1. PEP8 编码规范, 及开发中的一些惯例和建议
-
练习: 规范化这段代码
from django.conf import settings from user.models import * import sys, os mod=0xffffffff def foo ( a , b = 123 ): c={ 'x' : 111 , 'y' : 222 }#定义一个字典 d=[ 1 , 3,5 ] return a,b , c def bar(x): if x%2==0 : return True -
为什么要有编码规范
- 编码是给人看的还是给机器看的?
当然是给人看的。 - 美观是重点吗?
- 美观,因人而异。
- 可读性
- 可维护性
- 健壮性
- 团队内最好的代码状态: 所有人写出的代码像一个人写出来的
- 编码是给人看的还是给机器看的?
-
代码编排:
- 缩进 4 个空格, 禁止空格与 Tab 混用
- 行长 80 字符: 防止单行逻辑过于复杂
-
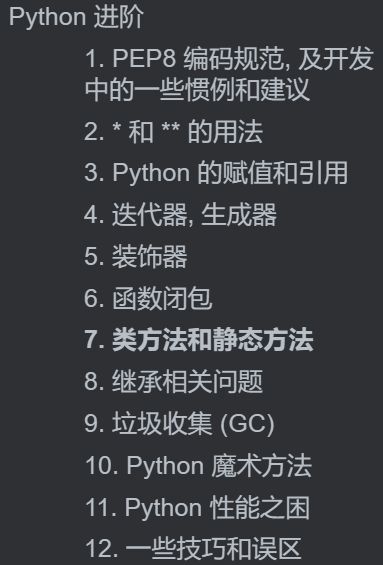
import
- 不要使用
from xxx import *避免标准库中的名字冲突
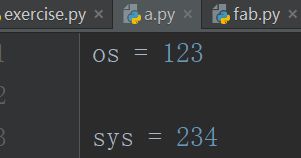 image.png
image.png
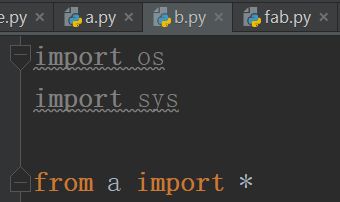 image.png
image.png - 顺序
- 标准库
- 第三方库
- 自定义库
- 单行不要 import 多个库
-
模块内用不到的不要去 import
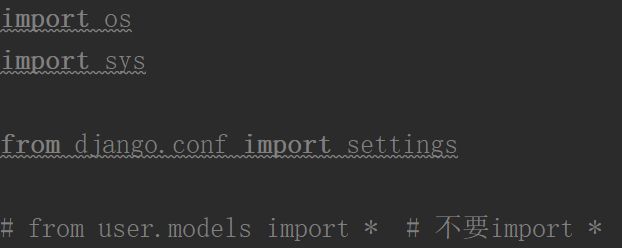 image.png
image.png
- 不要使用
-
空格
-
: ,后面跟一个空格, 前面无空格 (行尾分号后无空格) - 二元操作符前后各一个空格, 包括以下几类:
- 数学运算符:
+ - * / // = & | - 比较运算符:
== != > < >= <= is not in - 逻辑运算符:
and or not - 位运算符:
& | ^ << >>
- 数学运算符:
- 当
=用于指示关键字参数或默认参数值时, 不要在其两侧使用空格
-
-
适当添加空行
- 函数间: 顶级函数间空 2 行, 类的方法之间空 1 行
- 函数内: 同一函数内的逻辑块之间, 空 1 行
- 文件结尾: 留一个空行 (Unix 中 \n 是文件的结束符)
-
注释
- 忌: 逐行添加注释, 没有一个注释
- 行尾注释: 单行逻辑过于复杂时添加
- 块注释: 一段逻辑开始时添加
- 引入外来算法或者配置时须在注释中添加源连接, 标明出处
- 函数、类、模块尽可能添加
docstring
-
命名
- 好的变量名要能做到“词能达意”
- 除非在 lambda 函数中, 否则不要用 单字母 的变量名 (即使是 lambda 函数中的变量名也应该尽可能的有意义)
- 包名、模块名、函数名、方法、普通变量名全部使用小写, 单词间用下划线连接
- 类名、异常名使用 CapWords (首字母大写) 的方式, 异常名结尾加
Error或Wraning后缀 - 全局变量尽量使用大写, 一组同类型的全局变量要加上统一前缀, 单词用下划线连接
- 函数名必须有动词, 最好是 do_something 的句式, 或者 somebody_do_something 句式
-
语意明确、直白
-
not xx in yyVSxx not in yy -
not a is bVSa is not b
-
-
程序的构建
- 函数是模块化思想的体现
- 独立的逻辑应该抽离成独立函数,让代码结构更清晰,可复用度更高
- 一个函数只做一件事情, 并把这件事做好
- 大的功能用小函数之间灵活组合来完成
- 避免编写庞大的程序, “大” 意味着体积庞大, 逻辑复杂甚至混乱
自定义的变量名、函数名不要与标准库中的名字冲突
-
pip install pycodestyle pylint flake8 autopep8 #语句以分号结束
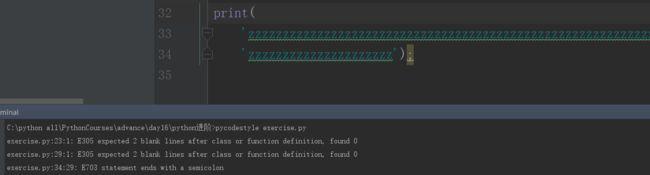 image.png
image.png
2. * 和 ** 的用法
-
函数定义时接收不定长参数
def foo(*args, **kwargs): pass 参数传递
def foo(x, y, z, a, b):
print(x)
print(y)
print(z)
print(a)
print(b)
lst = [1, 2, 3]
dic = {'a': 22, 'b': 77}
foo(*lst, **dic)
1
2
3
22
77
-
import * 语法
-
文件 xyz.py
__all__ = ('a', 'e', '_d') a = 123 _b = 456 c = 'asdfghjkl' _d = [1,2,3,4,5,6] e = (9,8,7,6,5,4) -
文件 abc.py
from xyz import * print(a) print(_b) print(c) print(_d) print(e) #此时报错,因为使用了__all__方法,只允许调用a, e, _d变量
-
3. Python 的赋值和引用
-
==, is:==判断的是值,is判断的是内存地址 (即对象的id) - 小整数对象: [-5, 256]
-
copy, deepcopy的区别-
copy: 只拷贝表层元素 -
deepcopy: 在内存中重新创建所有子元素
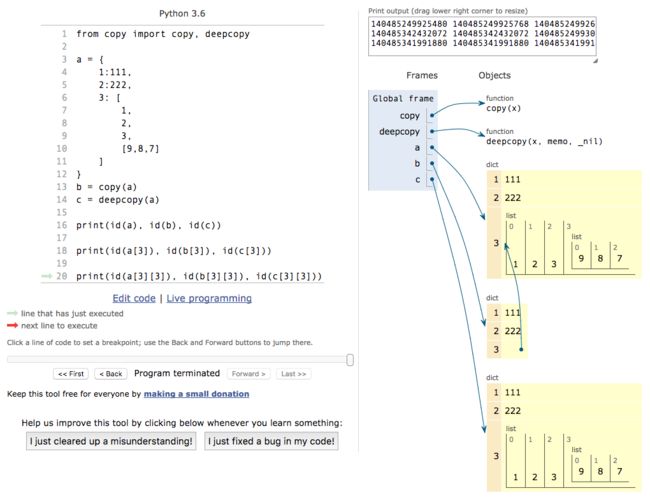 copy.png
copy.png
-
-
练习1: 说出执行结果
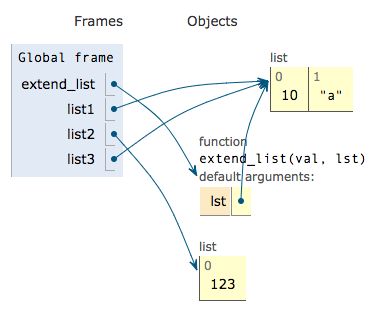 default_list.png
