Flink源码解析(standalone)之jobmanager启动
一、启动从脚本开始
- 启动jobmanager会调用脚本jobmanager.sh start
- 从jobmanager.sh中知道,启动jobmanager最终调用的是flink-daemon.sh
if [[ $STARTSTOP == "start-foreground" ]]; then
exec "${FLINK_BIN_DIR}"/flink-console.sh $JOBMANAGER_TYPE "${args[@]}"
else
"${FLINK_BIN_DIR}"/flink-daemon.sh $STARTSTOP $JOBMANAGER_TYPE "${args[@]}"
fi
- 探索flink-daemon.sh得知,启动jobmanager时,调用的org.apache.flink.runtime.jobmanager.JobManager
case $DAEMON in
(jobmanager)
CLASS_TO_RUN=org.apache.flink.runtime.jobmanager.JobManager
;;
二、探索JobManager
- 1、进入JobManager的main方法,main中对启动线程运行runJobManager
SecurityUtils.getInstalledContext.runSecured(new Callable[Unit] {
override def call(): Unit = {
runJobManager(
configuration,
executionMode,
externalHostName,
portRange)
}
})
-
2、runJobManager逻辑:
1、根据port创建socket,找到可分配给jobmanager的port
2、调用重载方法runJobManager
def runJobManager(
configuration: Configuration,
executionMode: JobManagerMode,
listeningAddress: String,
listeningPortRange: java.util.Iterator[Integer])
: Unit = {
val result = AkkaUtils.retryOnBindException({
// Try all ports in the range until successful
val socket = NetUtils.createSocketFromPorts(
listeningPortRange,
new NetUtils.SocketFactory {
override def createSocket(port: Int): ServerSocket = new ServerSocket(
// Use the correct listening address, bound ports will only be
// detected later by Akka.
port, 0, InetAddress.getByName(NetUtils.getWildcardIPAddress))
})
val port =
if (socket == null) {
throw new BindException(s"Unable to allocate port for JobManager.")
} else {
try {
socket.getLocalPort()
} finally {
socket.close()
}
}
runJobManager(configuration, executionMode, listeningAddress, port)
}, { !listeningPortRange.hasNext }, 5000)
result match {
case scala.util.Failure(f) => throw f
case _ =>
}
}
- 3、创建了jobmanagerActorSystem(jobmanager与taskmanager是根据AkkaActor来通信)
val jobManagerSystem = startActorSystem(
configuration,
listeningAddress,
listeningPort)
- 4、创建并启动jobmanagerActor
val (jobManager, archive) = startJobManagerActors(
configuration,
jobManagerSystem,
futureExecutor,
ioExecutor,
highAvailabilityServices,
metricRegistry,
webMonitor.map(_.getRestAddress),
jobManagerClass,
archiveClass)
//进入startJobManagerActors,可见actor启动代码
val jobManager: ActorRef = jobManagerActorName match {
case Some(actorName) => actorSystem.actorOf(jobManagerProps, actorName)
case None => actorSystem.actorOf(jobManagerProps)
}
- 4.1根据startJobManagerActors方法参数:jobManagerClass(参数值:JobManager),找到jobmanagerActor生命周期方法(actor生命周期方法prestart、receive、postStop,其中postStop是actor停止时调用)
- 4.2进入jobManagerActor生命周期方法:preStart
- 4.2.1、启动leader选举服务,此处是standalone模式,直接赋予leader角色
leaderElectionService.start(this)
- 4.2.2 进入StandaloneLeaderElectionService.start,standalone模式,最终调用的jobmanager的grantLeadership方法
contender.grantLeadership(HighAvailabilityServices.DEFAULT_LEADER_ID);- 4.2.3 在grantLeadership中,调用了decorateMessage,通过match匹配,最终将消息GrantLeadership(leadersessionid)发送给jobmanagerActor
override def grantLeadership(newLeaderSessionID: UUID): Unit = {
self ! decorateMessage(GrantLeadership(Option(newLeaderSessionID)))
}
override def decorateMessage(message: Any): Any = {
message match {
case msg: RequiresLeaderSessionID =>
LeaderSessionMessage(leaderSessionID.orNull, super.decorateMessage(msg))
case msg => super.decorateMessage(msg)
}
}
4.2.4 jobmanagerActor接收到GrantLeadership消息后,将jobmanager赋予leader角色,如果jobmanager不是高可用模式,actor会在指定时间后调度一次,发送LeaderSessionMessage消息给LeaderSessionMessageFilterActor,在其receive方法中使用jobmanagerActor的handleMessage方法,来恢复所有的job任务。
//jobmanager.handleMessage
case GrantLeadership(newLeaderSessionID) =>
log.info(s"JobManager $getAddress was granted leadership with leader session ID " +
s"$newLeaderSessionID.")
