【HBase】19-HBaseAdmin
客户端提供了API的模式来管理集群,与 RDBMS中的DDL相比—客户端提供的具有管理功能的API更像是DML。
HBaseAdmin提供了建表、创建列族、检查表是否存在、修改表结构和列族结构和删除表等功能。下面我们对这些功能按操作关联性分组进行介绍。
1、基本操作
使用管理的API需要首先实例化 HBaseAdmin类,构造函数如下
HBaseAdmin(Configuration conf) throws MasterNotRunningException, ZooKeeperConnectionException本节论述中忽略了一点,管理功能API中大多数方法都拋出 IOException(或继承自它的异常),或者是 InterruptedException。前者是客户端与服务器端的通信异常,后者是执行过程中的干扰异常,例如, region服务器的执行命令在完成前被停止所引起的问题。
已有的配置实例提供了足够的配置信息,所以当前的API可以通过使用 ZooKeeper的相关配置信息查找集群,类似于普通客户端API的使用方法。具有管理功能的API实例应该在使用后进行销毁,换言之,这个实例不应该长期保留HBaseAdmin实例的生命周期不宜太长,例如,在 master故障恢复的过程中,它是短暂有效的这个类实现了 Abortable接口,并实现了以下方法:
void abort (String why, Throwable e)以上方法被框架隐式调用,例如,当发生致命连接错误或关闭集群时。用户不能直接调用这个方法,但是在紧急的情况下,例如需要完整的关机或重启时,系统会调用该方法。以下方法可以获得 master的远程对象:
HMasterInterface getMaster() throws MasterNotRunningException, ZooKeeperConnectionException上面的方法会返回 HMasterInterface接口的RPC代理实例,允许用户直接通过这个实例访问 master服务器。不过这个方法不是必须的, HBaseAdmin内置了 master所有RPC接口代理的封装。
除非用户确定自身的调用是安全的,否则不要直接调用 getMaster()来获取 HMasterInterface远程对象。 HBaseAdmin自身已经封装了HMasterInterface远程对象的调用功能,例如,检查输入是否合法,并转化成远程异常返回,或优化同步处理为异步处理以提升执行能力。
除了上述接口, HBaseAdmin类还提供了以下基本接口。
boolean isMasterRunning()
通过这个接口检査 master是否正在运行。用户也可以通过客户端程序在实例化HBaseAdmin类之前直接调用该接口确认其可以与 master通信。
HConnection getConnection()
返回连接实例。
Configuration getConfiguration()
访问创建 HBaseAdmin实例时使用到的配置实例,用户可以通过修改这个实例中的变量达到改变 HBaseAdmin APl调用时依赖的配置的目的
close()
关闭 HBaseAdmin实例的所有资源,包括与远程服务器的连接。
2、表操作
在介绍了基本操作后,下面我们介绍有关表的一系列操作。这些操作可以达到帮助表工作的目的,而非实际的内部模式。
在开始工作前,首先要做的是建表,以下API就是建表的相关方法
void createTable(HTableDescriptor desc)
void createTable(HTableDescriptor desc, byte[] startKey,byte [] endKey, int numRegions)
void createTable(HTableDescriptor desc, byte[][] splitKeys)
void createTableAsync(HTable Descriptor desc, byte[][] splitKeys)上面描述的方法都使用到了 HTableDescriptor实例,下面是一个简单的有关建表的例子。
使用客户端API建表

- 创建 HBaseAdmin实例。
- 创建表描述符。
- 添加列族描述符到表描述符中。
- 调用建表方法 createTable()
- 检查表是否可用。
另一种高级建表功能是,伴随建表操作进行预分区,将表在创建的时候划分出若干特定的 region。
使用两种预定义 region的建表方法。
通过预分区的方式建表


- 打印表中 region信息的帮助方法。
- 返回表中所有 region的起始行键与终止行键列表。
- 打印这些行键,但不包括空的行键(起始与终止)。
- 执行建表命令,同时设置 region边界
- 创建表中 region的拆分行键。
- 使用新表名和 region的已拆分键值列表作为参数调用建表命令。
