【论文学习】Bringing Old Photos Back to Life
【fishing-pan:https://blog.csdn.net/u013921430 转载请注明出处】
前言
最近在浏览CVPR2020年的文章,1000多篇真的看不完,简单的浏览了几篇都觉得缺点意思。起初主要是被这篇文章的标题吸引的,因为最近老照片修复真的很火,看了这篇文章后,觉得这个工作确实是挺好的,所以把自己对文章的理解写出来,与大家交流。

论文地址:https://arxiv.org/abs/2004.09484
工作背景
老照片修复中面临着许多的图像处理问题,比如填孔洞、去划痕、上色、去噪等,也就是说包含了多种图像退化问题。而使用深度学习进行训练时往往需要制造样本对,但是真实的低质量数据包含多种退化问题,想要通过正常图像模拟出完全符合数据分布的低质量图像几乎是不可能的。(同样的问题在Deblur、SR、Denoise等Low level问题中也有遇到)
为了回避样本制造的问题,作者将老照片修复模拟成三域转换的问题,三个域分别是真实的老照片的域 R R R、合成的低质照片的域 X X X、真实的高质照片(GT)的域 Y Y Y。整体的思路如下面这张图所示。

简单地介绍上面图中的表达的意思就是,从域 X X X 可以转换到低维的 latent space Z x Z_{x} Zx,同样地,从域 R R R 可以转换到低维的 latent space Z r Z_{r} Zr。虽然合成的退化图像 x x x 与真实图像 z z z 在退化方式等方面存在差异,但都是损坏了的图像,有许多相似表现。因此,通过一些约束可以尽量让 Z r Z_{r} Zr 与 Z x Z_{x} Zx 分布尽量重合,也就是上图中的虚线的部分。由于 x x x 是由 y y y 合成,两者之间存在联系,可以将 z x z_{x} zx 转换到 z y z_{y} zy ,再由 z y z_{y} zy 恢复出 y y y 。这样就形成了一个弱监督,通过拉近 Z r Z_{r} Zr 与 Z x Z_{x} Zx ,然后借助从 z x z_{x} zx 到 y y y 的途径来恢复出高质量的 Z Z Z 。这就是文章三域转换的主要思想。
核心工作
本文的模型主要由三个部分组成两个变分自编码器(variational autoencoder,VAE)和一个latent space 映射网络 τ \tau τ,每个部分都可以看作是单独的一个模块。下面将介绍网络设计的思想和不同部分的作用。

V A E 1 VAE_{1} VAE1 与 V A E 2 VAE_{2} VAE2
首先是最上方的 V A E 1 VAE_{1} VAE1 ,由编码器 E R , X E_{R,X} ER,X 与生成器 G R , X G_{R,X} GR,X 组成,它将图像 r r r 与 x x x 分别编码到 Z r Z_{r} Zr 与 Z x Z_{x} Zx ,然后再重新恢复;并且使潜在编码符合都高斯分布(以及使用重参数化技巧使模型可以进行训练,都是VAE方法中的技巧)。当输入为 r r r 时,它的目标函数表达式如下;
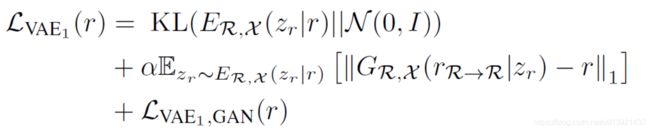
第一项使用是 V A E VAE VAE 训练时使用到的约束项,用KL散度约束潜在编码的分布接近高斯分布,其中 E R , X ( z r ∣ r ) E_{R,X}(z_{r}|r) ER,X(zr∣r) 表示输入为 r r r 时通过 E R , X E_{R,X} ER,X 得到的 z r z_{r} zr 服从的先验概率分布。第二项表示通过 V A E VAE VAE 编码恢复结果与输入数据 r r r 之间的 l 1 l1 l1 loss,这一项是latent code有了明确的含义。第三项是一个LSGAN loss,众所周知, V A E VAE VAE 生成的结果往往过于平滑,而GAN的生成结果的高频细节更加丰富,所以作者在这里引入一个GAN loss。输入为 x x x 时也使用同样的 loss 进行训练, V A E 2 VAE_{2} VAE2 用于训练 y y y ,也使用同样的 loss 进行约束。
因为 r r r 与 x x x 共用一个 V A E VAE VAE ,这使得两者的latnet space 非常靠近,为了更进一步拉近 Z r Z_{r} Zr 与 Z x Z_{x} Zx ,作者又使用了一个判别器,与之前的GAN loss不同,这个判别器用来区分两个潜在编码。
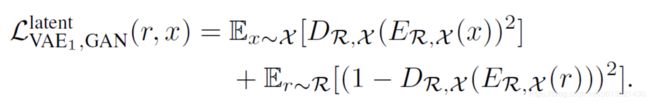
理论上,这个GAN loss的存在会使 Z r Z_{r} Zr 与 Z x Z_{x} Zx 的分布更加一致,那么 V A E 1 VAE_{1} VAE1 总的loss就是如下形式;
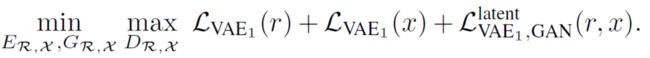
映射网络 τ \tau τ
简单地来说, τ \tau τ 的作用是将 z x z_{x} zx 映射到 z y z_{y} zy ,这样做有两个优势。第一,由于 X X X 与 R R R 在潜在编码空间对齐,所以借助从 z x z_{x} zx 恢复得到 y y y 的途径也能恢复出一个好的 r r r ;第二,在低维的latent space 进行转换要比在复杂的图像域转换更加简单。训练 τ \tau τ 的 loss 如下;
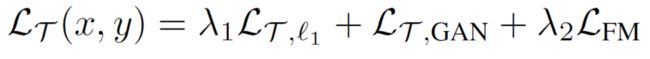
第一项是 l 1 l1 l1 loss, L τ ( x , y ) = E ∥ τ ( z x ) − z y ∥ 1 L_{\tau}(x,y)=E\left \| \tau(z_{x})-z_{y} \right \|_{1} Lτ(x,y)=E∥τ(zx)−zy∥1 ,第二项是 LSGAN ,作用于 z x ↦ y z_{x} \mapsto y zx↦y,使通过 z x z_{x} zx 生成的图像与GT看上去更真实,第三项也是常见的使用VGG 网络求取的感知loss。
通过上面的介绍三个网络的作用和训练方法已经很清晰了。下面将进一步分析网络的设计 。
多重退化修复
在 τ \tau τ 中,主要是用的是残差模块,由于感受野的限制,网络主要关注局部的特征。然而一些老照片中一些结构的损坏需要更大范围内的信息进行搜索填充,因此需要让设计的网络即支持获取局部的信息,又支持获取全局的信息。因此,作者添加了一个含有非局部模块的全局信息提取的分支。这里采用一个mask作为输入,来防止图片中损坏区域的像素不会被用于修复损坏区域。(本文中使用合成的数据集来训练一个 Unet 网络以检测mask)
对于一个HWC维度的特征F,m 表示同样大小的单通道二值mask图像,m中值为1时表示表示损坏区域,值为0表示正常区域。那么对于F中位置 i i i 与位置 j j j 之间的关系可以表示为 s i , j s_{i,j} si,j , s i , j ∈ R H W × H W s_{i,j}\in R^{HW\times HW} si,j∈RHW×HW ,是每个pixel 之间的关系。公式如下;
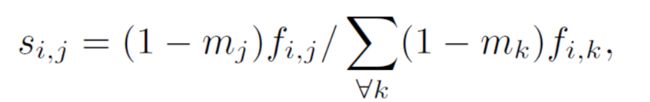
从公式中可以看出, s i , j s_{i,j} si,j 表示像素 j j j 对于像素 i i i 相关性的归一化表示,也可以看作是像素点 j j j 贡献的权重值,当像素点在m中标记为腐坏点时,贡献值为0;其中 f i , j f_{i,j} fi,j 的式子如下;