//设置当前jobmanager为leader
leaderSessionID = newLeaderSessionID
// confirming the leader session ID might be blocking, thus do it in a future
future {
leaderElectionService.confirmLeaderSessionID(newLeaderSessionID.orNull)
// TODO (critical next step) This needs to be more flexible and robust (e.g. wait for task
// managers etc.)
if (haMode != HighAvailabilityMode.NONE) {
log.info(s"Delaying recovery of all jobs by $jobRecoveryTimeout.")
//在指定时间后调度一次
context.system.scheduler.scheduleOnce(
jobRecoveryTimeout,
self,
//调用方法后为:LeaderSessionMessage
decorateMessage(RecoverAllJobs))(
context.dispatcher)
}
}(context.dispatcher)
//LeaderSessionMessageFilter.receive
abstract override def receive: Receive = {
case leaderMessage @ LeaderSessionMessage(msgID, msg) =>
leaderSessionID match {
case Some(leaderId) =>
if (leaderId.equals(msgID)) {
//进入jobmanager.handleMessage
super.receive(msg)
} else {
handleDiscardedMessage(leaderId, leaderMessage)
}
case None =>
handleNoLeaderId(leaderMessage)
}
case msg: RequiresLeaderSessionID =>
throw new Exception(s"Received a message $msg without a leader session ID, even though" +
s" the message requires a leader session ID.")
case msg =>
super.receive(msg)
}
//jobmanager.handleMessage,恢复job任务
case RecoverAllJobs =>
future {
log.info("Attempting to recover all jobs.")
try {
val jobIdsToRecover = submittedJobGraphs.getJobIds().asScala
if (jobIdsToRecover.isEmpty) {
log.info("There are no jobs to recover.")
} else {
log.info(s"There are ${jobIdsToRecover.size} jobs to recover. Starting the job " +
s"recovery.")
jobIdsToRecover foreach {
//依次恢复job
jobId => self ! decorateMessage(RecoverJob(jobId))
}
}
} catch {
case e: Exception => {
log.error("Failed to recover job ids from submitted job graph store. Aborting " +
"recovery.", e)
// stop one self in order to be restarted and trying to recover the jobs again
context.stop(self)
}
}
}(context.dispatcher)
4.2.5 依次恢复job
case RecoverJob(jobId) =>
future {
try {
// The ActorRef, which is part of the submitted job graph can only be
// de-serialized in the scope of an actor system.
akka.serialization.JavaSerializer.currentSystem.withValue(
context.system.asInstanceOf[ExtendedActorSystem]) {
log.info(s"Attempting to recover job $jobId.")
val submittedJobGraphOption = submittedJobGraphs.recoverJobGraph(jobId)
Option(submittedJobGraphOption) match {
case Some(submittedJobGraph) =>
if (leaderSessionID.isEmpty ||
!leaderElectionService.hasLeadership(leaderSessionID.get)) {
// we've lost leadership. mission: abort.
log.warn(s"Lost leadership during recovery. Aborting recovery of $jobId.")
} else {
//根据jobGraph重新提交job
self ! decorateMessage(RecoverSubmittedJob(submittedJobGraph))
}
case None => log.info(s"Attempted to recover job $jobId, but no job graph found.")
}
}
} catch {
case t: Throwable => {
log.error(s"Failed to recover job $jobId.", t)
// stop one self in order to be restarted and trying to recover the jobs again
context.stop(self)
}
}
}(context.dispatcher)
4.2.6 重新提交job,具体的提交流程再任务提交时再说
case RecoverSubmittedJob(submittedJobGraph) =>
if (!currentJobs.contains(submittedJobGraph.getJobId)) {
log.info(s"Submitting recovered job ${submittedJobGraph.getJobId}.")
//提交job
submitJob(
submittedJobGraph.getJobGraph(),
submittedJobGraph.getJobInfo(),
isRecovery = true)
}
else {
log.info(s"Ignoring job recovery for ${submittedJobGraph.getJobId}, " +
s"because it is already submitted.")
