Flink-Storm 是 Flink 官方提供的用于 Flink 兼容 Storm 程序 beta 工具,并且在 Release 1.8 之后去掉相关代码。本文主要讲述 58 实时计算平台如何优化 Flink-Storm 以及基于 Flink-Storm 实现真实场景下大规模 Storm 任务平滑迁移 Flink。
背景
58 实时计算平台旨在为集团业务部门提供稳定高效实时计算服务,主要基于 Storm 和 Spark Streaming 构建,但在使用过程中也面临一些问题,主要包括 Storm 在吞吐量不足以及多集群带来运维问题,Spark Streaming 又无法满足低延迟的要求。Apache Flink 开源之后,其在架构设计、计算性能和稳定性上体现出的优势,使我们决定采用 Flink 作为新一代实时计算平台的计算引擎。同时基于 Flink 开发了一站式高性能实时计算平台 Wstream,支持 Flink jar,Stream Sql,Flink-Storm 等多样化任务构建方式。
在完善 Flink 平台建设的同时,我们也启动 Storm 任务迁移 Flink 计划,旨在提升实时计算平台整体效率,减少机器成本和运维成本。
Storm vs Flink

尽管 Flink 作为高性能计算引擎可以很好兼容 Storm,但在业务迁移过程中,我们仍然遇到了一些问题:
1.用户对 Flink 的学习成本;
- 重新基于 Flink 开发耗费工作量;
- Stream-SQL 虽然可以满足快速开发减少学习成本和开发工作量但无法满足一些复杂场景。
因此我们决定采用 Flink 官方提供的 Flink-Storm 进行迁移,在保障迁移稳定性同时无需用户修改 Storm 代码逻辑。
Flink-Storm 原理
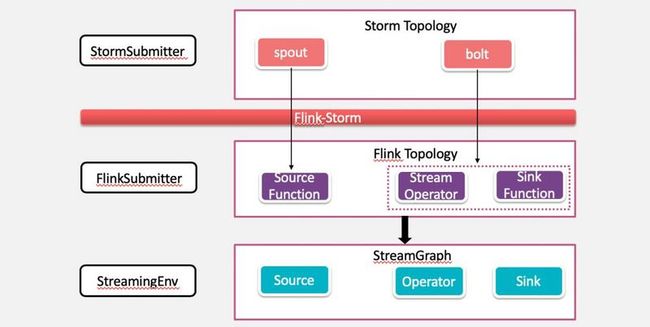
通过 Storm 原生 TopologyBuilder 构建好 Storm topology。
FlinkTopology.createTopology(builder) 将 StormTopology 转换为 Flink 对应的 Streaming Dataflow。
SpoutWrapper 用于将 spout 转换为 RichParallelSourceFunction,spout 的OutputFields转换成 source 的T ypeInformation。
BoltWrapper 用于将 bolt 转换成对应的 operator,其中 grouping 转换为对 spout 的 DataStream 的对应操作。
构建完 FlinkTopology 之后,就可以通过 StreamExecutionEnvironment 生成 StreamGraph 获取 JobGraph,之后将 JobGraph 提交到 Flink 运行时环境。
实践
Flink-Storm 作为官方提供 Flink 兼容 Storm 程序为我们实现无缝迁移提供了可行性,但是作为 beta 版本,在实际使用过程中存在很多无法满足现实场景的情况,主要包括版本,功能 bug,复杂逻辑兼容,无法支持 yarn 等,下面将主要分为平台层面和用户层面讲述我们的使用和改进。

平台层面
1. 版本
当前线上使用 Apache Flink 1.6 版本,Flink-Storm 模块基于 Storm 1.0 开发,我们平台运行 Storm 版本为 0.9.5 和 1.2 。
1.1 对于 Storm 1.2 运行任务,Storm 1.0 API 完全兼容 1.2 版本,因此只需切换 Flink-Storm 模块依赖的 storm-core 到 1.2.

1.2 对于 Storm 0.9.5 任务,由于 Storm 1.0 API 无法兼容 0.9.5,需要修改依赖 storm-core 为 0.9.5,同时修改 Flink-Storm 模块中所有与 Storm 相关的 API,主要是切换 package 路径。

