−α∇f(xr)
因为没有对偶步,更新极慢。
如果定义一个辅助变量,去追踪全局信息,就得到了梯度追踪算法(GT),
x r + 1 = W x r − α y r y r + 1 = W y r + ∇ f ( x r + 1 ) − ∇ f ( x r ) \begin{array}{l} \mathbf{x}^{r+1}=\mathbf{W} \mathbf{x}^{r}-\alpha \mathbf{y}^{r} \\ \mathbf{y}^{r+1}=\mathbf{W} \mathbf{y}^{r}+\nabla f\left(\mathbf{x}^{r+1}\right)-\nabla f\left(\mathbf{x}^{r}\right) \end{array} xr+1=Wxr−αyryr+1=Wyr+∇f(xr+1)−∇f(xr)
它的等价形式是,
x r + 1 = 2 W x r − W 2 x r − 1 − α ( ∇ f ( x r ) − ∇ f ( x r − 1 ) ) \mathbf{x}^{r+1}=2 \mathbf{W} \mathbf{x}^{r}-\mathbf{W}^{2} \mathbf{x}^{r-1}-\alpha\left(\nabla f\left(\mathbf{x}^{r}\right)-\nabla f\left(\mathbf{x}^{r-1}\right)\right) xr+1=2Wxr−W2xr−1−α(∇f(xr)−∇f(xr−1))
当这个 W W W 满足一定的条件,就变成了 EXTRA 算法。
几个算法的关系,可以用下图表示,
这些算法在网络非常大的情况下,收敛是很慢的,很多重要的网络信息被忽略了。如何追求一些最优速率的方法呢?这是一个深刻的问题。
复杂度下界
我们定义一个问题集 P L M \mathcal{P}_{L}^{M} PLM,
min x ∈ R M P f ( x ) = 1 M ∑ i = 1 M f i ( x i ) , s.t. x i = x k , ∀ ( i , k ) ∈ E \min _{\mathbf{x} \in \mathbb{R}^{M} P} \quad f(\mathbf{x})=\frac{1}{M} \sum_{i=1}^{M} f_{i}\left(\mathbf{x}_{i}\right), \quad \text { s.t. } \quad \mathbf{x}_{i}=\mathbf{x}_{k}, \quad \forall(i, k) \in \mathcal{E} x∈RMPminf(x)=M1i=1∑Mfi(xi), s.t. xi=xk,∀(i,k)∈E
这里满足一些假设,
- 每个节点对应的目标函数的导数是利普希茨连续的, ∥ ∇ f i ( x i ) − ∇ f i ( z i ) ∥ ≤ L i ∥ x i − z i ∥ , ∀ x i , z i ∈ R P , ∀ i \left\|\nabla f_{i}\left(\mathrm{x}_{i}\right)-\nabla f_{i}\left(\mathrm{z}_{i}\right)\right\| \leq L_{i}\left\|\mathrm{x}_{i}-\mathrm{z}_{i}\right\|, \forall \mathrm{x}_{i}, \mathrm{z}_{i} \in \mathbb{R}^{P}, \forall i ∥∇fi(xi)−∇fi(zi)∥≤Li∥xi−zi∥,∀xi,zi∈RP,∀i
- 函数 f f f 有下界, min x ∈ R P × M f ( x ) ≥ f ‾ \min _{x \in \mathbb{R}^{P \times M}} f(\mathbf{x}) \geq \underline{f} minx∈RP×Mf(x)≥f。
定义网络集 N M \mathcal{N}_{M} NM,它是一洗无向无权图的结合, M M M 个顶点, E E E 条变,每个点的度为 d i d_i di。
正规化的图拉普拉斯算子是,
L : = P − 1 / 2 A T A P − 1 / 2 , with P = diag [ d 1 , ⋯ , d M ] \mathcal{L}:=P^{-1 / 2} A^{T} A P^{-1 / 2}, \text { with } P=\operatorname{diag}\left[d_{1}, \cdots, d_{M}\right] L:=P−1/2ATAP−1/2, with P=diag[d1,⋯,dM]
[ L ] i j = { 1 if i = j − 1 d i d j if ( i j ) ∈ E , i ≠ j 0 otherwise. [\mathcal{L}]_{i j}=\left\{\begin{array}{ll} 1 & \text { if } i=j \\ -\frac{1}{\sqrt{d_{i} d_{j}}} & \text { if }(i j) \in \mathcal{E}, i \neq j \\ 0 & \text { otherwise. } \end{array}\right. [L]ij=⎩⎪⎨⎪⎧1−didj10 if i=j if (ij)∈E,i=j otherwise.
谱间隙是,
ξ ( L ) = λ ‾ min ( L ) / λ max ( L ) ≤ 1 \xi(\mathcal{L})=\underline{\lambda}_{\min }(\mathcal{L}) / \lambda_{\max }(\mathcal{L}) \leq 1 ξ(L)=λmin(L)/λmax(L)≤1
定义分布式的,一阶算法集 A \mathcal{A} A,
- 每次迭代一轮的信息交换,一轮的本地更新。
- 每个节点的输出是邻居集合的历史输出和梯度的一个线性组合
v i r = Q i r ( x i r ) ⏟ communication step , x i r + 1 ∈ W i r ( { { v j r } j ∈ N i , ∇ f i ( x i t ) , x i t } t = 1 r ) ⏟ computation step \mathbf{v}_{i}^{r}=\underbrace{Q_{i}^{r}\left(\mathbf{x}_{i}^{r}\right)}_{\text {communication step }}, \mathbf{x}_{i}^{r+1} \in \underbrace{W_{i}^{r}\left(\left\{\left\{\mathbf{v}_{j}^{r}\right\}_{j \in \mathcal{N}_{i}}, \nabla f_{i}\left(\mathbf{x}_{i}^{t}\right), \mathbf{x}_{i}^{t}\right\}_{t=1}^{r}\right)}_{\text {computation step }} vir=communication step Qir(xir),xir+1∈computation step Wir({{vjr}j∈Ni,∇fi(xit),xit}t=1r)
我们用 T T T 来表示迭代结果达到 ϵ \epsilon ϵ精度所用的次数。那么在一定条件下,我们有复杂度下界的估计,
T ≥ Ω ( 1 ξ ( L ) 1 ϵ × U × ( f ( 0 ) − f ‾ ) ) T \geq \Omega\left(\frac{1}{\sqrt{\xi(\mathcal{L})}} \frac{1}{\epsilon} \times U \times(f(0)-\underline{f})\right) T≥Ω(ξ(L)1ϵ1×U×(f(0)−f))
最优收敛率算法
有了复杂度下界估计,我们可以设计一些原始对偶算法,让迭代次数达到这个下界。Prox-PDA 算法达到了次最优。还有所谓的 xFILTER 算法。这些算法,往往和中心化的 GD 算法有个比较。
最近发展和开放性问题
分布式优化,最近的发展主要有几个例子:
- 经验风险最小化
- 更低样本复杂性的模型
- 随机分布式梯度下降方法
- 基于梯度追踪的随机方法
- 非凸问题优化
- 随机方差削减梯度方法(SVRG)
- 随机递归梯度算法(SARAH)
也有一些开放性的问题,待研究,譬如
- 流数据模型(数据在线输入)
- 不同的问题集。比如说,对简单的例子 f ( x ) : = x 1 3 − x 2 3 f(\mathbf{x}):=x_{1}^{3}-x_{2}^{3} f(x):=x13−x23,上述的算法都失效了。
- 更高阶解,目前大部分算法都是一阶的。
- 一致性问题之外,不考虑完全一致性问题,比如说数据可能被攻击。
- 其他问题。
联邦学习
联邦学习简介
联合学习旨在在本地节点中包含的多个本地数据集上训练算法,而无需明确交换数据样本。一般原则在于训练局部数据样本的局部模型,并以一定频率在这些局部节点之间交换参数,以生成所有节点共享的全局模型。
在联邦学习中,计算节点对数据具有绝对的控制权。中心服务器无法直接或间接操作计算节点上的数据,计算节点可以随时停止计算和通信,退出学习过程。参与联邦学习的计算节点可能是手机、平板等移动设备,这些设备因为用户的使用习惯,其所处的网络环境并不稳定,随时都可能与中心服务器断开连接。联邦学习中的计算节点可能分布在不同的地理位置,与中心服务器一般处于远程连接的状态,同时受不同设备网络带宽的影响,其通信代价要更高。在联邦学习中,并不能简单假设数据是独立同分布的,由于计算节点中的数据数据是独立产生的,他们往往表现出不同的分布特征(非独立同分布)。
它的应用程序分布在许多行业,包括国防,电信,物联网和制药,输入法预测,机器人控制。这当中存在一些问题,比如说数据不平衡(异步)、异步通信、隐私和安全。
联邦学习的系统结构一般可以画成如下图所示。