以上代码例子可以得到如下的输出:
以上例子使用了 HTable类中的方法 getstartEndKeys(来获取所有 region的边界。第一个 region的起始行键与最后一个 region的终止行键都是空字节,这是 HBase中默认的规则。起始和终止行键都是已经计算好的,或是提供给用户的拆分键。需要注意的是,前一个 region的终止行键与后一个 region的起始行键是串联起来的——终止行键不包含在前一个 region中,而是作为起始行键包含在后一个region中。
createTable(HTableDescriptor desc, byte[] startKey, byte[] endKey, int numRegions)方法能够以特定数量拆分特定起始行键和特定终止行键,并创建表。参数中的 startkey必须小于 endKey,并且 numRegions需要大于等于3,否则会抛出异常,这样才能够确保
region有最小的集合。
在这个方法中, region的边界是通过终止行键减去起始行键然后除以给定的 region数量计算得到的。在上面的例子中,用户能够学习到怎样计算合适的 region数量,以保证计算出的行键可以填充表。
createTable(HTableDescriptor desc,byte[][] splitKeys)方法在例子的第二部分中被使用到,换句话说,它使用已拆分行键的集合:使用了已经拆分好的 region边界列表,因此结果都是与预期相符的。
上面提到的两种 createTable()方法实际上是有联系的, createTable(HtableDescriptor desc, byte[] startKey, byte[] endKey, int numRegions)方法使用Bytes.split()方法计算region分界,然后将计算得到的边界作为已拆分边界列表,并调用 createTable(HtableDescriptor desc, byte[][] splitKeys)方法建表
最后,还有 createTableAsync(HTableDescriptor desc,byte[][] splitKeys)方法,这个方法使用表描述符和预拆分的 region边界作为参数,并进行异步建表,但执行过程与createTable()方法殊途同归。
表的大多数管理功能都是异步的,这对发送命令而不需要等待执行结果的场景是非常有用的。但是,也有一些操作必须等待并获知操作执行成功后,才可以继续执行其他操作,因此,表提供了异步与同步两种操作模式。
实际上,同步模式仅仅是异步模式的简单封装,增加了不断检查这个任务是否已经完成的循环操作。例如, createTable()方法包装了
createTableλsync()方法,循环检查远程服务器的建表操作是否已经执行完成。
建表后用户通过下面的帮助方法可以获取所有表的列表和已创建表的表描述符,或检查该表是否存在:
boolean tableExists(String tableName)
boolean tableExists(byte[] tableName)
HTableDescriptor[] listTables()
HTableDescriptor getTableDescriptor(byte[] tableName)使用 tableExists()方法检查建表是否成功,并使用listTables()方法获取所有已建表的表描述符对象,使用 getTableDescriptor()方法获取某一个已建表的表描述符,使用了listTables()和 getTableDescriptor(),并展示了具有管理功能的API的返回值。
获取所有已建表的表结构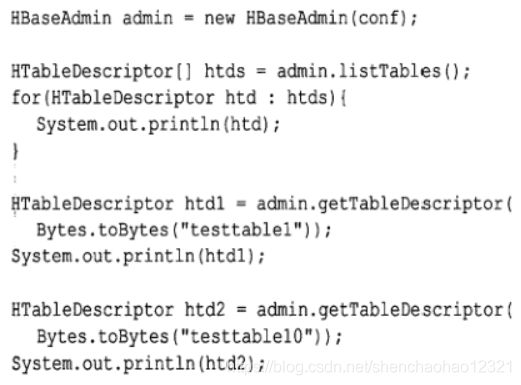

上述的异常信息值得一提,如果用户试图访问一个不存在的表描述符,就会得到上述对应的异常,因此用户在访问这个API的时候,必须使用已存在的表的表名,或者对上述的代码使用try/ catch封装来处理这些异常。
描述过建表的过程后,我们要提一下删除表的操作, HBaseAdmin中的对应的API如下:
void deleteTable(String tableName)
void deleteTable(byte[] tableName)这部分AP提供了 String与byte数组的参数,另外一点需要注意:一旦表被删除,所有的数据都会被删除。
在删除表之前,用户需要确认这张表是否已经被禁用(disabled),可通过如下方法设置该参数:
void disableTable(String tableName)
void disableTable(byte[] tableName)
void disableTableAsync(String tableName)