default_list.png
```python
def extendList(val, lst=[]):
lst.append(val)
return lst
list1 = extendList(10)
list2 = extendList(123, [])
list3 = extendList('a')
```
- 练习2: 说出下面执行结果
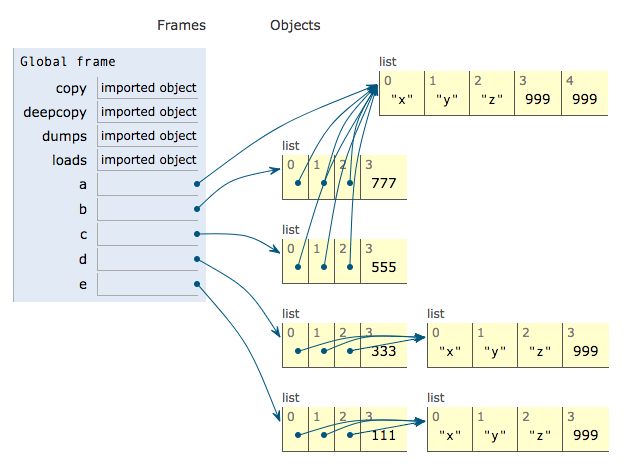
```python
from copy import copy, deepcopy
from pickle import dumps, loads
a = ['x', 'y', 'z']
b = [a] * 3
c = copy(b)
d = deepcopy(b)
e = loads(dumps(b, 4))
b[1].append(999)
b.append(777)
c[1].append(999)
c.append(555)
d[1].append(999)
d.append(333)
e[1].append(999)
e.append(111)
```
- 自定义 deepcopy:
my_deepcopy = lambda item: loads(dumps(item, 4))
4. 迭代器, 生成器
- 练习: 说出如下代码的打印结果
不带参
>>> def foo():
... print(111)
... yield 222
... print(333)
... yield 444
... print(555)
>>> n = foo()
>>> next(n)
>>> next(n)
>>> next(n)
111
222
333
444
#抛出异常
StopIteration
带参
def foo():
print(111)
r = yield 222
print(r, 333)
r = yield 444
print(r, 555)
n = foo()
n.send(None)
n.send('a')
n.send('b')
111
a 333
#抛出异常
StopIteration
- generator: 生成器是一种特殊的迭代器, 不需要自定义
__iter__和__next__- 生成器函数 (yield)
- 生成器表达式
a = (i for i in range(5))
print(type(a)) #
自定义一个range
class Range:
def __init__(self, start, end=None, step=1):
if end is None:
self.end = start
self.start = 0
else:
self.start = start
self.end = end
self.step = step
def __iter__(self):
return self
def __next__(self):
if self.start < self.end:
current = self.start
self.start += self.step
return current
else:
raise StopIteration()
-
iterator迭代器: 任何实现了
__iter__和__next__方法的对象都是迭代器.-
__iter__得到一个迭代器。迭代器的__iter__()返回自身 -
__next__返回迭代器下一个值 - 如果容器中没有更多元素, 则抛出 StopIteration 异常
- Python2中没有
__next__(), 而是next()
-
str / bytes / list / tuple / dict / set自身不是迭代器,他们自身不具备__next__(), 但是具有__iter__(),__iter__()方法用来把自身转换成一个迭代器-
练习1: 定义一个随机数迭代器, 随机范围为 [1, 50], 最大迭代次数 30
import random class RandomIter: def __init__(self, start, end, times): self.start = start self.end = end self.count = times def __iter__(self): return self def __next__(self): self.count -= 1 if self.count >= 0: return random.randint(self.start, self.end) else: raise StopIteration() -
练习2: 自定义一个迭代器, 实现斐波那契数列
class Fib: def __init__(self, max_value): self.prev = 0 self.curr = 1 self.max_value = max_value def __iter__(self): return self def __next__(self): if self.curr < self.max_value: res = self.curr self.prev, self.curr = self.curr, self.prev + self.curr # 为下一次做准备 return res else: raise StopIteration()
class Fab:
def __init__(self, times):
self.prev = 0
self.curr = 1
self.times = times
self.count = 0
def __iter__(self):
return self
def __next__(self):
# 需要一个退出条件
if self.count < self.times:
current = self.curr
self.prev, self.curr = self.curr, self.prev + self.curr
self.count += 1
return current
else:
raise StopIteration
for i in Fib(5):
print(i)
1
1
2
3
5
8
-
练习3: 自定义一个生成器函数, 实现斐波那契数列
def fib(max_value): prev = 0 curr = 1 while curr < max_value: yield curr prev, curr = curr, curr + prev
def bar(n):
# prev = previous
prev = 0
# current
curr = 1
# 计数
count = 0
while count <= n:
yield curr
prev, curr = curr, prev + curr
count += 1
-
迭代器、生成器有什么好处?
- 节省内存
- 惰性求值 (惰性求值思想来自于 Lisp 语言)
-
各种推导式
- 分三部分:生成值的表达式, 循环主体, 过滤条件表达式
- 列表:
[i * 3 for i in range(5) if i % 2 == 0] - 字典:
{i: i + 3 for i in range(5)} - 集合:
{i for i in range(5)} - 生成器表达式:(i for i in range(5))
s = 'abcd'
#{'a': [1,1,1,1], 'b': [2,2,2,2], ...}
one = {key: value*4 for key, value in zip(s, [[1], [2], [3], [4]])}
two = {value: [1+index]*4 for index, value in enumerate(s)}
print(one,two)
{'a': [1, 1, 1, 1], 'b': [2, 2, 2, 2], 'c': [3, 3, 3, 3], 'd': [4, 4, 4, 4]}
{'a': [1, 1, 1, 1], 'b': [2, 2, 2, 2], 'c': [3, 3, 3, 3], 'd': [4, 4, 4, 4]}
5. 装饰器
判断是不是装饰器:函数进,函数出
类装饰器和普通装饰器区别不大,类装饰器未带参的通过init方法接收函授,通过call接收函数的参数,带参数反之。
装饰器体现了什么编程思想?
AOP aspect oriented programming
面向切片编程,不会影响原函数,会额外添加功能。类似中间件
- 使用场景
- 参数、结果检查
- 缓存、计数
- 日志、统计
- 权限管理
- 重试
- 其他
- 最简装饰器
def deco(func): # 传入func为函数进 def wrap(*args, **kwargs): return func(*args, **kwargs) return wrap # 返回函数为函数出 @deco def foo(a, b): return a ** b
装饰器原理
import random
from functools import wraps
'''
原函数为foo
(1)中
@deco
def wrap(*args, **kwargs):
为什么可以这样调用,装饰器语法上已赋值给原始函数名
# 等同于走了(2)中
wrap = deco(foo)
bar = wrap
赋值给bar,实际调用wrap。
原函数调用装饰器以后__name__,__doc__发生变化,这样不友好,
未使用@wraps(func)
0
1
True
True
需用@wraps(func)还原被装饰器修改的原函数属性
0
5
False
False
'''
def deco(func):
'''
deco
'''
@wraps(func) # 还原被装饰器修改的原函数属性
def wrap(*args, **kwargs):
'''
wrap
'''
res = func(*args, **kwargs)
if res < 0:
return 0
else:
return res
return wrap
# (1)
@deco
def foo(m, n):
'''
foo
'''
return random.randint(m, n)
# 调用
print(foo(-5, 5))
# (2)
def bar(m, n):
'''
bar
'''
return random.randint(m, n)
wrap = deco(bar)
bar = wrap
print(wrap(-5, 5))
print(bar.__name__ is foo.__name__)
print(bar.__doc__ is foo.__doc__)
0
5
False
False
* 多个装饰器叠加调用的过程
```python
@deco1
@deco2
@deco3
def foo(x, y):
return x ** y
# 过程拆解 1
fn3 = deco3(foo)
fn2 = deco2(fn3)
fn1 = deco1(fn2)
foo = fn1
foo(3, 4)
# 过程拆解 2
# 单行: deco1( deco2( deco3(foo) ) )(3, 2)
deco1(
deco2(
deco3(foo)
)
)(3, 4)
```
打比喻
def deco1(func):
def wrap1(*args, **kwargs):
print('enter wrap1(%s, %s)' % (args))
func(*args, **kwargs)
print('exit wrap1..')
