hadoop - hadoop2.6 伪分布式 - eclipse 中 配置 和 示例 wordcount
1.配置eclipse
1.1 下载 linux版的 eclipse
百度云 - 大数据资料专辑
1.2 解压
可以手动提取,也可以命令提取:
yuan@LABELNET:~/JAVA$ sudo tar -zxvf eclipse.tar.gz ~/JAVA/
1.3 运行
yuan@LABELNET:~/Java/eclipse$ ./eclipse1.4 图标
我的是 deepin 15- linux 操作系统 ,创建图标很简单
(1) 必须在home 文件夹下或其子文件夹中进行,在其他磁盘是创建不成功的;
比如 :在JAVA文件下 :注意 没有 sudo ,不然不会成功的;
yuan@LABELNET:~/Java$ gedit eclipse.desktop(2) 编辑如下 :
#!/usr/bin/env xdg-open
[Desktop Entry]
Exec=/home/yuan/Java/android/eclipse/eclipse
Icon=/home/yuan/Java/android/eclipse/icon.xpm
Type=Application
Terminal=false
Name=lunaeclipse
GenericName=lunaeclipse
Categories=lunaeclipse
Name[en_US]=lunaeclipse
GenericName[en_US.UTF-8]=lunaeclipse
Name[zh_CN]=lunaeclipse含义 :

1.5 双击运行
点击 标记信任 就可以了,可以复制到桌面使用!
1.6 配置hadoop 插件
在刚才的专辑中下载 hadoop-eclipse 插件,将其复制到 eclipse - plugins 文件夹下

1.7 双击运行
打开map-reduce 面板:
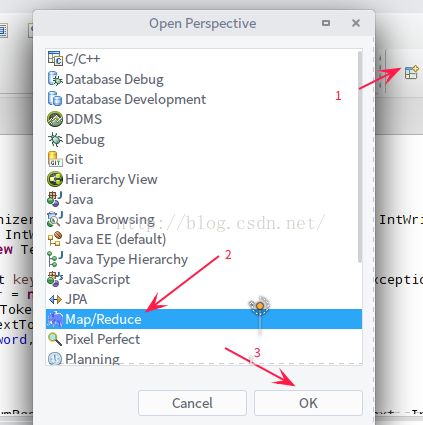
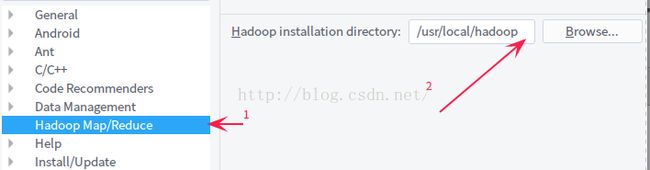
1.8 配置 hadoop 路径
配置hadoop 的安装路径,就是hadoop 的根路径;
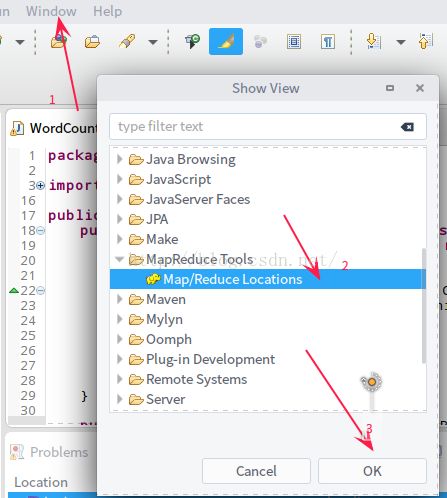
1.9 打开Map/Reduce Location
window - show View - MapReduce Tools
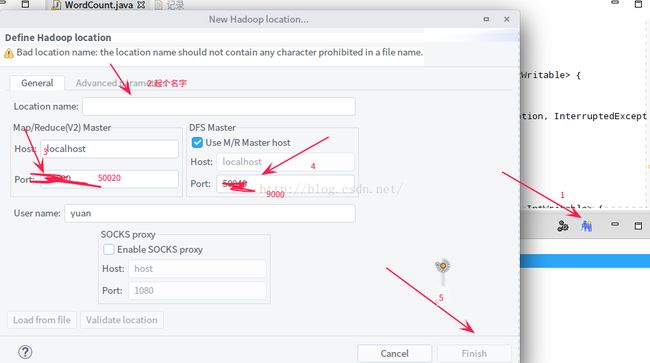
1.10 New Hadoop Location
50020 写错了 为 50070 ,其实就是 在配置 伪分布式的时候,配置的两个配置文件的端口号!!!
1.11 查看
点击的化,eclipse 可能提示报了一个错误,可以忽视他,点击左边 DFS Location :
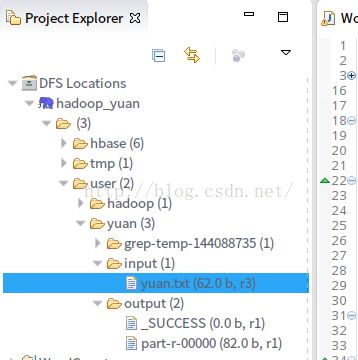
可以看见 user / hadoop 目录,这里的hbase 可以忽略,我安装过了,并且测试了,所有这里就有了;
2. 演示 WrodCount 示例
2.1 新建 map / reduce 工程
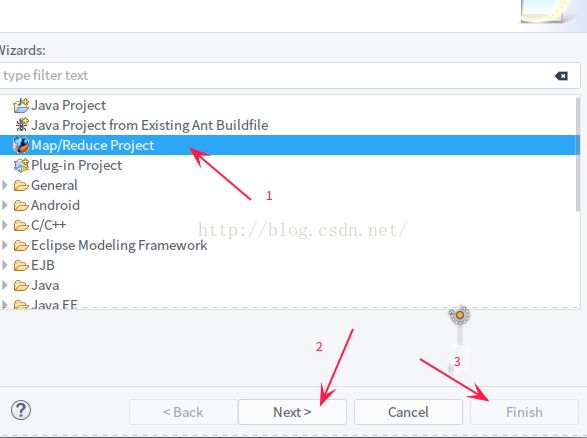
2.2 复制配置文件
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src2.3 复制分词源码
package cn.labelnet.wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 2.4 创建 input
2.5 运行
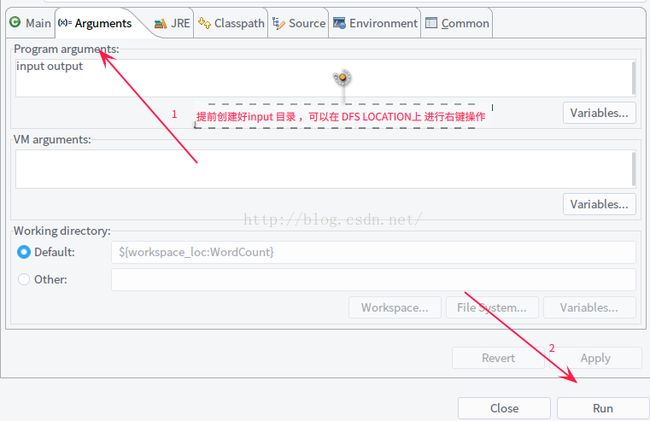
2.6 查看结果
在DFS LOCATION 上进行 刷新操作,查看 OutPut文件夹下 生成的文件,就可以了!
3.总结
下篇学习下 NameNode 的 RPC 的 通信原理;