spark sql 数据倾斜案例实操
项目场景:
最近数仓同学有个离线任务跑不动了,问题是总是出现MetadataFetchFailedException 的异常,最后导致任务被 kill。于是就帮忙解决一下。
原因分析:
查看了下该任务的历史执行记录(如下图),其实最近几天一直在失败,只是在重试后偶尔会成功一下
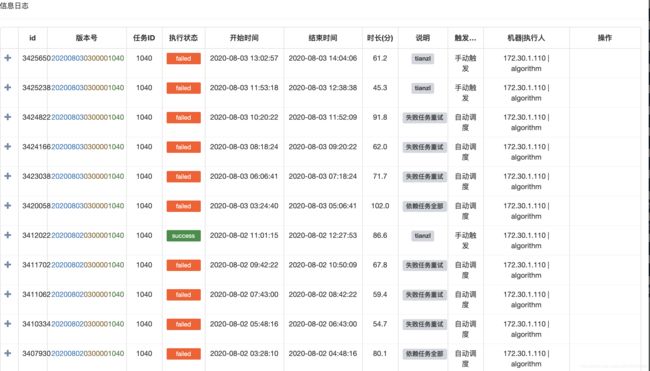
查看具体的报错日志,是shuffle 数据丢失导致的任务失败,已经询问过该同事,已经对该 spark sql 任务进行了多次调参,executor-memory 很大了任务也是同样的错误。
AY.hera.spark.conf=--master yarn --queue default --driver-memory 4g --executor-memory 20g --executor-cores 4 --num-executors 8 --conf spark.sql.broadcastTimeout=5000 --conf spark.yarn.executor.memoryOverhead=8G --conf spark.sql.shuffle.partitions=1600
大家应该知道shuffle分为 shuffle write 和 shuffle read 两个部分,其中shuffle write 会把数据 spill 到 container 的磁盘上,一般 shuffle read 的task个数都是由 spark.sql.shuffle.partitions 来控制的,该值的默认值是 200,如果该参数配置的过小,可能会导致某个task的read 的数据过大,导致 jvm crash 或者长时间处于 stw 状态,那么此时executor 就可能会导致 Failed to connect to host的异常。
这种问题的解决办法一般方式有:
- 增加
task并行度
对于spark sql任务我们可以通过加大spark.sql.shuffle.partitions的值来增加task的数量,以此来减少单个task的shuffle read数据量,但是这种方式的处理效果非常有限,比如某个key有多达上亿的数据,还是会落到同一个,在上面可以看到该任务已经配置到1600的并行度了,但是任务仍然报错。 - 减少
shuffle数据
该方案,一般是通过避免shuffle过程来彻底解决问题,比如使用broadcast join,但是该方案一般是对于大表join小表的场景使用。 - 增加
executor内存
通过增加executor-memory内存,可以解决绝大部分问题,但是在数据倾斜场景下如果某个key很大,也是属于治标不治本的操作
通过上面的 hera.spark.conf 参数我们可以看到目前该任务的 task 并行度为1600,executor-memory 为 20g。方案1 和 方案3已经尝试了,还是无法解决。
对于方案2,我们需要看下任务的 sql
WITH temp_qs_tzl_device_report_01 AS (
SELECT
pid,
dp_id
FROM
bi_ods_clear.table_log
WHERE
dt = '${yyyymmdd}'
),
temp_qs_tzl_device_report_02 AS (
SELECT
id,
NAME,
schema_id
FROM
bi_ods.table_product
WHERE
dt = '${yyyymmdd}'
),
temp_qs_tzl_device_report_03 AS (
SELECT
CODE,
property,
schema_id,
dp_id
FROM
bi_ods.table_schema
WHERE
dt = '${yyyymmdd}'
) INSERT overwrite TABLE qs_tzl_device_report PARTITION (dt = '${yyyymmdd}') SELECT
/*+ REPARTITION(400) */
a.pid AS product_id,
b. NAME AS product_name,
c. CODE AS property_code,
c.property
FROM
temp_qs_tzl_device_report_01 a
LEFT OUTER JOIN temp_qs_tzl_device_report_02 b ON a.pid = b.id
LEFT OUTER JOIN temp_qs_tzl_device_report_03 c ON (
b.schema_id = c.schema_id
AND a.dp_id = c.dp_id
);
脚本内容很简单,主要涉及到三张表的 join,为了判断 方案2 是否可行,
查看任务的执行计划可以发现 table_log 表和 table_product 已经进行了broadcast hash join,join 后的结果与 table_schema 进行 sort merge join.