}
- 4.2.7JobManager的生命周期方法:handleMessage(用于通信)
- 5、启动一个jobmanager进程监视器,如果jobmanager死亡,则终止其JVM进程
jobManagerSystem.actorOf(
Props(
classOf[ProcessReaper],
jobManager,
LOG.logger,
RUNTIME_FAILURE_RETURN_CODE),
"JobManager_Process_Reaper")
- 6、如果允许模式为LOCAL,则启动一个内嵌的taskmanager
TaskManager.startTaskManagerComponentsAndActor
def startTaskManagerComponentsAndActor(
configuration: Configuration,
resourceID: ResourceID,
actorSystem: ActorSystem,
highAvailabilityServices: HighAvailabilityServices,
metricRegistry: FlinkMetricRegistry,
taskManagerHostname: String,
taskManagerActorName: Option[String],
localTaskManagerCommunication: Boolean,
taskManagerClass: Class[_ <: TaskManager])
: ActorRef = {
val taskManagerAddress = InetAddress.getByName(taskManagerHostname)
val taskManagerServicesConfiguration = TaskManagerServicesConfiguration
.fromConfiguration(configuration, taskManagerAddress, false)
val taskManagerConfiguration = TaskManagerConfiguration.fromConfiguration(configuration)
val taskManagerServices = TaskManagerServices.fromConfiguration(
taskManagerServicesConfiguration,
resourceID,
actorSystem.dispatcher,
EnvironmentInformation.getSizeOfFreeHeapMemoryWithDefrag,
EnvironmentInformation.getMaxJvmHeapMemory)
val taskManagerMetricGroup = MetricUtils.instantiateTaskManagerMetricGroup(
metricRegistry,
taskManagerServices.getTaskManagerLocation(),
taskManagerServices.getNetworkEnvironment())
// create the actor properties (which define the actor constructor parameters)
val tmProps = getTaskManagerProps(
taskManagerClass,
taskManagerConfiguration,
resourceID,
taskManagerServices.getTaskManagerLocation(),
taskManagerServices.getMemoryManager(),
taskManagerServices.getIOManager(),
taskManagerServices.getNetworkEnvironment(),
taskManagerServices.getTaskManagerStateStore(),
highAvailabilityServices,
taskManagerMetricGroup)
taskManagerActorName match {
case Some(actorName) => actorSystem.actorOf(tmProps, actorName)
case None => actorSystem.actorOf(tmProps)
}
}
- 6.1 进入taskmanager的prestart方法,用于检索jobmanager leader角色的检索器启动
protected val leaderRetrievalService: LeaderRetrievalService = highAvailabilityServices.
getJobManagerLeaderRetriever(
HighAvailabilityServices.DEFAULT_JOB_ID)
leaderRetrievalService.start(this)
- 6.2、进入highAvailabilityServices子类StandaloneHaServices的getJobManagerLeaderRetriever方法,可知最终是调用的StandaloneLeaderRetrievalService类的start方法
public LeaderRetrievalService getJobManagerLeaderRetriever(JobID jobID) {
synchronized (lock) {
checkNotShutdown();
return new StandaloneLeaderRetrievalService(jobManagerAddress, DEFAULT_LEADER_ID);
}
}
- 6.3、 因为是Local模式,我们知道本机就是jobmanager,所以直接通知监听器,因为我们已经知道了前导JobManager的地址
public void start(LeaderRetrievalListener listener) {
checkNotNull(listener, "Listener must not be null.");
synchronized (startStopLock) {
checkState(!started, "StandaloneLeaderRetrievalService can only be started once.");
started = true;
// directly notify the listener, because we already know the leading JobManager's address
listener.notifyLeaderAddress(leaderAddress, leaderId);
}
}
- 6.4 再次到taskmanager,查看notifyLeaderAddress方法逻辑发现给taskmanagerActor发送了一个JobManagerLeaderAddress消息
override def notifyLeaderAddress(leaderAddress: String, leaderSessionID: UUID): Unit = {
self ! JobManagerLeaderAddress(leaderAddress, leaderSessionID)
}
- 6.5 进入生命周期方法handleMessage,找到JobManagerLeaderAddress
case JobManagerLeaderAddress(address, newLeaderSessionID) =>
handleJobManagerLeaderAddress(address, newLeaderSessionID)
- 6.6 在handleJobManagerLeaderAddress中主要做了下面几件事
- 6.6.1 如果taksmanager中已经存储的有jobmanager leader的地址,则需要断开与旧的leader jobmanager的连接,让其失效
currentJobManager match {
case Some(jm) =>
Option(newJobManagerAkkaURL) match {
case Some(newJMAkkaURL) =>
handleJobManagerDisconnect(s"JobManager $newJMAkkaURL was elected as leader.")
case None =>
handleJobManagerDisconnect(s"Old JobManager lost its leadership.")