void disableTableAsync(byte[] tableName)用户将表设置为禁用时, region服务器会先将内存中近期内还未提交的已修改数据刷写到磁盘中,然后关闭所有的 region,并更新这张表的元数据,将所有 region标记为下线状态。
用户可选择使用异步与同步两种模式,且这两种模式均支持不同格式的表名。
用户将表设置为禁用时可能会花费非常长的时间,甚至长达几分钟。这取决于在服务器内存中有多少近期更新的数据还没有写入磁盘。将一个region下线会先将内存中的数据写入到磁盘中,如果用户设置了较大的堆,这将导致 region服务器需要向磁盘写入数MB甚至GB的数据。在负载很高的系统中进行数据写入时,多个进程间的竟争会使这个操作的执行时间变长。
一旦表被设置为禁用,但用户并不想删除它,可以通过以下方式重新启用该表。
void enableTable(String tableName)
void enableTable(byte [] tableName)
void enableTableAsync(String tableName)
void enableTableAsync(byte[] tableName)这个操作在转移这张表的 region到其他可用服务器时比较有用。此外,以下是检查表的状态的一组方法:
boolean isTableEnabled(String tableName)
boolean isTableEnabled(byte[] tableName)
boolean isTableDisabled(String tableName)
boolean isTableDisabled(byte[] tableName)
boolean isTableAvailable(byte[] tableName)
boolean isTableAvailable(String tableName)禁用、启用和检查表的状态![]()

控制台输出如下(异常打印缩写):
用户试图删除一张已经被启用的表时会抛出类似上述的异常,告诉用户首先要将该表设置为禁用状态,或者客户端根据应用的需要对异常进行处理,用户可以明确地禁用表并重试删除表操作。
isTableAvailable()方法返回了true,即使表被设置为禁用状态时,该方法同样也会返回true。换句话说,这个方法只对表进行物理检查,而不关心表本身的逻辑状态,因此要获取这张表的可用状态需要使用 isTableEnabled()和 isTableDisabled()方法。
用户建表后,如果需要修改表结构必须删除表结构然后重建表,或采用如下方法改变表结构:
void modifyTable(byte[] tableName, HTableDescriptor htd)
与前面提到的 deletable()操作类似,用户要先将表设置为禁用状态才能修改表结构。
先建表后修改表结构。
- 使用旧结构建表。
- 获取表结构,增加列族,并修改最大文件限制属性
- 禁用表,修改,然后启用表。
- 检查表结构是否已经被修改成功。
以下输出说明用户通过客户端代码修改表结构和通过服务器端查询表结构,经匹配査询到的表结构与客户端保留的表结构是一致的。
调用 HTableDescriptor对象的 equals()方法比较客户端本地的实例与从元数据获取的实例是否一致(包括所有列族以及与它们相关的设置)。
modifyTable()方法只提供了异步的操作模式,没有提供同步的操作模式。如果用户需要确认修改是否已经成功,需要在客户端代码中显式循环地调用 getTableDescriptor()方法获取元数据,直到结果与本地实例匹配。
3、模式操作
除了 modifyTable()方法, HBaseAdmin类另外提供了几种表结构修改方法。当然,首先要确保表已经被禁用。
与列相关操作的方法集合如下:
void addColumn(String tableName, HColumnDescriptor column)
void addcolumn(byte[] tableName, HColumnDescriptor column)
void deleteColumn(String tableName, String columnName)
void deleteColumn(byte[] tableName, byte[] columnName)
void modifyColumn(String tableName, ColumnDescriptor descriptor)
void modifyColumn(byte[] tableName, HColumnDescriptor descriptor)通过以上方法,用户可以创建、删除、修改列族。增加或修改一个列族需要准备个HColumnDescriptor实例。使用 getTableDescriptor()方法可以查询当前表结构,然后调用 getColumnFamilies()方法可以查询到所有已存在列族的信息。
