本篇文章内容来自2016年TOP100summit QQ空间客户端研发总监王辉的案例分享。
编辑:Cynthia
王辉:腾讯SNG社交平台部研发总监、腾讯QQ空间移动客户端技术负责人高级工程师。09年起负责QQ空间技术研发,经历从Web时代到移动客户端技术的转变,在Web、移动终端上都有不错的技术积累。
导读:移动互联网飞速发展,2016年,社交网络对视频技术的应用得到爆发式的增长,短视频、视频直播、视频滤镜、视频人脸动效、音乐、K歌、变声、连麦等功能陆续在产品中上线,如何在快速上线功能的同时,保证稳定流畅的体验,成为挑战。
主要面临的挑战如下:
1、复杂的网络环境下,如何保证视频播放的成功率,如何保证直播的流畅度,减少卡顿?
2、体验上,如何保证快速流畅的播放体验,如何实现直播秒开,即点即播?
3、性能上,直播中滤镜、美容、人脸动效,效果全开,如何保证主播端的性能?
4、亿级海量并发用户情况下,如何更好的保障质量,柔性带宽的策略如何做到极致?
本案例围绕上述挑战进行,揭秘腾讯QQ空间团队在挑战中的一些优化尝试。
一、案例介绍
QQ空间目前是国内最大的SNS社区,日高峰上传5亿张图片,播放10亿个视频,6.3亿用户在这里分享生活,留住感动,其中主流人群正是95后的年轻人。
也正因为是年轻人,且年轻人是生活方式转变的主要推动力,不满足于现在图片+视频传统的分享方式,他们希望通过直播的方式让你“现在、立刻、马上”看到我。这就是内容消费的升级,同时伴随着手机硬件的升级、流量费用的下降,于是手机直播变为可能。
而我们的直播产品定位也是基于目标用户生活的内容,外加社交的传播力量,有别于现在主流的网络+游戏直播的模式。
带来的好处是:用户创造的内容更多元化,更贴近生活,更能在好友间产生共鸣和传播;
带来的问题是:我们要兼容的移动终端也是海量的,性能问题是我们重点关注的内容。
在以上背景下,我们开始做直播了。目标是一个月内构建直播的闭环能力,也就是快速上线。需要实现发起直播、观看直播(1人发起,多人观看)、回看直播(回放)、直播互动(直播间中的评论、送礼等)、直播沉淀(Feeds沉淀、分享直播等)等功能(可参考图1);且同时支持Android、iOS、Html5三大平台(即方案成熟),并且支持空间以及手机QQ内的空间。
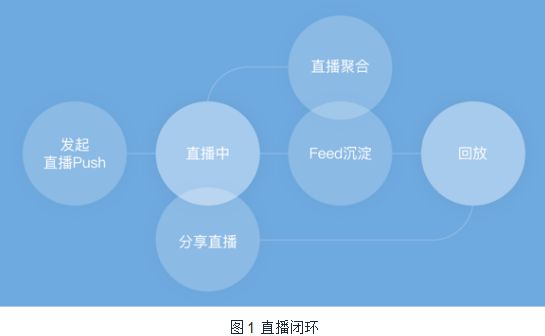
首先我们就面临项目工期紧张、团队直播技术积累不够的问题。虽然如此,但我们仍然硬着头皮继续与各大相关技术提供商进行交流,根据我们的标准以及提供商的建议进行技术选型,我们的标准如下:
● 专业度好(直播低时延迟,支持全平台、基础服务建设好);
● 开放源代码;
● 支持度高,有问题可以随时沟通解决;
● 支持动态扩容。
最后根据标准选择了腾讯云提供的ILVB直播解决方案,尤其音视频相关组在这块有多年技术积累,并且同部门可合作共赢。
这其中值得一提的是我们的闭环研发模式也促使我们以及合作伙伴不断提升产品质量。首先快速上线(完成产品需求,并完善监控),再在上线后查看监控数据(分析数据),接着应用到优化工作(跟进数据、专项优化),最后进行灰度验证(灰度一部分用户验证优化效果),根据效果再决定是否正式应用到产品中(如图2)。

