用 RPA 做一个简单的爬虫
之前写爬虫一直都是用的 Scrapy,强大而高效,直到后来接触了 RPA,呃,还是蛮适合新手的。
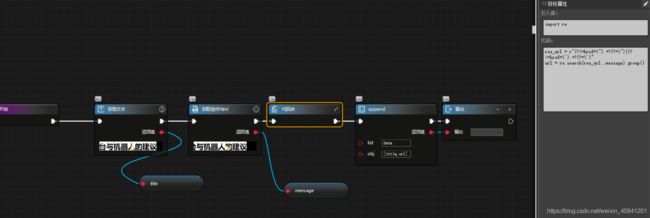
1、获取文章标题和链接
获取文章标题直接用“获取文本”就可以了。
但获取链接,就需要使用“获取控件 html”这个组件,然后使用正则表达式了。
import re
message = '艺赛旗RPA控制台与机器人的建议
'
res_url = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
url = re.search(res_url ,message).group()
当然,文章的标题也可以这样获取到,但是可以少些代码,干嘛去多写行代码呢。
获取标题 title 和链接 url 就这样了,最后添加到一个空列表内进行保存:
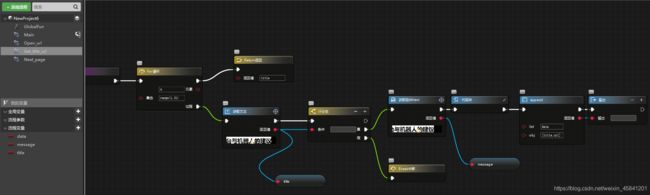
2、获取当前页面所有文章的标题和链接
不同文章在页面中的位置不一样,看似很难,但其实简单得很,只要修改下“查找路径”这个参数就好了。
第一篇文章到最后一篇文章的 selector:

因此可以设置查找路径为:
‘body > DIV:nth-of-type(2) > DIV:nth-of-type(1) > DIV:nth-of-type(1) > DIV:nth-of-type(1) > DIV:nth-of-type(2) > UL:nth-of-type(1) > LI:nth-of-type(%d) > H2:nth-of-type(1) > A:nth-of-type(1)’%n
n便是每次循环自增的变量啦。
不过若是当前页面没有 30 篇文章,那就会让“获取文本”返回的 title 为空,这个时候就没有再执行下去的必要了。
所以添加个“if 分支”作判断:
3、获取下一个页面的的所有文章的标题和链接
循环结束的时候,“鼠标点击”下一个页码进入下一个页面就是了。
另外,获取文章为空了,肯定是最后一页,这种情况下就不需要进行点击下一页了,退出循环即可。
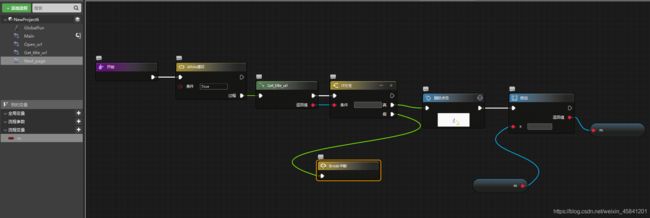
同样通过修改“查找路径”参数设置循环,其中流程变量 m 默认初始值为 2:
‘A[textNode=%d]’%m

不过这里有一点很重要,点击下一页后,页面的网址是会变化的!
所以“鼠标点击”里的那个“网址”参数需要修改,否则就会找不到网页元素而抛出异常。
不过这也容易解决,只要将变化的部分用*代替就可以。

所以上个步骤中有关拾取组件的“网址”参数也需要修改的。
END
完结。
 更多RPA知识,欢迎访问艺赛旗社区:https://support.i-search.com.cn/
更多RPA知识,欢迎访问艺赛旗社区:https://support.i-search.com.cn/