如果用户不采用上述方法,其只能通过粗粒度地提供常用格式的表名以及列族名来调用删除操作,但是这些调用都是异步的,结果不可控,用户要自己承担这种风险。
使用场景:Hush
值得一提的是,表创建、修改都可以基于一个外部的配置文件。Hush模式恰妤利用了这个想法,其把表和列的描述定义在XML文件中,这个文件可读并包含了与当前表结构的对比。下面的示例提供了相应的核心代码。![]()



- 用 HBase表结构的元数据与XML定义文件进行对比,用户可以看到两者之间的差异
- 检查列族和表的定义是否有区别
- 修改列族信息前一定要确保表已经被禁用。
- 增加列。
- 删除列。
- 如果发现表结构不同就修改表结构。
- 如果表不存在就创建表。
4、集群管理
HBaseAdmin类提供的最后一组操作是集群管理操作。允许用户查看集群当前的状态,执行表级任务和管理 region。
以下操作都是面向高级用户的,请谨慎使用
static void checkHBaseAvailable(Configuration conf)
ClusterStatus getclusterStatus()checkHBaseAvailable()方法可以验证客户端应用是否能与给定文件配置中的远程HBase集群进行通信。如果失败,该方法会抛出异常,换句话说,该方法并返回布尔型变量,即成功了无返回值且失败了抛出异常。
getclusterStatus()方法可以通过查询 Cluster Status类的实例返回集群信息,这个对象包含了集群状态的详细信息。
void closeRegion(String regionname, String hostAndPort)
void closeRegion(byte[] regionname, String hostAndPort)以上方法可以让已经在 region服务器中上线的特定 region下线。任何可用表的所有 region都应该是在线状态,所以用户不能随意地下线某个 region。
使用这个方法时,用户需要提供准确的 regionname,这个参数需要与元数据表.META.中存储的一样,此外还需要 hostAndport参数,如果这个参数不为空,程序逻辑就不会再去META元数据表中查找 hostAnd Port的信息了。
这个命令不经过 master节点,即客户端直接与 region服务器通信并发送 region下线命令,该命令对 master节点是透明的。
void flush(String tableNameOrRegionName)
void flush(byte[] tableNameorRegionName)表中所有的更新在未刷写到磁盘之前都会先写入 region的 Memstore实例中。客户端程序可以在达到 memstore刷写上限( memstore flush size)之前显式地以同步模式调用当前方法,以达到将数据刷写到磁盘的目的该方法需要 region名或表名,且在该方法执行时会自行判断用户提供的名称与已存在的表是否匹配。如果输入的是已存在的表名,就按照表级别处理;如果不存在该表名,就按照 region名处理:如果既不是表名也不是 region名,就抛出UnknownRegionException异常。
void compact(String tableNameOrRegionName)
void compact(byte[] tableNameOrRegionName)当前方法与前面的方法类似,都需要将 region名和表名作为参数,这个方法是个异步方法,因为合并是个花费时间比较长的操作,客户端没有必要一直等待这个操作完成。调用这个方法后,这个表或者 region会加入到这个 region所在的 region服务器的一个执行队列,并会在后台完成操作,或者是在上线该表 region的所有 region服务器中执行。
void majorCompact(String tableNameOrRegionName)
void majorCompact(byte[] tableNameOrRegionName)以上方法类似于 compact()方法,也依赖于后台队列操作,不过是执行的 major合并。提供了表名后,API内部会选代这张表所有的 region,并顺序调用 region的合并操作。
void split(String tableNameOrRegionName)
void split(byte[] tableNameOrRegionName)
void split(String tableNameOrRegionName, String splitPoint)
void split(byte[] tableNameOrRegionName, byte[] splitPoint)这个方法用于拆分一个 region或拆分整张表,如果提供了表名,AP内部会迭代这张表的所有 region并调用拆分命令值得注意的一个参数是 splitpoint,如果这个参数不为空,并指定了特定的 region,那么这个 region会按照这个指定的行键来拆分。如果指定的是表名,整张表的 region在执行拆分前会进行检查,且包含这个特定的行键的 region会按照这个特定的行键进行拆分。