}
case None =>
}
- 6.6.2 taskmanager注册到新的leader jobmanager中
this.jobManagerAkkaURL = Option(newJobManagerAkkaURL)
this.leaderSessionID = Option(leaderSessionID)
if (this.leaderSessionID.isDefined) {
// only trigger the registration if we have obtained a valid leader id (!= null)
triggerTaskManagerRegistration()
}
}
- 6.6.3 发送消息给taskmanagerActor启动注册流程,因为TriggerTaskManagerRegistration继承了RegistrationMessage,可通过RegistrationMessage在handleMessage生命周期方法中找到对应处理逻辑
self ! decorateMessage(
TriggerTaskManagerRegistration(
jobManagerAkkaURL.get,
new FiniteDuration(
config.getInitialRegistrationPause().getSize(),
config.getInitialRegistrationPause().getUnit()),
deadline,
1,
currentRegistrationRun)
)
- 6.6.4 taskmanager注册,至于jobmanager接收到消息后如何处理,这里先不讲,等在standalone模式的taskmanager启动时再讲
jobManager ! decorateMessage(
RegisterTaskManager(
resourceID,
location,
resources,
numberOfSlots)
)
- 7、启动一个taskmanager进程监视器,如果taskmanager挂掉,则终止其JVM进程
jobManagerSystem.actorOf(
Props(
classOf[ProcessReaper],
taskManagerActor,
LOG.logger,
RUNTIME_FAILURE_RETURN_CODE),
"TaskManager_Process_Reaper")
8、启动webmonitor
webMonitor.foreach {
_.start()
}
9、启动resourceManager
val resourceManager =
resourceManagerClass match {
case Some(rmClass) =>
LOG.debug("Starting Resource manager actor")
Option(
FlinkResourceManager.startResourceManagerActors(
configuration,
jobManagerSystem,
highAvailabilityServices.getJobManagerLeaderRetriever(
HighAvailabilityServices.DEFAULT_JOB_ID),
rmClass))
case None =>
LOG.info("Resource Manager class not provided. No resource manager will be started.")
None
}
9.1 方法里面没有什么特别的,直接就是启动resourceManagerActor,直接看StandaloneResourceManager生命周期方法prestart和receive
val resourceManager =
resourceManagerClass match {
case Some(rmClass) =>
LOG.debug("Starting Resource manager actor")
Option(
FlinkResourceManager.startResourceManagerActors(
configuration,
jobManagerSystem,
highAvailabilityServices.getJobManagerLeaderRetriever(
HighAvailabilityServices.DEFAULT_JOB_ID),
rmClass))
case None =>
LOG.info("Resource Manager class not provided. No resource manager will be started.")
