人脸检测 Retinaface - SSH部分(Single Stage Headless Face Detector)
人脸检测 Retinaface - SSH部分(Single Stage Headless Face Detector)
flyfish
论文地址
headless 翻译是无头的,咦,检测脸,怎么是无头呢?
Headless是移除分类网络的"head",也就是能够在去除其分类网络(即包含大量参数的VGG-16中的所有完全连接层)的“head”的同时获得最先进的结果。
Retinaface可以基于ResNet也可以基于mobilenet v1(0.25),这里是mobilenet v1
SSH(Single Stage Headless Face Detector)的框架

三个检测模块(detection module)
Detection Module M3 检测大脸
Detection Module M2 检测中脸
Detection Module M1 检测小脸
SSH改造的是VGG16
检测模块M1接在conv4_3上,并考虑与conv5_3的了feature map的融合。
检测模块M2接在conv5_3上
检测模块M3接在这样的新层,conv5-3上接一个最大池化,stride是32的新层
检测模块(Detection Module)由 classification 和 regression 构成
每个检测模块有不同尺度的K个 anchor
三个检测模块的anchor的计算方法请看
尺度不变的设计(Scale-Invariance Design)

这三个模块就是尺度不变的设计(Scale-Invariance Design),
SSH从三个不同的feature map上检测人脸,检测模块分别是M1,M2,M3。这三个模块对应的strides为8,16,32,分别用来检测小,中,大的脸。
借鉴的是FPN(Feature pyramid networks for object detection)
每个检测模块各自包含一个卷积二值分类器和为了检测人脸和定位人脸的回归器。
The detection module consists of a convolutional binary classifier and a regressor for detecting faces and localizing them respectively
上下文模块( Context Module)
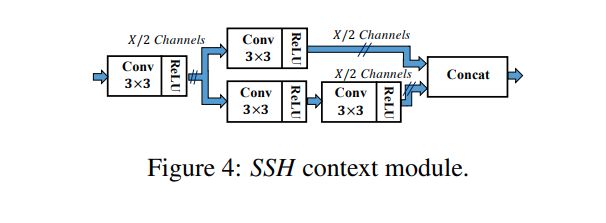
上下文模块中是采用5x5和7x7的卷积核。用这种方式对上下文进行建模增加了对应层的感受野,
与相应层的stride成正比,并因此与每个检测模块的目标尺度成比例,同时也增加了每个检测模块中的目标尺度。
为了减少模型参数量,使用类似mobilenet v1中的深度可分离卷积的方法,采用了3x3的卷积核代替5x5和7x7。
we use 5 × 5 and 7 × 7 filters in our context module. Modeling the context in this way increases the receptive field proportional to the stride of the corresponding layer and as a result the target scale of each detection module.
PyTorch实现
def conv_bn(inp, oup, stride = 1, leaky = 0):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.LeakyReLU(negative_slope=leaky, inplace=True)
)
def conv_bn_no_relu(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
)
class SSH(nn.Module):
def __init__(self, in_channel, out_channel):
super(SSH, self).__init__()
assert out_channel % 4 == 0
leaky = 0
if (out_channel <= 64):
leaky = 0.1
self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
def forward(self, input):
conv3X3 = self.conv3X3(input)
conv5X5_1 = self.conv5X5_1(input)
conv5X5 = self.conv5X5_2(conv5X5_1)
conv7X7_2 = self.conv7X7_2(conv5X5_1)
conv7X7 = self.conv7x7_3(conv7X7_2)
out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
out = F.relu(out)
return out
在RetinaFace中的使用
#SSH
feature1 = self.ssh1(fpn[0])
feature2 = self.ssh2(fpn[1])
feature3 = self.ssh3(fpn[2])
features = [feature1, feature2, feature3]
# feature1 torch.Size([32, 64, 80, 80])
# feature2 torch.Size([32, 64, 40, 40])
# feature3 torch.Size([32, 64, 20, 20])
输出
(ssh1): SSH(
(conv3X3): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv5X5_1): Sequential(
(0): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(conv5X5_2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv7X7_2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(conv7x7_3): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ssh2): SSH(
(conv3X3): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv5X5_1): Sequential(
(0): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(conv5X5_2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv7X7_2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(conv7x7_3): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(ssh3): SSH(
(conv3X3): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv5X5_1): Sequential(
(0): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(conv5X5_2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv7X7_2): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.1, inplace=True)
)
(conv7x7_3): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)