如果使用 splitPoint,用户首先要确保行键是合法的,即它必须在给定的region中,并且必须大于 region的起始行键,因为在一个 region的起始行键处进行 region拆分是无效的。如果提供的行键不正确,这个行键会被忽略,并且客户端没有任何反馈,但部署这个 region的 region服务器会在日志中打印如下的信息:
Split row is not inside region key range or is equal to startkey
void assign(byte[] regionName, boolean force)
void unassign(byte[] regionName, boolean force
客户端可以通过上面的方法来控制 region的上线和下线。第一个方法可以提供上线操作,上线操作会基于 master生成的上线计划自动执行,第二个方法提供了 region的下线操作force参数设置为true对上面两个方法的意义是不一样的:第一个方法 assign()会强
制在 ZooKeeper中标记这个 region为下线状态,并将这个 region转移到一个新的region服务器中。用户使用时需要注意这个 region是否已经上线。
第二个方法 unassign()意味着无论当前 region是否在线都会强制再做一次下线操作。如果 force设置为 false就不会带来任何影响。
void move(byte[] encodedRegionName, byte[] destserverName)
使用move()方法可以通过客户端控制某个 region在哪台服务器上线。用户可以使用此方法将一个 region从当前 region服务器移动到一个新的 region服务器。 destServerName参数可以设置为null,这样会获得一个随机的服务器地址,否则必须获取一个合法的服务器地址,即一个正在运行的 region服务器进程。如果这个参数有误或者这个服务器当前没有回应,这个 region会在其他服务器上线。最糟糕的情况下,这次移动 region的操作会失败,并让这个region下线。
boolean balanceSwitch(boolean b)
boolean balancer()
第一个方法可以控制 region的负载均衡算法是否开启。如果负载均衡算法已经打开, balancer()能主动运行负载均衡算法将每台 region服务器上线的 region进行均匀再分配。
void shutdown()
void stopMaster()
void stopRegionServer(String hostnamePort)
这些方法会分别进行关闭集群、关闭 master进程和关闭某台 region服务器操作。旦调用这个方法,被执行的服务器会马上进入关闭状态,即不存在延时,且是个不可逆的过程。
5、集群状态信息
调用 HBaseAdmin.getclusterStatus()可以查询 ClusterStatus实例,这个实例包含了master搜集到的整个集群信息。注意,这个类也有 setter方法,此方法允许用户修改里面的信息,但通过set方法修改的仅仅是本地副本的变量,除非用户需要修改本地副本的变量值。
Clusterstatus类的所有方法。
| 方法 | 描述 |
| int getServersSize() | 当前活着的rgon服务器的数量,此数量不包括不可用状态的 regon服务器 |
| Collection |
当前存活的 region服务器的列表,包括 region服务器的服务、IP、RPC端口、启动时间戳等 |
| int get DeadServers() | 当前处于不可用状态的 region服务器的数量,此数量不包括可用状态的 region服务器 |
| Collection |
当前处于不可用状态的 region服务器的列表,包括 region服务器的服务ip、RPC端口等 |
| double getAverageLoad() | 平均每台 region服务器上线了多少 region,该方法类似于 getRegionsCount() |
| int getRegionsCount() | 集群中 region的总数量 |
| int getRequestsCount() | 集群的请求TPs |
| String getHBaseversion() | 返回当前集群的软件编译版本 |
| byte getVersion() | 返回 ClusterStatus实例的版本号,通过序列化的方式在RPC阶段传输 |