return wrap1
def deco2(func):
def wrap2(*args, **kwargs):
print('enter wrap2(%s, %s)' % (args))
func(*args, **kwargs)
print('exit wrap2..')
return wrap2
def deco3(func):
def wrap3(*args, **kwargs):
print('enter wrap3(%s, %s)' % (args))
func(*args, **kwargs)
print('exit wrap3..')
return wrap3
@deco1
@deco2
@deco3
def foobar(x, y):
print(x, y)
return x ** y
foobar(1, 2)
#结果
enter wrap1(1, 2)
enter wrap2(1, 2)
enter wrap3(1, 2)
1 2
exit wrap3
exit wrap2
exit wrap1
用装饰器由内到外执行
等于以下不用装饰器的执行过程,都是wrap1
@deco1
@deco2
@deco3
def foobar(x, y):
print(x, y)
return x ** y
# 不用装饰器
def foobar2(x, y):
return x ** y
wrap3 = deco3(foobar2)
wrap2 = deco2(wrap3)
wrap1 = deco1(wrap2)
foobar2 = wrap1
print(foobar2.__name__)
print(foobar.__name__)
wrap1
wrap1
类似于flask
从里往外执行
@route('/')
@login_required # 登陆才能改
@permission_required # 加权限
def index(xxx):
return 'hello world'
- 带参数的装饰器
def deco(n):
def wrap1(func):
def wrap2(*args, **kwargs):
return func(*args, **kwargs)
return wrap2
return wrap1
# 调用过程
wrap1 = deco(n)
wrap2 = wrap1(foo)
foo = wrap2
foo()
# 单行形式
check_result(30)(foo)(4, 8)
import time
# 带参数的装饰器
def times(count):
def calc_time(func):
def wrap(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print('时间%s,次数%d' % (end - start, count))
return res
return wrap
return calc_time
@times(10000)
def foo(x, y):
return x**y
foo(1000, 1000000)
时间1.159147024154663,次数10000
类似于flask传url
@route('/')
def index(xxx):
return 'hello world'
另一种带参
def control_time(n, name):
def sleep_time(func):
def wrap(*args, **kwargs):
print('只能玩%s%d分钟' % (name, n))
res = func(*args, *kwargs)
time.sleep(n)
return res
return wrap
return sleep_time
@control_time(3, '王者荣耀')
def play():
pass
play()
只能玩王者荣耀3分钟
- 装饰器类和
__call__
以上代码拆分延申至以下问题
python中有一个函数,判断能不能被调用callable()
a不能被调用, A能调用,因为A类隐含object,从object里面引用的
class A:
pass
a = A()
print(callable(a))
print(callable(A))
True
False
f = foobar(1, 2)
print(callable(foobar))
print(callable(f))
True
False
实现call方法后b可调用
class B:
def __call__(self, x, y):
return x**y
b = B()
print(callable(b))
print(b(2, 2))
True
4
通过call方法实现类装饰
class Deco:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
return self.func(*args, **kwargs)
@Deco
def foo(x, y):
return x ** y
# 过程拆解
fn = Deco(foo)
foo = fn
foo(12, 34)
定义一个未带参数的类装饰器,功能:随机正整数
import random
import time
class Deco:
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
res = self.func(*args, **kwargs)
if res < 0:
return 0
else:
return res
@Deco
def foo(x, y):
return random.randint(x, y)
print(foo(-5, 20))
# 不用装饰器
def toobar(x, y):
return random.randint(x, y)
toobar = Deco(toobar)
print(toobar(-5, 20))
#结果
0
6
带参数的类装饰器
class Control_time:
def __init__(self, name, minutes):
self.name = name
self.minutes = minutes
def __call__(self, func):
def wrapper(*args, **kwargs):
print('开始玩%s游戏,只能玩%d分钟' % (self.name, self.minutes))
res = func(*args, **kwargs)
time.sleep(self.minutes)
print('时间到')
return res
return wrapper
@Control_time('War3', 1)
def play():
print('a')
play()
开始玩War3游戏,只能玩1分钟
a
时间到
- 练习1: 写一个 timer 装饰器, 计算出被装饰函数调用一次花多长时间, 并把时间打印出来
import time
from functools import wraps
def timer(func):
@wraps(func)
def wrap(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs)
end = time.time()
print('耗时:%s' % (end - start))
return res
return wrap
@timer
def foo(x, y):
return x ** y
foo(10, 1000000)
耗时:0.19840478897094727
- 练习2: 写一个 Retry 装饰器
作为装饰器类名变为小写
import time
class retry(object):
def __init__(self, max_retries=3, wait=0, exceptions=(Exception,)):
self.max_retries = max_retries
self.exceptions = exceptions
self.wait = wait
def __call__(self, func):
def wrapper(*args, **kwargs):
for i in range(self.max_retries + 1):
try: # 如果try,没有发生异常,则执行else。发生异常则执行except,然后continue重新执行for循环
result = func(*args, **kwargs)
except self.exceptions:
time.sleep(self.wait)
print('retry %d' % i)
continue
else:
return result
return wrapper
@retry(3, 1, (ValueError,)) # (尝试次数,等待时间,异常)
def foo(x, y):
res = random.randint(x, y)
if res < 0:
raise ValueError
else:
return res
print(foo(-10, 5))
#结果
retry 0
retry 1
retry 2
retry 3
None
#重新执行的结果
retry 0
retry 1
3
6. 函数闭包
Function Closure: 引用了自由变量的函数即是一个闭包. 这个被引用的自由变量和这个函数一同存在, 即使已经离开了创造它的环境也不例外.