最后,我们如愿实现了1个月上线,同时支持QQ空间和手机QQ(结合版QQ空间),到目前为止已经迭代12+版本。观看量也从5月份的百万级到8月份的千万级、到现在的亿级,成为用户参与的大众化全民直播。产品数据也跟随用户的需求一直在飙升,随之而来的是各种各样的问题反馈,尤其是性能问题,这也是本文要重点讨论的话题。
二、直播架构
在介绍直播架构前,我想有必要给大家再复习一下H264编码,目前市面上直播的视频编码基本都是H.264。H264有三种帧类型:完整编码的帧叫I帧、参考之前的I帧生成的只包含差异部分编码的帧叫P帧、还有一种参考前后的帧编码的帧叫B帧。H264的压缩流程为分组(把几帧数据分为一个GOP,一个帧序列)、定义帧类型、预测帧(以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧)、数据传输。
用简单的例子来解释视频模型,如果把一个GOP(Group of pictures)当做一列拉货的火车,那一段视频就是N辆火车组成的货运车队(图3)。
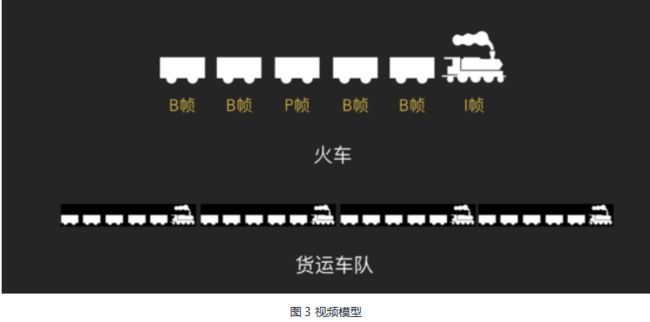
直播就是视频数据的流动,边拍摄、边传输、边播放的数据流动过程。数据由主播生产装车,经过网络(铁路),再到观众端卸货并进行播放消费。
火车需要调度,视频流也一样,这就是视频流协议,即通过协议控制视频有序的传输给观众。
常见协议如图4:
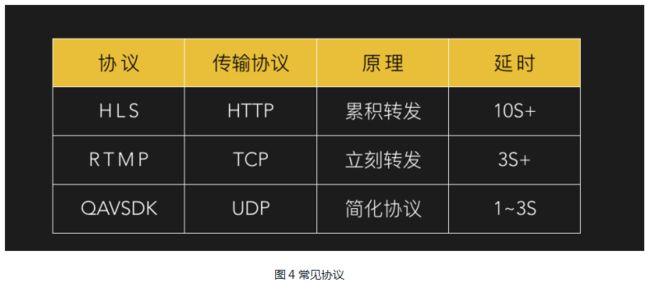
我们采用的是腾讯云基于UDP开发的QAVSDK协议。
前面讲了协议相关的内容,下面讲讲我们的直播模型,如图5:
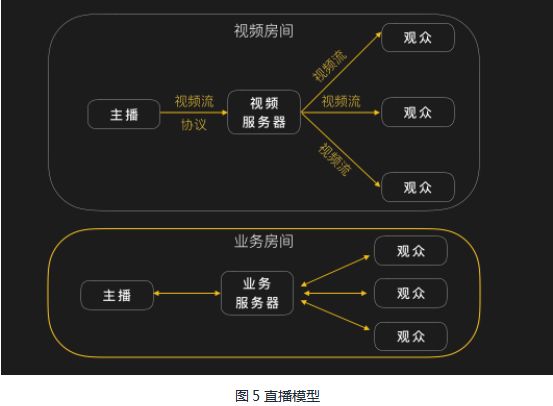
视频房间(视频流)以及业务房间(相关业务逻辑互动)大致结构差不多,差别在于数据流动(注意图5中箭头)。
视频房间数据由主播通过视频流协议流向视频服务器,而视频服务器也通过视频流协议把数据下发给观众,观众端解码并播放。主播只上传,观众只下载。而业务房间任何人都需要给服务器发送相关的业务请求(如评论,当然客户端会屏蔽一些特殊逻辑,如主播不可送礼给自己)。更详细的结构如图6:
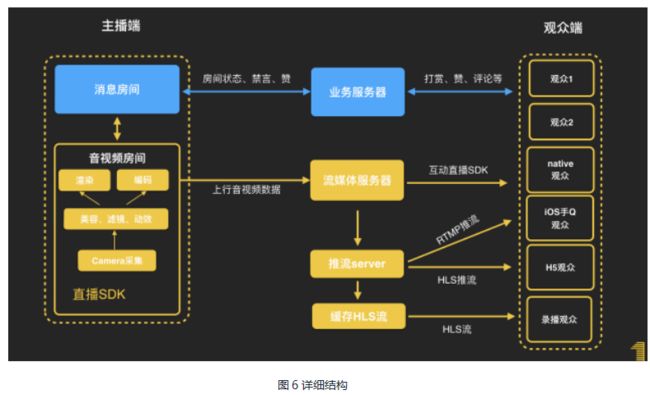
注:iOS手Q观众采用RTMP协议不是因为不支持QAVSDK,而是因为手Q有减包压力,而QAVSDK相关的SDK占用空间较大。
三、技术优化