上面的式子中 F i F_{i} Fi、 F j F_{j} Fj 是一个维度为 C*1 的向量; θ \theta θ 与 Φ \Phi Φ 是将向量映射到高斯分布的函数,所以最终 f i , j f_{i,j} fi,j 是一个标量。最终,部分非局部的输出为;
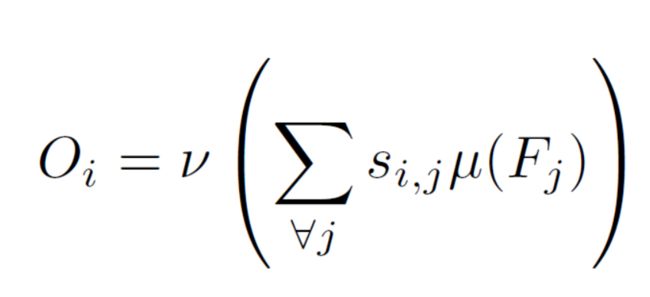
不难看出, s i , j s_{i,j} si,j 就是权重值。而这里的 v v v 和 u u u 用于进一步整合特征。 v v v 、 u u u 、 v v v 、 Φ \Phi Φ 都是1x1卷积。
通过这样的上述的模块,就可以起到全局感受野的作用。但是只希望对被腐坏的区域进行上述操作,其他区域不需要这样的操作,因此作者又做了个区域融合,即当mask中对应的区域被标记为损坏区域时使用global的信息,否则使用局部特征信息。

公式中的圆点表示矩阵的哈达玛积,即Elementwise product,至此所有的模型设计就讲完了。
结果展示
文中主要与pix2pix、CycleGAN进行对比;自然,从结果来看本文最好。其他的对比和消融实验就不一一细说了。
总结分析
这篇文章是一篇弱监督的文章,思路很清晰易懂,也很明确,是一份很好的工作,有很多地方值得借鉴。然后我想说一下自己觉得需要改进的地方,当然不是说这个工作的缺陷,因为有很多问题是目前没有很好地解决方案的。
- 耗时;先不说三个网络单独训练的耗时,光是Prediction来看就比较耗时,虽说作者没有给出时间对比,但是也说了pix2pix和自己的工作的耗时最少,可以说明一点,本文的网络应该比pix2pix耗时。
- 弱监督的任务往往很难在高分辨的图像上使用。
- mask的问题,如果要将模型实际应用,如何获取mask也是一个问题,本文中使用特殊训练的Unet结构来预测mask,无疑又加大了计算量。
总的来说这篇文章还是非常好的,值得学习。上面是我自己读了论文后的理解,可能有不足或是错误的地方,欢迎大家一起讨论。