-函数闭包3条件
1.必须有函数的嵌套
2.内部函数引用了外部函数的变量
3.外部函数调用内部函数-
说出下面函数返回值
def foo(): l = [] def bar(i): l.append(i) return l return bar f1 = foo() f2 = foo() # 说出下列语句执行结果 f1(1) f1(2) f2(3) [1] [1, 2] [3] 深入一点:
object.__closure__
print(f1.__closure__) # 返回元组
# (,)
cell = f1.__closure__[0] # 里面只有一个,取第一个
print(cell) # |
print(cell.cell_contents) # 存放闭包的自由变量的值 # [1, 2]
| | -
作用域
┌───────────────────────────┐ │ built-in namespace │ ├───────────────────────────┤ ↑ │ global namespace │ │ ┌───────────────────────┤ │ │ local namespace │ n = 123 │ │ ┌───────────────────┤ │ │ │ local namespace │ ↑ │ │ │ ┌───────────────┤ │ │ │ │ ... │ print(n) └───┴───┴───┴───────────────┘- 声明全局变量:
global - 声明非本层的 局部变量 :
nonlocal - 查看全局变量:
globals() - 查看局部变量:
locals() - 查看变量:
vars([object]) # 不传参数相当于 locals(), 传入对象后, 会得到 object.__dict__
- 声明全局变量:
n = 100
m = 200
def deco(func):
m = 300
def wrap():
global n # 声明全局变量
nonlocal m # 声明局部变量
n = n + 1
m = m + 2
print(n)
print(m)
print('局部变量', locals()) # 查找局部变量
return func()
return wrap
@deco
def foo():
global m
m = m +3
print(m)
return print('全局变量', globals()) # 查找全局变量
foo()
# 结果
101
302
局部变量 {'m': 302, 'func': }
203
全局变量 {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000016BF5A7B160>, '__spec__': None, '__annotations__': {}, '__builtins__': , '__file__': 'C:/python all/PythonCourses/advance/day16/python进阶/global_7.py', '__cached__': None, 'n': 101, 'm': 203, 'deco': , 'foo': .wrap at 0x0000016BF5CCAB70>}
class A:
def __init__(self, x, y):
self.x = x
self.y = y
print(vars())
print(locals())
print(vars(A))
print(A.__dict__)
# 调用
print(vars(A(1, 2)))
# 结果
{'y': 2, 'x': 1, 'self': <__main__.A object at 0x000002AC9DECB240>}
{'y': 2, 'x': 1, 'self': <__main__.A object at 0x000002AC9DECB240>}
{'__module__': '__main__', '__init__': , '__dict__': , '__weakref__': , '__doc__': None}
{'__module__': '__main__', '__init__': , '__dict__': , '__weakref__': , '__doc__': None}
{'x': 1, 'y': 2}
7. 类方法和静态方法
区别
普通方法需传self
类需传cls
静态方法什么都不传
-
method- 通过实例调用
- 可以引用类内部的任何属性和方法
-
classmethod- 无需实例化
- 可以调用类属性和类方法
- 无法取到普通的成员属性和方法
-
staticmethod- 无需实例化
- 无法取到类内部的任何属性和方法, 完全独立的一个方法
练习: 说出下面代码的运行结果
class Test(object):
# 类属性
x = 123
def __init__(self):
self.y = 456 # 实例方法
def bar1(self):
print('i am a method')
@classmethod
def bar2(cls): # 类方法
print('i am a classmethod')
@staticmethod # 静态方法
def bar3():
print('i am a staticmethod')
def foo1(self): # 普通方法
print(self.x)
print(self.y)
self.bar1()
self.bar2()
self.bar3()
@classmethod
def foo2(cls):
print(cls.x)
# print(cls.y) # 类方法不能调用普通方法的属性
# cls.bar1() # 类方法不能调用普通方法
cls.bar2()
cls.bar3()
@staticmethod
def foo3(obj):
print(obj.x)
print(obj.y)
obj.bar1()
obj.bar2()
obj.bar3()
t = Test()
# print(t.foo1())
# print(t.foo2()) # 类方法可以调用类和静态
print(t.foo3())
#结果
TypeError: foo3() missing 1 required positional argument: 'obj'
8. 继承相关问题
- 什么是多态
多态指的是一类事物有多种形态,(一个抽象类有多个子类,因而多态的概念依赖于继承)
class Animal(object):
def run(self):
print("Animal running")
class Tiger(Animal):
def run(self):
print('Tiger running')
class Lion(Animal):
def run(self):
print('Lion running')
class LionTiger(Tiger, Lion):
def run(self):
print('LionTiger Animal')
pass
t = Tiger()
print(isinstance(t, Animal)) # True
l = Lion()
print(isinstance(l, Animal)) # True
lt = LionTiger()
print(isinstance(lt, Animal)) # True
print(isinstance(lt, Tiger)) # True
print(isinstance(lt, Lion)) # True
print(LionTiger.mro()) # 继承链 顺序会从前往后执行
[, , , , ]
-
多继承
- 方法和属性的继承顺序:
Cls.mro()由内到外 - 菱形继承问题
继承关系示意 菱形继承 A.foo() / \ B C.foo() \ / D.mro() # 方法的继承顺序,由 C3 算法得到
- 方法和属性的继承顺序:
Mixin: 通过单纯的 mixin 类完成功能组合
super
如果A.init(self)这样调用会出现调用两次父类A,使用super优化。
class A:
def __init__(self):
print('enter A')
self.x = 111
print('exit A')
class B(A):
def __init__(self):
print('enter B')
self.y = 222
# A.__init__(self)
super().__init__()
print('exit B')
class C(A):
def __init__(self):
print('enter C')
self.z = 333
# A.__init__(self)
super().__init__()
print('exit C')
class D(B, C):
def __init__(self):
print('enter D')
# B.__init__(self)
# C.__init__(self)
super().__init__()
print('exit D')
d = D()
print(D.mro())
enter D
enter B
enter C
enter A
exit A
exit C
exit B
exit D
[, , , , ]
9. 垃圾收集 (GC)
- Garbage Collection (GC)
- 引用计数
优点: 简单、实时性高
-
缺点: 消耗资源、循环引用
lst1 = [3, 4] # lst1->ref_count 1 lst2 = [8, 9] # lst2->ref_count 1 # lst1 -> [3, 4, lst2] lst1.append(lst2) # lst2->ref_count 2 # lst2 -> [8, 9, lst1] lst2.append(lst1) # lst1->ref_count 2 del lst1 # lst1->ref_count 1 del lst2 # lst2->ref_count 1
- 标记-清除, 分代收集
- 用来回收引用计数无法清除的内存
10. Python 魔术方法
凡是以双下划线开始和结尾的方法
-
__str__格式化输出对象
# __str__格式化输出对象
# 凡是需要格式化输出时调用这个方法
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __str__(self):
return f'Point({self.x}, {self.y})'
# __repr__ 是python2中的,把它看作__str__。
def __repr__(self):
return f'Point({self.x}, {self.y})'
p = Point(1, 2)
print(p)
print(repr(p))
eval() 把字符串转换为对象
x = '1234'
type(eval('1234'))
int
-
__init__和__new__
区别-
__new__创建一个实例,并返回类的实例 -
__init__初始化实例,无返回值 -
__new__是一个类方法
-
# 先创建对象再初始化
# __new__ 创建一个实例,并返回类的实例对象
# __init__ 初始化实例,无返回值
# __new__ 是一个特殊的类方法,不需要使用
p1 = object.__new__(Point) # 创建
print(isinstance(p1, Point)) # 初始化
p1.__init__(1, 2)
print(p1.x)
单例模式
# 这是最简单的单例模式
class A:
pass
aa = A()
# 什么是单例模式
# 单例模式,顾名思义就是程序在运行的过程中,有且只有一个实例。它必须满足三个关键点。
# 1)一个类只有一个实例
# 2)它必须自行创建这个实例。
# 3)它必须自行向整个系统提供这个实例。
# 经常用于数据库的连接池,限制连接数量,达到限制数量则排队等待
# 单例模式有几种,八种。我熟悉元类,__new__方法,和 模块
# 实现单例模式
class A:
# 存实例
instance = None
def __new__(cls, *args, **kwargs):
if cls.instance is None:
cls.instance = object.__new__(cls)
return cls.instance
a = A()
b = A()
print(id(a))
print(id(b))
2423951827072
2423951827072
-
数学运算、比较运算
python类型数学运算
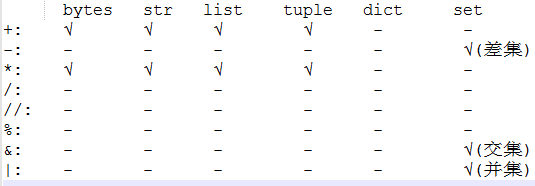 image.png
image.png-
运算符重载
-
+:__add__(value) -
-:__sub__(value) -
*:__mul__(value) -
/:__truediv__(value)(Python 3.x),__div__(value)(Python 2.x) -
//:__floordiv__(value) -
//:__ceil__(value)import math math.ceil() 向上取整 -
%:__mod__(value) -
&:__and__(value) -
|:__or__(value)
-
练习: 实现字典的
__add__方法, 作用相当于 d.update(other) # 相同的key替换值,不同的添加后面
-
class Dict(dict):
def __add__(self, other):
if isinstance(other, dict):
new_dict = {}
new_dict.update(self)
new_dict.update(other)
return new_dict
else:
raise TypeError('not a dict')
dd = {2: 2, 4: 4, 3: 6}
dddd = Dict(dd)
print(dddd + {1: 3, 4: 8})
{2: 2, 4: 8, 3: 6, 1: 3}
key缺失时会调用missing方法
class Dict(dict):
# key缺失时会调用missing
def __missing__(self, key):
self[key] = None
return self[key]
d2 = Dict({1: 2, 2: 4, 3: 6})
# print(d2[5])
# 点之间减运算
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __sub__(self, other):
if isinstance(other, Point):
x = self.x - other.x
y = self.y - other.y
return (x, y)
else:
raise TypeError('not a class')
p1 = Point(2, 2)
p2 = Point(2, 2)
print(p1 - p2)
(0, 0)
* 比较运算符的重载
+ `==`: `__eq__(value)`
+ `!=`: `__ne__(value)`
+ `>`: `__gt__(value)`
+ `>=`: `__ge__(value)`
+ `<`: `__lt__(value)`
+ `<=`: `__le__(value)`