接下来进入本文的重头戏:技术优化。技术优化分为四个方面:秒开优化(耗时类优化实践)、性能优化(性能优化实践)、卡顿优化(问题分析类实践)、回放优化(成本类优化实践)。
在优化之前,我们的必要工作是监控统计先行,我们会对我们关心的数据点进行前期的统计,并做相关报表和告警,以辅助优化分析。
监控分为以下五部分:
● 成功率,发起直播成功率、观看直播成功率、错误占比列表;
● 耗时,发起直播耗时、进入直播耗时;
● 直播质量,卡帧率、0帧率;
● 问题定位,各步骤流水、直播2s流水、客户端日志;
● 实时告警,短信、微信等方式。
通过这些,我们实现了数据的查看、分析定位、以及实时的告警,从而更方便地解决问题。
四、秒开优化
几乎所有人都在吐槽“为什么直播打开很慢,竞品比我们快多了!!!”,我们自己也觉得不能忍。我们要让观看直播达到秒开(从点击直播到看到画面,耗时在1秒以内),而统计到的外网平均打开耗时为4.27秒,离秒开还有一定的差距。
于是我们梳理从点开到渲染第一帧画面这一段时间的时序关系,同时统计各阶段的耗时。流程图和耗时大致如图7 :
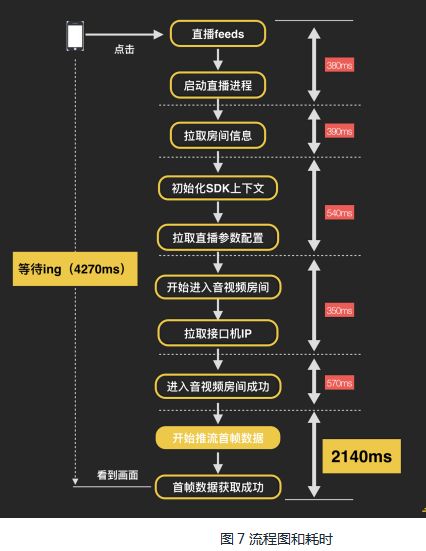
通过流程分析和数据分析发现两个耗时原因是:获取首帧数据耗时太长、核心逻辑串行。接下来我们针对这两个问题进行优化。
首帧耗时太长。核心问题在于加速首个GOP到达观众的时间。
我们的优化方案是:让接口机缓存首帧数据,同时对播放器进行改造,解析到I帧就开始播放。这样大大加快了观众看到首帧的时间。
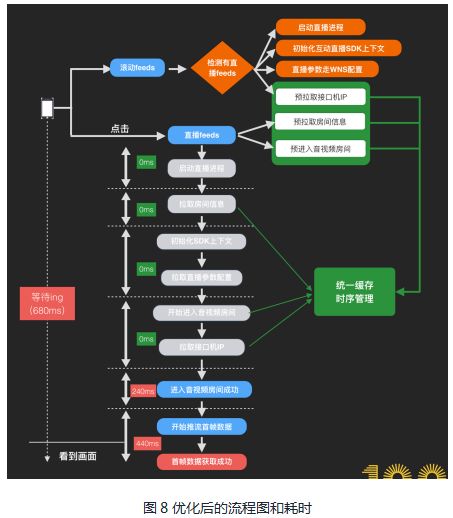
核心逻辑串行。这部分我们主要通过以下流程:
● 预加载,提前准备环境和数据,如在feeds中提前预拉起直播进程,提前获取接口机IP数据;
● 延迟加载,对UI、评论等其他逻辑进行延迟加载,让出系统资源给首帧;
● 缓存,如缓存接口机IP数据,一段时间内复用;
● 串行变并行,同时拉取数据,节省时间;
● 对单步骤耗时逻辑进行优化和梳理,减少单步耗时。
优化后的流程和耗时大致如图8所示,耗时降低到680ms,目标达成!
五、性能优化
产品不断迭代,直播的玩法也越来越丰富了,同时一些性能问题也不断暴露出来。尤其我们后来增加了动效贴纸、滤镜、变声等功能,大量用户反馈直播很卡。
通过统计发现:主播短帧率很低,画面不连续,主观感觉卡;另外,用户使用设备中也有大量的低端机。如图9所示。