1.3 重新构建 flink-storm 包 mvn clean package -Dmaven.test.skip=true -Dcheckstyle.skip=true
2.功能
2.1 传递语义保证
Storm 使用 ACK 机制来实现传递语义保证,我们没有将 Storm 的 ACK 机制移植到Flink-Storm。因此,某些依赖 ACK 机制的功能会受到限制。比如,Kafka spout 将消费状态存储在 ZK,状态的更新需要依赖 ACK 机制,tuple 树结束后,spout 才会触发状态更新,表示这条消息已经被完全处理,从而实现 at least once 的传递保证。Storm 也提供了at most once 的支持,spout 发送消息后,无需等待 tuple 树结束直接触发状态更新。我们使用了 Storm 的实现 at most once 的方式,在 Kafka spout 实现 at most once 的基础上,通过实现 Flink Checkpoint 的状态机制,实现了 Flink-storm 任务的 at least once。Storm 任务迁移到 Flink,传递保证不变。
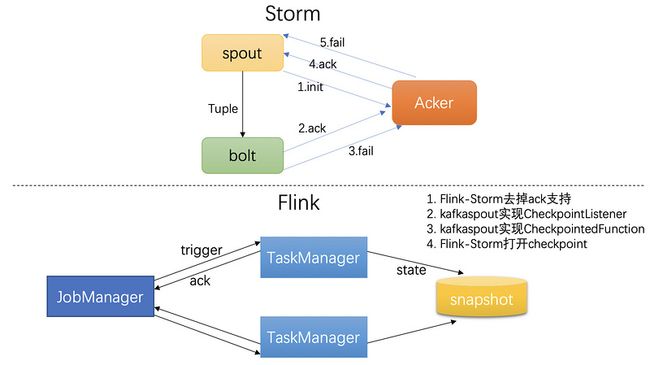
2.2 tick tuple 机制
Storm 使用 tick tuple 机制实现定时功能,消息超时重发、Bolt 定时触发等功能都要依赖 tick tuple 机制。Storm 0.9.5 版本没有实现窗口功能,用户可以使用 tick tuple 机制简单实现窗口功能。我们同样为 Flink-Storm 增加了 tick tuple 机制的支持,使用方式也和 Storm 中使用方式一样,配置 topology.tick.tuple. freq.secs 参数,即开启了 tick tuple 功能。
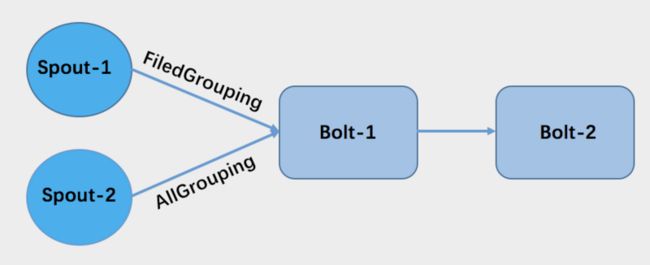
2.3 多输入下 AllGrouping 支持
AllGrouping 分组方式对应于 Flink 是 Broadcast。如图,bolt-1 有两个输入,这种情况下,原 flink-storm 的实现,spout-2 到 bolt-1 的数据分区的表现形式和Rebalance(Flink 术语)一样,而不是 Broadcast。我们优化了这种场景,使其数据分组表现和 Storm 中是一样的。
3.Runtime
Flink-Storm 默认支持 local 和 standalong 模式任务提交,无法将任务提交到 yarn 集群,我们在建设 Flink 集群一开始就选择了 yarn 模式,便于集群资源管理和统一实时计算平台,因此需要自行实现支持 yarn 的 runtime 功能,这里主要涉及 yarn client 端设计。
YARN Client 实现机制
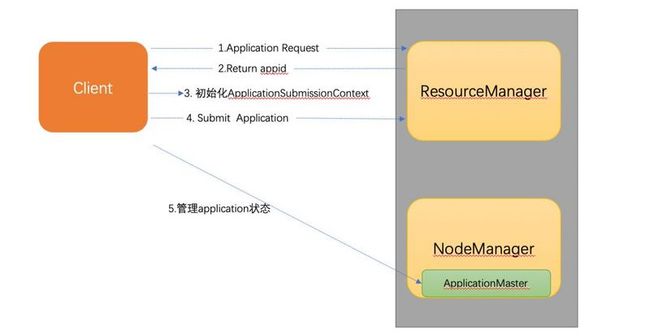
整个模块主要分为四个部分,其中 client 用于调用 Flink-Storm 程序转化接口,得到 Flink jobGraph。配置参数用于初始化 Flink 及 yarn 相关配置,构建运行时环境,命令行工具主要用于更加灵活的管理。yarnClient 主要实现 ApplicationClientProtocol 接口,完成与 ResourceManager 与 ApplicationMaster 的交互,实现 Flink job 提交和监控。

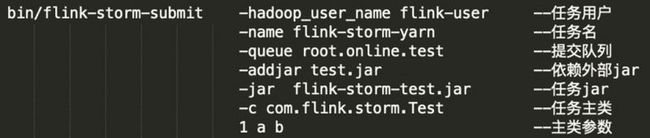
4.任务部署
为便于任务提交和集成到 Wstream 平台,提供类似 Flink 命令行提交方式:
用户层面
1.maven 依赖
平台将编译好的包上传到公司 maven 私服供用户下载对应版本 Flink-Storm 依赖包:

2.代码改动
用户需要将 Storm 提交任务的方式改成 Flink 提交,其他无需变动。

总结
通过对 Fink-Storm 的优化和使用,我们已经顺利完成多个 Storm 集群任务迁移和下线,在保障实时性及吞吐量的基础上可以节约计算资源 40% 以上,同时借助 yarn 统一管理实时计算平台无需维护多套 Storm 集群,整体提升了平台资源利用率,减轻平台运维工作量。
作者介绍:万石康,来自 58 集团 TEG,后端高级工程师,专注于大数据实时计算架构设计。
阅读原文
本文为云栖社区原创内容,未经允许不得转载。