# 比较两个box的大小
class Box:
def __init__(self, l, w, h):
self.l = l
self.w = w
self.h = h
@property
def bulk(self):
return self.l * self.w * self.h
def __lt__(self, other):
if isinstance(other, Box):
return self.bulk < other.bulk
else:
raise TypeError('not a box')
def __str__(self):
return f'Box{self.l}{self.w}{self.h}'
def __repr__(self):
return f'(Box{self.l},{self.w},{self.h})'
b1 = Box(1, 2, 3)
b2 = Box(1, 2, 2)
print(b1 < b2)
print(sorted([b1, b2]))
False
[(Box1,2,2), (Box1,2,3)]
- 练习: 完成一个类, 实现数学上无穷大的概念
class Inf:
def __lt__(self, other):
return False
def __le__(self, other):
return False
def __ge__(self, other):
return True
def __gt__(self, other):
return True
def __eq__(self, other):
return False
def __ne__(self, other):
return True
o = Infinite()
print(o > 149837498317413)
o1 = Infinite()
print(o1 == o)
True
False
-
容器方法
-
__len__-> len -
__iter__-> for -
__contains__-> in -
__getitem__对string, bytes, list, tuple, dict有效 -
__setitem__对list, dict有效
-
可执行对象:
__call__-
上下文管理 with:
-
__enter__进入with代码块前的准备操作 -
__exit__退出时的善后操作 - 文件对象、线程锁、socket 对象 等 都可以使用 with 操作
- 示例
class A: def __enter__(self): return self def __exit__(self, Error, error, traceback): print(args)
-
test = open('test.txt')
print(test.read()) # this is test file.
print(test.closed) # False
test.__exit__()
print(test.closed) # True
print(test.read())
# ValueError: I/O operation on closed file.
with lock:
pass
print(lock.locked()) # True
print(lock.locked()) # False
exceptions = []
class A:
def __enter__(self):
return self
def __exit__(self, *args):
exceptions.append(args)
return exceptions
with A() as a:
pass
print(1)
print(a)
raise KeyError("key error")
print(2)
print(exceptions)
a, b, c = exceptions[0]
print(a)
print(b)
print(c)
#结果
1
<__main__.A object at 0x000001EFDFD86E80>
[(, KeyError('key error',), )]
'key error'
-
__setattr__, __getattribute__, __getattr__, __dict__- 内建函数:
setattr(), getattr(), hasattr()
- 内建函数:
class A:
pass
a = A()
setattr(a, 'x', 123)
print(a.x) # 123
a.y = 234
print(a.y) # 234
a.__setattr__('z', 345)
print(a.z) # 345
getattr(a, 'g', 123)
print(a.g) # AttributeError: 'A' object has no attribute 'g'
print(hasattr(a, 'g')) # False
getattr(a, 'l') if hasattr(a, 'l') else setattr(a, 'l', 999)
print(a.l, a.__dict__.get('l'), a.__dict__) # 999 999 {'x': 123, 'y': 234, 'z': 345, 'l': 999}
print(a.__dict__.pop('l'), a.__dict__) # 999 {'x': 123, 'y': 234, 'z': 345}
a.__dict__['l'] = 999
print(a.__dict__) # {'x': 123, 'y': 234, 'z': 345, 'l': 999}
* 常用来做属性监听
```python
class User:
'''TestClass'''
z = [7,8,9]
def __init__(self):
self.money = 10000
self.y = 'abc'
def __setattr__(self, name, value):
if name == 'money' and value < 0:
raise ValueError('money < 0')
print('set %s to %s' % (name, value))
object.__setattr__(self, name, value)
def __getattribute__(self, name):
print('get %s' % name)
return object.__getattribute__(self, name)
def __getattr__(self, name):
print('not has %s' % name)
return -1
def foo(self, x, y):
return x ** y
```
class B:
z = 123
def __init__(self, x, y):
self.x = x
self.y = y
b = B(1, 2)
print(b.__dict__) # {'x': 1, 'y': 2}
print(b.z) # 123
print(B.__dict__)
# {'__module__': '__main__', 'z': 123, '__init__': , '__dict__': , '__weakref__': , '__doc__': None}
- 槽:
__slots__- 固定类所具有的属性
- 实例不会分配
__dict__ - 实例无法动态添加属性
- 优化内存分配,大约能节省40%内存
意思就是:买来一台电脑只有两个内存条卡槽,你再买一条来加内存,无法加入。
class C:
__slots__ = ('x', 'y')
c = C()
