使用Tensorflow hub迁移学习
- 使用TensorFlow Hub进行迁移学习
- 使用hub载入模型
- 指定模型训练
- 常用的图像签名
- 指定签名
- 使用总结
- 签名指定
- 图像输入
使用TensorFlow Hub进行迁移学习
首先安装tensorflow hub,确保tensorflow版本1.7及以上,具体细节查看image_retrain
在tensorflow的 github中主要给出了使用已经存在的训练网络模型inceptionv3训练自己的新的分类任务。主要有一点需要重点(Bottlenecks)说明:
Bottlenecks:在tensorflow hub中主要用来生成特征向量,它通常是网络最后一层的前一层,最后一层通常用来分类,而倒数第二层用来生成网络提取的特征向量。原始的retrain代码。
处理过程如下:
1. create_model_graph函数:通过tensorflow hub创建一个图,载入Hub models,返回载入后的图和bottleneck_tensor, resized_input_tensor, wants_quantization,实质上resized_input_tensor 代表输入,bottleneck_tensor代表输出wants_quantization 用于量化可以不必理会。
2. run_bottleneck_on_image将图像数据输入给上面的图,生成bottleneck_values,实际上相当于对输入的图像提取特征。
3. get_or_create_bottleneck读取数据生成数据的特征保bottleneck data存在磁盘上。(这个文件如果不存在就自己训练后写如文件,例子使用的是inceptionV3的文件)
4. add_final_retrain_ops 添加自己的层处理自己的问题,hub载入的模型是在imagenet上分类的模型,这类模型的输出和自己的任务的输出不一定一样,这时候我们需要改进最后一层(例子中问5类)通过前面bottleneck_tensor 的输出获取最后一层输入需要的信息,比如输入tensor的形状和bachsize,定义自己的层的W 和 b 经过softmax 输出,final_tensor ,同时加入ground_truth 表示输出的label用于计算损失,代码中加入了训练或者评估flag。
5. 余下的包含一些保存权重文件,评估,输出pb文件等等。
使用hub载入模型
module_spec = hub.load_module_spec(FLAGS.tfhub_module)
graph, bottleneck_tensor, resized_image_tensor, wants_quantization = (
create_module_graph(module_spec))这里的tfhub_module 就是https://tfhub.dev/google/imagenet/inception_v3/feature_vector/1' 你也可以加载对应的模型放在默认的/tmp 目录下,使用hub.load_module_spec(paths)' 既可以从本地载入(/tmp/tfhub_modules),也能从网上载入(例子中从网上直接载入)。
指定模型训练
下面开始使用官方的InceptionV3训练网络识别花。
python retrain.py --image_dir=flower_photos
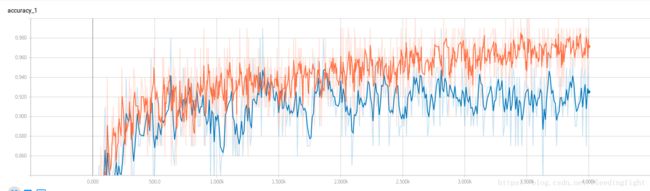
可以看到经过大约4000步,分类网络的精度就已经达到96%以上了。
如果你希望使用 其他的网络处理自己的分类问题,你可以在这里 下载你想使用的模型。下面我们使用Inception-ResNet V2进行训练。
只需要传入参数https://www.tensorflow.org/hub/modules/google/imagenet/inception_resnet_v2/feature_vector/1
python retrain.py --image_dir=flower_photos --tfhub_module=https://www.tensorflow.org/hub/modules/google/imagenet/inception_resnet_v2/feature_vector/1上面的模块的地址(如果是离线的只需要指定离线目录在系统中的位置即可)可以在模块详情找到。
常用的图像签名
一些模块可能用于多个人无,因此每个模块提供发布者命名的签名用于预期的任务,为他的它的主要任务设计输出output = m(images).
图像的特征向量是一个代表原图的1-D Tensor。不想CNN中的激活层,它不提供空间分解。不想图像分类,它丢弃了分类学习到的东西。
一个特征提取其有一个默认的签名映射图像的batch到batch的特征向量。使用如下:
# 载入发布则提供的模型
module_spec = hub.load_module_spec("path/to/module")
height, width = hub.get_expected_image_size(module_spec)
images = ... # A batch of images with shape [batch_size, height, width, 3].
module = hub.Module(module_spec)
features = module(images) # A batch with shape [batch_size, num_features].指定签名
# 指定签名用于提取特征向量
outputs = module(dict(images=images), signature="image_feature_vector",
as_dict=True)
features = outputs["default"]shush字典包含一个”default”的类型为float32,形状为[batch_size, num_features],batch_size
和输入相同,但是不知道图的结构。num_features 已知,如果要对模型进行droupout 这个操作应该留给用户而不是自己。输出字典提供了进一步输出,例如,模块中实际的隐藏层。特们的key和是独立于模型的。推荐使用架构-dependenct结构避免搞混中间层InceptionV3/Mixed_5c 表示的是架构InceptionV3的顶层卷积层Mixed_5c。
使用总结
模块的特征提取器用于映射batch的图像到batch的logits,可以按照如下使用:
module_spec = hub.load_module_spec("path/to/module")
height, width = hub.get_expected_image_size(module_spec)
images = ... # A batch of images with shape [batch_size, height, width, 3].
module = hub.Module(module_spec)
logits = module(images) # A batch with shape [batch_size, num_classes].签名指定
命名的特征提取器签名按下面的方式使用:
outputs = module(dict(images=images), signature="image_classification",
as_dict=True)
logits = outputs["default"]outputs["default"][i, c] 为类别中索引为c的成员i生成一个预测特分,它依赖于是否分类使用softmax打分,并和相应的函数对应。输出字典可以提供进一步的输出,例如,模块中隐藏层的激活。他们的keys和valuues是模块相关的。推荐按使用架构-dependent命名。
图像输入
一个签名接受batch的图像输入解码后的4-D float32,形状为[batch_size, height, width, 3] 的正则化到[0,1]的RGB像素图像。你可以使用tf.image.convert_image_dtype(..., tf.float32)处理[batch_size, height, width, 3] 得到。模型的用户不应该直接查看其形状,但是可以通过在模块或者模块spec调用hub.get_expected_image_size() 获取同时希望能对应的resize输入图像。,TFHUB默认的输入数据格式为[NCHW]