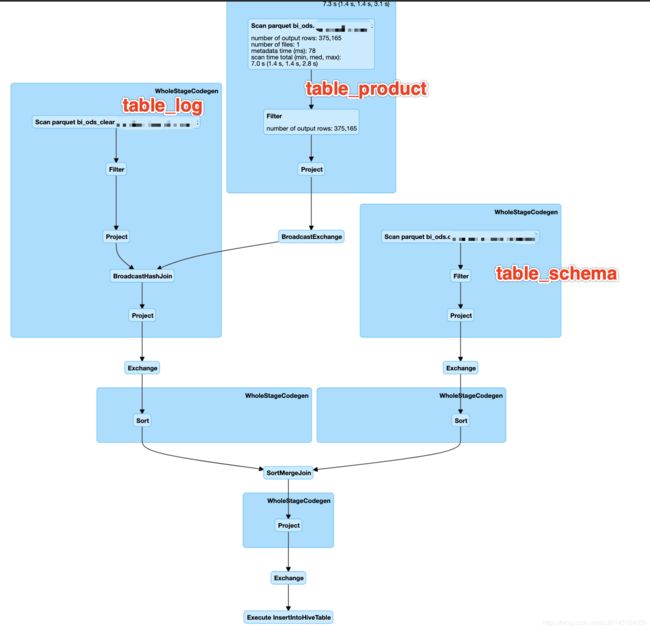
我们简单count一下三张表的数据
| 表名 | 数据量 |
|---|---|
| bi_ods_clear.table_log | 843101945 |
| bi_ods.table_product | 5097521 |
| bi_ods.table_schema | 245870981 |
发现其实 table_schema 的数据量是很大的,已经达到了2.4亿条数据,如果强制进行进行
broadcast hash join 会直接导致container oom,查看 task 的 metircs 信息发现,某个 task 的shuffle read 处理了 14.8GB/13亿条 的数据,并且最后该task 执行失败
已经很明显的可以看出数据倾斜的问题了,剩下就是然后就是判断是那张表存在数据倾斜的现象。
select count(1) cnt, b.schema_id,a.dp_id from temp_qs_tzl_device_report_01 a
left outer join temp_qs_tzl_device_report_02 b
on a.pid=b.id group by b.schema_id,a.dp_id order by cnt desc limit 100
已经测试过 table_log 和 table_log 与 table_productjoin 的结果表数据量是一致的,然后直接对这两张表的结果表进行 key 的 group by发现存在严重的数据倾斜。。排名第一的 key 多达一亿三千万数据,而第100的 count 只有 10000 多,在进行 shuffle 时会导致某个 task 的执行时间超慢,从而拖慢整个任务的进度,甚至导致 jvm crash。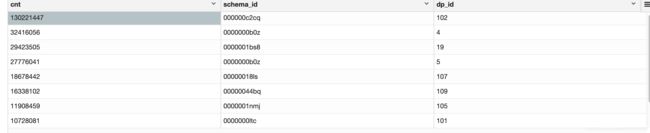
解决方案:
数据倾斜的解决方案有很多种,网上一搜一大把,这里就不在讨论。我使用的是方法是:采样倾斜 key 使用随机前缀进行 join
具体步骤是:
- 对
table_log与table_productjoin的join结果表table_join_01进行TABLESAMPLE采样,取出倾斜key表table_skew - 把
table_join_01与倾斜表table_skew进行join,join上的dp_id增加0-100的随机前缀concat(cast(rand()*100 as int),'_',a.dp_id) - 把
table_schema与倾斜表table_skew进行join,join上的每条数据explode膨胀成100条数据,这100条数据都按顺序附加一个0~100的前缀 - 此时就将原先相同的
key打散成100份,分散到多个task中去进行join了。
具体代码如下:
WITH table_log AS (
SELECT
pid,
dp_id
FROM
bi_ods_clear.table_log
WHERE
dt = '${yyyymmdd}'
),
table_product AS (
SELECT
id,
NAME,
schema_id
FROM
bi_ods.table_product
WHERE
dt = '${yyyymmdd}'
),
table_schema AS (
SELECT
CODE,
property,
schema_id,
dp_id
FROM
bi_ods.table_schema
WHERE
dt = '${yyyymmdd}'
),
table_join_01 AS (
SELECT
,
a.pid,
a.dp_id,
b. NAME,
b.schema_id
FROM
table_log a
LEFT OUTER JOIN table_product b ON a.pid = b.id
),
-- sample取样取出数量排名前100的倾斜key
table_skew AS (
SELECT
count(1) cnt,
schema_id,
dp_id
FROM
table_join_01 TABLESAMPLE (10 PERCENT) a
GROUP BY
schema_id,
dp_id
ORDER BY
cnt DESC
LIMIT 100
),
-- 驱动表倾斜key join对驱动表增加随机前缀
rebuild_table_01 AS (
SELECT
pid,
NAME,
a.schema_id,
CASE
WHEN b.cnt IS NOT NULL THEN
concat(
cast(rand() * 100 AS INT),
'_',
a.dp_id
)
ELSE
a.dp_id
END dp_id
FROM
table_join_01 a
LEFT JOIN table_skew b ON a.dp_id = b.dp_id
AND a.schema_id = b.schema_id
),
-- 被驱动表倾斜key join
table_join_02 AS (
SELECT
a.schema_id,
a.dp_id,
b.cnt cnt
FROM
table_schema a
LEFT JOIN table_skew b ON a.dp_id = b.dp_id
AND a.schema_id = b.schema_id
),
-- 被驱动表膨胀100倍
rebuild_table_02 AS (
SELECT
CODE,
property,
schema_id,
dp_id
FROM
table_join_02
WHERE
cnt IS NULL
UNION ALL
SELECT
CODE,
property,
schema_id,
concat(b.prefix, '_', dp_id) prefix
FROM
table_join_02 lateral VIEW OUTER explode (
split (
'0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100',
','
)
) b AS prefix
WHERE
cnt IS NOT NULL
)
INSERT overwrite TABLE qs_tzl_device_report_test PARTITION (dt = '${yyyymmdd}') SELECT
/*+ REPARTITION(100) */
a.pid AS product_id,
a. NAME AS product_name,
c. CODE AS property_code,
c.property
FROM
rebuild_table_01 a
LEFT OUTER JOIN rebuild_table_02 c ON (
a.schema_id = c.schema_id
AND a.dp_id = c.dp_id
)
修改任务后执行发现任务的执行时间为 15 分钟附近,而在之前需要执行接近 90 分钟

并且使用的yarn资源也减少为之前的 1/2