c.__dict__ # AttributeError: 'C' object has no attribute '__dict__'
c.x = 10
c.y = 20
print(c.x) # 20
c.l = 20 # AttributeError: 'C' object has no attribute 'l'
11. Python 性能之困
python相对于静态语言,稍微慢了一些
-
计算密集型
- CPU 长时间满负荷运行, 如图像处理、大数据运算、圆周率计算等
- 计算密集型: 用 C 语言补充
- Profile #统计函数运行的时间, timeit (timeit -n times -r func)
-
I/O 密集型
- 网络 IO, 文件 IO, 设备 IO 等
- 一切皆文件
-
多任务处理
进程、线程不能控制,由操作系统控制- 进程、线程、协程调度的过程叫做上下文切换
- 进程、线程、协程对比
进程
import random
from multiprocessing import Process
def foo(n):
x = 0
for i in range(n):
x += random.randint(1, 100)
q.put(x)
return x
def bar(q, n):
for i in range(n):
data = q.get()
print(f'取到了数据{data}')
if __name == 'main':
#创建一个队列
q = Queue()
# q = Queue(10) #限制10个
# for i in range(15):
# print(i)
# #q.put(i, block=False) # 当block=False会报异常queue full
# q.put(i, timeout=5) # 5秒后报异常queue full
# 创建进程1
p1 = Process(target=foo, args=(1000,q))
p1.start()
# p.join() # 同步执行,这句话保证子进程结束后再向下执行 # p.join(2)#等待2s
# print(q.qsize()) # 长度
# 1000
# 创建进程1
p2 = Process(target=foo, args=(1000,q))
p2.start()
名称 | 资源占用 | 数据通信 | 上下文切换 (Context)
-----|---------|------------------------------|------------------
进程 | 大 | 不方便 (网络、共享内存、管道等) | 操作系统按时间片切换, 不够灵活, 慢
线程 | 小 | 非常方便 | 按时间片切换, 不够灵活, 快
协程 | 非常小 | 非常方便 | 根据I/O事件切换, 更加有效的利用 CPU
-
全局解释器锁 ( GIL )
- 它确保任何时候一个进程中都只有一个 Python 线程能进入 CPU 执行。
- 全局解释器锁造成单个进程无法使用多个 CPU 核心
- 通过多进程来利用多个 CPU 核心,一般进程数与CPU核心数相等,或者CPU核心数两倍
[图片上传失败...(image-7ae5ee-1537289041588)]
-
什么是同步、异步、阻塞、非阻塞?
- 同步, 异步: 客户端调用服务器接口时
- 阻塞, 非阻塞: 服务端发生等待
- 阻塞 -> 非阻塞
- 同步 -> 异步
-
协程:Stackless / greenlets / gevent | tornado / asyncio
import asyncio async def foo(n): for i in range(10): print('wait %s s' % n) await asyncio.sleep(n) return i task1 = foo(1) task2 = foo(1.5) tasks = [asyncio.ensure_future(task1), asyncio.ensure_future(task2)] loop = asyncio.get_event_loop() # 事件循环,协程调度器 loop.run_until_complete( asyncio.wait(tasks) ) -
线程安全, 锁
- 获得锁之后, 一定要释放, 避免死锁
- 尽量使用 with 去操作锁
- 获得锁之后, 执行的语句, 只跟被锁资源有关
- 线程之间的数据交互尽量使用 Queue
12. 一些技巧和误区
-
格式化打印 json
- 调试时数据格式化:
json.dumps(data, indent=4, sort_keys=True, ensure_ascii=False) - 传输时 json 压缩:
json.dumps(data, ensure_ascii=False, separators=[',',':'])
- 调试时数据格式化:
-
确保能取到有效值
-
d.get(k, default)无值时使用默认值,对原字典无修改 -
d.setdefault无值时使用默认值,并将默认值写入原字典 x = a if foo() else b-
a or bpython中所有的对象都有真值
-
-
try...except... 的滥用
- 不要把所有东西全都包住, 程序错误需要报出来
- 使用
try...except要指明具体错误,try结构不是用来隐藏错误的, 而是用来有方向的处理错误的
-
利用 dict 做模式匹配
def do1(): print('i am do1') def do2(): print('i am do2') def do3(): print('i am do3') def do4(): print('i am do4') mapping = {1: do1, 2: do2, 3: do3, 4: do4} mod = random.randint(1, 10) func = mapping.get(mod, do4) func() inf, -inf, nan
inf 极大数 任何数相比都是-inf大
-inf 极小数 任何数相比都是-inf小字符串拼接尽量使用
join方式: 速度快, 内存消耗小
如果用 ‘+’号,会有内存碎片,用join则无。property: 把一个方法属性化
class C(object):
@property
def x(self):
"I am the 'x' property."
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x
if __name__ == '__main__':
c = C()
c.x = 10
print(c.x)
del c.x
# print(c.x)
if __name__ == '__main__':
c = C()
c.x = 10 # set 10
print(c.x) # 10
del c.x # del 10
print(c.x) # AttributeError: 'C' object has no attribute '_x'
- else 子句:
if, for, while, try -
- collections 模块
- defaultdict 当你找不到的时候会把找不到的key和value添加到里面取
- OrderedDict 是一个有序的字典,按插入时的顺序循环出来
- Counter 计数器
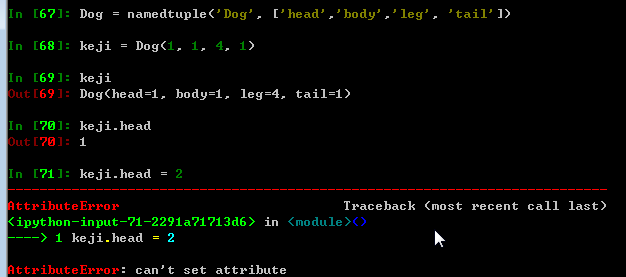
c = Counter() for i in range(1000) n = random.randint(1,100) c[n] += 1- namedtuple 当成一个类,特性是当设置了值即不可变。
- pyenv day19-14:55
若提示未装git
则yum install git
11.devops运维