通过分析发现帧率低的主要原因是单帧图像处理耗时过长导致,而编码所占因素较低。一般总耗时=处理工作量*单帧耗时。于是我们逐渐对这两方面进行优化。
减少图像处理工作量
● 采集分辨率与处理分辨率一致,比如编码为960×540,由于有些手机可能不支持这个采集分辨率,采集一般都是1280*1024,之前处理是先处理再缩放,现在先缩放再处理,减少图像在滤镜、动效贴纸中的处理耗时。如图10

● 处理帧前丢帧。虽然我们对系统相机设置了采集帧率,但是很多机型并不生效,于是我们通过策略对额外的帧进行丢弃,减少图像处理的帧数。比如我们设置采集帧率为15,但实际有25,这多余的10帧处理了在编码的时候也会浪费,之前就丢弃,可减少资源消耗。
● 机型分档位,不同的机型根据不同的硬件能力采用不用的采集帧率和编码帧率,保证流畅;同时在过热的时候以及回归正常时动态调整帧率去调整资源消耗。
● 人脸识别采集优化,每帧识别改为两帧识别一次人脸,既不会产生人脸漂移也可以减少处理耗时。
减少单帧耗时
● 采集流程改造,减少了大约33%的不必要耗时,如图11.

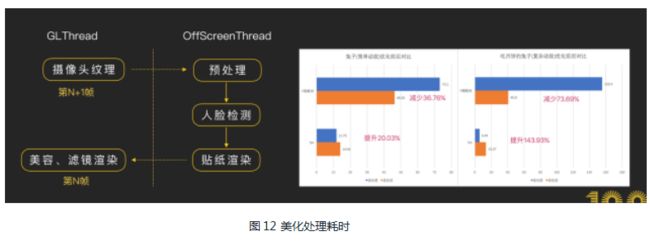
● 动效贴纸多GL线程渲染,贴纸渲染放在另外一个OffScreenThread进行渲染,完全不占用整个美化处理过程的时间,效果如图12:
● 动效贴纸采用OpenGL混合模式;
● 图像处理算法优化,如ShareBuffer优化(实现在GPU与内存之间快速拷贝数据,排除CPU介入,节省纹理转RGBA时间;耗时几乎降低一半,FPS也至少提升2-3帧左右),滤镜LUT优化,如图13.

除了以上两个大的优化点,我们还推动更多的机器采用硬件编码。首先编码稳定,帧率不会波动;其次,占用CPU会有一定降低。
以上是我们大致的一些优化点,优化之后,用户直播投诉大量减少。
六、卡顿优化
我们先看一些相关的定义:
卡顿用户定义:(卡顿时长/总时长)>5%定义为卡顿用户,卡顿率=卡顿用户/总用户。
主播卡顿点定义:上行大画面编码后帧率<5的点数。
观众卡顿点定义:解码后帧率<5的点数。
我们的目标就是让卡顿率达到50%以下。
当然上行发生卡顿时,会造成所有用户卡顿,而下行卡顿时,只有单个观众才会卡顿。
我们看看会造成卡顿的原因,见图14 :
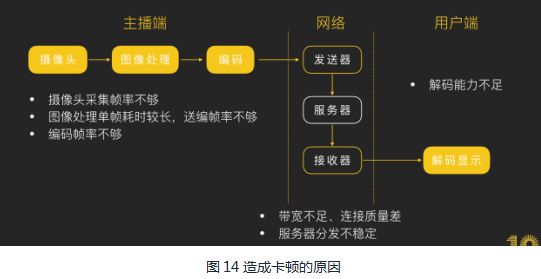
大概有主播端、网络、观众端三个大的模块可能会导致卡顿问题,而主播端的性能优化基本解决了,那就看下网络以及观众端的。
从统计数据发现网络质量影响占比达到50%左右,这明显要优化。于是网络上行优化我们做了图15的事情,减少单帧中的数据以及减少帧数,用火车的例子就是减少货物以及控制火车数量。

而用户端下行优化则是囤积货物,丢掉货物,如图16 。

如图17,我们来看优化后的效果,与竞品相比优势十分明显:
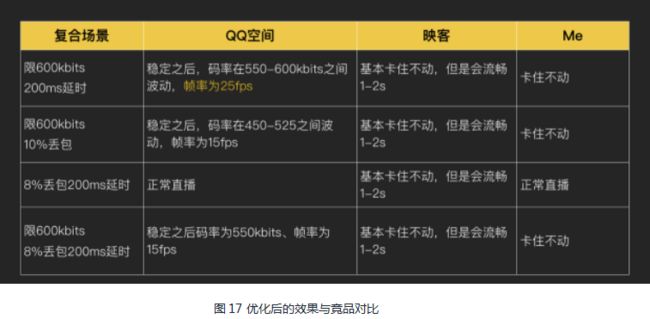
同时,主播卡顿率也下降到30%,观众卡顿率下降到40%,目标算是达成了。
七、回放优化
如图18,我们先来看看直播回看(回放)的大致流程:

回放同样也存在一些问题,主要体现在两个方面:
● 回放直播质量:服务器器端保存,回看视频质量受主播短网络影响较大
● 服务器成本:服务器除了需要推一个私有协议流,另外还需要对私有流进行转码成HLS和MP4以便回放使用
在方案选择上,MP4具有播放方案成熟、速度快、用户体验佳等优点;而HLS系统支持差、用户等待时间也长。那是否意味着我们要直接选择MP4方案呢?
其实回看采用HLS以及MP4都是可以的,但是直播观看时由于数据是在变化的,HTML5只能使用HLS,如果我们回看的时候使用MP4,那就等于服务器需要对私有协议流分别转码成MP4和HLS,那这明显不经济。这就致使我们选择HLS,服务器只需要转码一次流为HLS即可。
既然选择HLS,我们就要针对性地解决HLS存在的问题。
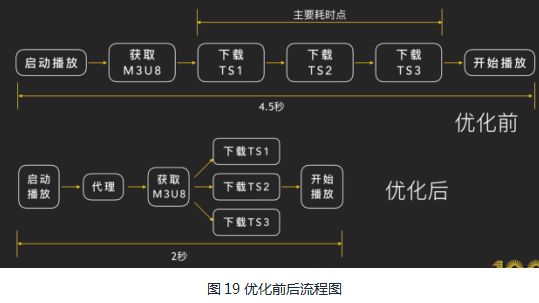
在Android平台上,Android 3.0开始支持HLS,后来因为Google官方想推DASH取代HLS,对HLS的支持便慢慢减弱了,在官方文档上甚至找不到一点儿关于HLS的说明。经实践发现Android原生播放器对HLS的支持程度仅仅是能播,完全没有任何优化。这样不仅会有多余的m3u8文件请求,而且启动播放后整个流程是串行的,非常影响视频画面的首帧可见耗时(平均耗时4.5s左右)。
我们可以通过本地代理提前下载来解决这个问题,接入下载代理后,在代理层可以对m3u8文件的内容进行扫描,并触发对ts分片的并行下载,把ts数据缓存起来。经过这样的处理后,虽然播放器的层面还是串行下载,由于我们已经提前准备好了数据,数据会很快返回给播放器,这样就实现了我们降低首帧耗时的效果,经实验接入后平均首帧可见耗时降低到了2s左右。
优化前后流程图见图19:
缓存策略上,HLS的缓存业界目前还没有成熟方案。我们实现了对图20中三种模式的自动侦测与支持,使用方完全不需要关心底层的缓存与下载逻辑。

最后,服务器成本方面节省了50%的转码计算和存储成本;另外,回放的加载速度也变快了。
八、案例总结
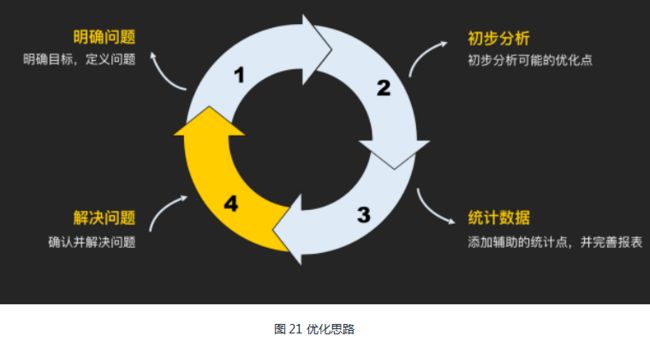
通过之前的案例和相关优化分析,总结出三种大致的问题模式,以及相应的优化思路。
● 速度类:理清时序,统计各阶段耗时,各个击破;
● 性能类:通过Trace,明确性能损耗点,各个击破;
问题解决类:建立模型,初步分析,统计上报,确认问题,各个击破。
总结成一个套路就是图21 :
在案例中也体现了以下一些参考点:
● 快速迭代,小步快跑
● 监控驱动优化
● 建立模型,抽象问题直观分析
● 产品定位决定优化的方向
● 海量服务,以小省大
最后,以一张空间直播的拓补图作为结束本文(图22)。
TOP100全球软件案例研究峰会已举办六届,甄选全球软件研发优秀案例,每年参会者达2000人次。包含产品、团队、架构、运维、大数据、人工智能等多个技术专场,现场学习谷歌、微软、腾讯、阿里、百度等一线互联网企业的最新研发实践。大会开幕式单天体验票申请入口