联邦学习算法
考虑 N N N 个客户,客户 i i i 有 n i n_i ni 个本地数据构成的数据集 D i D_i Di,
min x f ( x ) ≜ 1 N ∑ i = 1 N f i ( x ) where f i ( x ) ≜ 1 n i ∑ ξ i ∈ D i F ( x ; ξ i ) \min _{x} f(x) \triangleq \frac{1}{N} \sum_{i=1}^{N} f_{i}(x) \quad \text { where } \quad f_{i}(x) \triangleq \frac{1}{n_{i}} \sum_{\xi_{i} \in \mathcal{D}_{i}} F\left(x ; \xi_{i}\right) xminf(x)≜N1i=1∑Nfi(x) where fi(x)≜ni1ξi∈Di∑F(x;ξi)
来看一个算法描述。

简单地说,就是我们做迭代,每次迭代对每一个客户点我们都从 D i D_i Di 中随机选取一些数据做梯度下降。每做 Q Q Q 次迭代,我们就把所有的 x i x_i xi 值做个平均,重置 N N N 个客户点的值的 x i x_i xi 都为这个平均值。可以看到,如果这里的 Q = 1 Q=1 Q=1,就是前面提到的分布式的 SGD 算法。同样的,这里的随机选取变成取全部,就是 GD 算法。

FedAvg 算法收敛性分析
这个算法是好的算法吗?不是,如果一些条件不能满足,这个算法有可能会发散。这里说的条件,包括,
- 目标函数的光滑性
- 梯度的无偏估计
- 梯度方差的有界性
- 梯度的有界性
有很多关于保证这个算法收敛的一些研究,可能不同的假设条件,能对不同类型的目标函数有收敛性的保证,比如说,如果各个客户点的数据不是独立同分布的。
对于目标函数是凸且光滑的,那么我们选取一定的梯度下降步长,那么 GD 算法是收敛的。
这里的通讯效率也是可以量化的,怎么减少通信,也是一个非常重要的问题,包括步长的选取等等。大多数算法都不具有异构数据问题,但是 FedAvg 型算法有。