| String getclusterId() | 返回集群的唯一标识。这个值是集群第一次启动时通过UUID生成的,存在根目录下的hbase.id中 |
| Map |
返回当前集群正在进行处理的 region的事务列表,即移动操作、上线操作和下线操作。键是编码后的 region名(由 HRegTonInfo.getEncodeName()返回),值是 Region State的实例 |
| HServerLoad getLoad(ServerName sn) | 返回给定 region服务器的当前负载状况 |
用户通过査看集群状态可以在较高层次上看到集群的整体情况。用户査看使用getservers()方法返回的 ServerName实例能够获取所有当前处于可用状态的服务器的实际信息。
| 方法 | 描述 |
| String getHostname() | 返回服务器的域名,如果域名不可用会直接返回IP地址 |
| String getHostAndPort() | 返回域名与RPC端口的合并字符串,用“:”分隔,例如, |
| long getStartcode() | 服务器启动的时间,单位是毫秒,使用 System.currentTimeMillis()进行获取 |
| String getServerName() | 获取服务器名,服务器名是 |
| int getPort() | 返回服务器端的RPC端口 |
通过提供 HServerload实例,每台 region服务器可以提供它们的负载信息。用户调用ClusterStatus实例的 getLoad()方法可以获取 HServerload实例。使用上面提到的ServerName,通过 getServers()方法可以获取并迭代访问服务器的信息,而当前提到的
HServerload不仅提供了服务器本身的信息,还提供了每台服务器管理的 region的信息。
| 方法 | 描述 |
| byte getVersion() | 返回 ServerLoad的版本号RPC序列化进程时会用到这个参数 |
| int getLoad() | 等同于 getNumberOfRegions()的返回值 |
| int getNumberofRegions() | 当前 region服务器上线的 region数量 |
| int getNumberofRequests() | 返回当前 region服务器这个周期内的TPS,周期可以通过参数hbase.regionserver.msginterval来设定。请求数会在个周期结束后清零,它会统计所有的AP请求,如get、put、Increment、delete等 |
| int getUsedHeapMB() | JVM已使用的内存,单位为MB |
| int getMaxHeapMB() | JM最大可使用内存,单位为MB |
| int getStorefiles() | 当前 region服务器的存储文件数量,即包括这个服务器管理的所有 region |
| int getStorefilesizeInMB() | 当前 region服务器的存储文件的总存储量,单位为MB |
| int getStorefileIndexSizeInMB() | 当前 region服务器的存储文件的索引大小,单位是MB |
| int getMemStoresizeInMB() | 当前 region服务器的已用写级存的大小,包括这个 region服务器上所有的 region |
| Map |
返回当前 region服务器中每个 region的负载情况,以Map的形式返回,键是 region名,值是之前讨论过的RegionLoad实例 |
| 方法 | 描述 |
| byte[] getName() | 返回 region名,以原始的二进制byte数组格式返回 |
| String getNameAsString() | 将二进制 region名转换为字符串并返回 |
| int getStores() | 当前 region的列族数量 |
| int getStorefiles() | 当前 region的存储文件数量 |
| int getStorefilesizeMB() | 当前 region的存储文件占用空间,MB为单位 |
| int getStorefileIndexSizeMB() | 当前 region的存储文件的索引信息的大小,MB为单位 |
| int getMemStoreSizeMB() | 当前 region使用的 Memstore的大小,单位是MB |
| long getRequestsCount() | 当前 region的本次统计周期内的TPs |
| long getReadRequestsCount() | 当前 region的本次统计周期内的QPS |
| long getWriteRequestsCount() | 当前 region的本次统计周期内的WPs |