python基础--python入门(二)
python的学习是一个徐徐渐进的过程,接下来需要记录一些第一次接触python时需要注意的地方,全是自己的自学结果,希望看到的朋友要有自己的思考,如果有其他的建议,也请留言,一块一块学习。
第一行代码
print("Hello World!")这个代码的输出结果就是Hello World!,基本上所有的编程语言在你开始学习的时候,都是学会打印输出“你好,世界!”这句话,所以我们也从这里开始吧!
下边我们看一下代码的流浪之路吧:
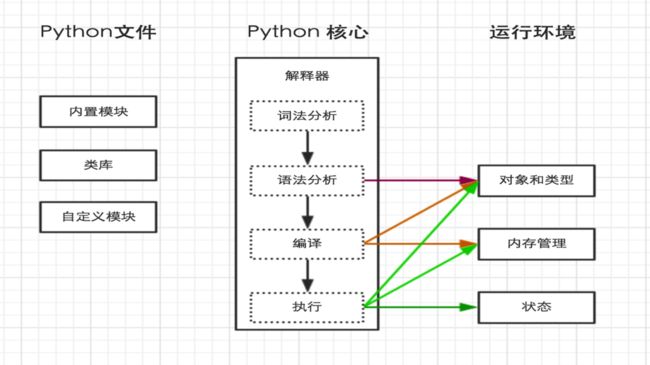
2、python的执行
windows的情况下,一般在IDE中直接执行就可以输出结果了
linux中需要指定python的解释器,需要在代码文件中添加 /usr/bin/python 就是python的解释器的路径。
3、python的内容编码
python解释器在加载 .py 文件中的代码时,其中python2的解释器默认的编码是ASCII编码,而python3解释的默认编码是utf-8编码。
查看解释器的默认编码:
import sys
print(sys.getdefaultencoding())ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。
python2 悄悄掩盖掉了byte到unicode的转换,只要数据全部是ASCII的话,所有的转换都是正确的,一旦一个非ASCII字符偷偷进入你的程序,那么默认的解码将会失效,从而造成Unicode DecodeError 的错误,Python2编码让程序在处理ASCII的时候更加简单,你付出的代价就是在处理非ASCII的时候将会失败。
python3也有两种数据:str和bytes;str类型存unicode数据,bytes类型存bytes数据,与python2比只是换了一下名字而已。
python3的编码哲学:
python3最重要的新特性大概要算是对文本和二进制数据做了更为清晰的区分,不再会对bytes字节串进行自动解码,文本总是Unicode,有str类型表示,二进制数据有bytes类型表示。Python3 不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰,你不能拼接字符串和字节包,也无法在字节中搜索字符串(反之亦然)。
4、注释
# 单行注释
''' ''' 多行注释
5、执行脚本的参数捕捉
python内部提供的sys模块中,有一个argv函数,用来捕获执行python脚本时传入的参数。
6、变量
1、声明变量
|
1
2
3
4
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
name
=
"zhouyang"
|
上述代码声明了一个变量,变量名为: name,变量name的值为:"zhouyang"
变量的作用:昵称,其代指内存里某个地址中保存的内容
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']