None
}
9.1.1 进入FlinkResourceManager的preStart, 检测leader jobmanager变化的服务启动,最终调用LeaderRetrievalListener的notifyLeaderAddress,可见发送了NewLeaderAvailable消息给FlinkResourceManagerActor
leaderRetriever.start(new LeaderRetrievalListener() {
@Override
public void notifyLeaderAddress(String leaderAddress, UUID leaderSessionID) {
self().tell(
new NewLeaderAvailable(leaderAddress, leaderSessionID),
ActorRef.noSender());
}
@Override
public void handleError(Exception e) {
self().tell(
new FatalErrorOccurred("Leader retrieval service failed", e),
ActorRef.noSender());
}
});
9.1.2 我们进入handleMessage方法里面,看下接收到FlinkResourceManagerActor消息后,调用了newJobManagerLeaderAvailable,在这里面首先与当前的leader jobmanager取消连接,然后去leader jobmanager上去注册resourceManager
else if (message instanceof NewLeaderAvailable) {
NewLeaderAvailable msg = (NewLeaderAvailable) message;
newJobManagerLeaderAvailable(msg.leaderAddress(), msg.leaderSessionId());
}
private void newJobManagerLeaderAvailable(String leaderAddress, UUID leaderSessionID) {
LOG.debug("Received new leading JobManager {}. Connecting.", leaderAddress);
//与当前的leader jobmanager取消关联
jobManagerLostLeadership();
if (leaderSessionID != null && leaderAddress != null) {
this.leaderSessionID = leaderSessionID;
//连接到jobmanager,并注册
triggerConnectingToJobManager(leaderAddress);
}
}
9.1.3 我们看下triggerConnectingToJobManager具体逻辑
9.1.3.1 首先去jobmanager注册(注意:这里发送消息是同步的,会一直等待jobmanager回消息才会往下运行)
final Object registerMessage = decorateMessage(new RegisterResourceManager(self()));
final Object retryMessage = decorateMessage(new TriggerRegistrationAtJobManager(leaderAddress));
// send the registration message to the JobManager
ActorSelection jobManagerSel = context().actorSelection(leaderAddress);
//去注册,并等待返回结果
Future9.1.3.2 jobmanager接收到resourcemanager注册消息,首先会被LeaderSessionMessageFilter(jobmanager继承了LeaderSessionMessageFilter)的生命周期方法receive接收到,然后会调用jobmanager的receive方法(也就是handleMessage方法),接收到注册消息后,jobmanager首先会讲该resourcemanager设置为当前的资源管理器,然后会将在jobmanager上面已经注册过的taskmanager发送给resourcemanagerActor,并告知注册成功
case msg: RegisterResourceManager =>
log.debug(s"Resource manager registration: $msg")
// ditch current resource manager (if any)
currentResourceManager = Option(msg.resourceManager())
currentResourceManagerConnectionId += 1
val taskManagerResources = instanceManager.getAllRegisteredInstances.asScala.map(
instance => instance.getTaskManagerID).toList.asJava
// confirm registration and send known task managers with their resource ids
sender ! decorateMessage(new RegisterResourceManagerSuccessful(self, taskManagerResources))
9.1.4 接收到注册成功消息后,会运行下面逻辑,直接将消息发送给了resourcemanagerActor
if (msg instanceof LeaderSessionMessage &&
((LeaderSessionMessage) msg).message() instanceof RegisterResourceManagerSuccessful) {
self().tell(msg, ActorRef.noSender());
}
9.1.5 在resourceManager的handleMessage方法中
1.从jobmanager返回的taskmanager列表中筛选出resourcemanager确认处于启动状态的taskmanager
2.检测worker是否够用
else if (message instanceof RegisterResourceManagerSuccessful) {
RegisterResourceManagerSuccessful msg = (RegisterResourceManagerSuccessful) message;
jobManagerLeaderConnected(msg.jobManager(), msg.currentlyRegisteredTaskManagers());
}
private void jobManagerLeaderConnected(
ActorRef newJobManagerLeader,
Collection workers) {
if (jobManager == null) {
LOG.info("Resource Manager associating with leading JobManager {} - leader session {}",
newJobManagerLeader, leaderSessionID);
jobManager = newJobManagerLeader;
if (workers.size() > 0) {
LOG.info("Received TaskManagers that were registered at the leader JobManager. " +
"Trying to consolidate.");
// keep track of which TaskManagers are not handled
Set toHandle = new HashSet<>(workers.size());
toHandle.addAll(workers);
try {
// ask the framework to tell us which ones we should keep for now
Collection consolidated = reacceptRegisteredWorkers(workers);
LOG.info("Consolidated {} TaskManagers", consolidated.size());
// put the consolidated TaskManagers into our bookkeeping
for (WorkerType worker : consolidated) {
ResourceID resourceID = worker.getResourceID();
startedWorkers.put(resourceID, worker);
toHandle.remove(resourceID);
}
}
catch (Throwable t) {
LOG.error("Error during consolidation of known TaskManagers", t);
// the framework should release the remaining unclear resources
for (ResourceID id : toHandle) {
releasePendingWorker(id);
}
}
}
// trigger initial check for requesting new workers
checkWorkersPool();
} else {
String msg = "Attempting to associate with new JobManager leader " + newJobManagerLeader
+ " without previously disassociating from current leader " + jobManager;
fatalError(msg, new Exception(msg));
}
}
附上时序图:
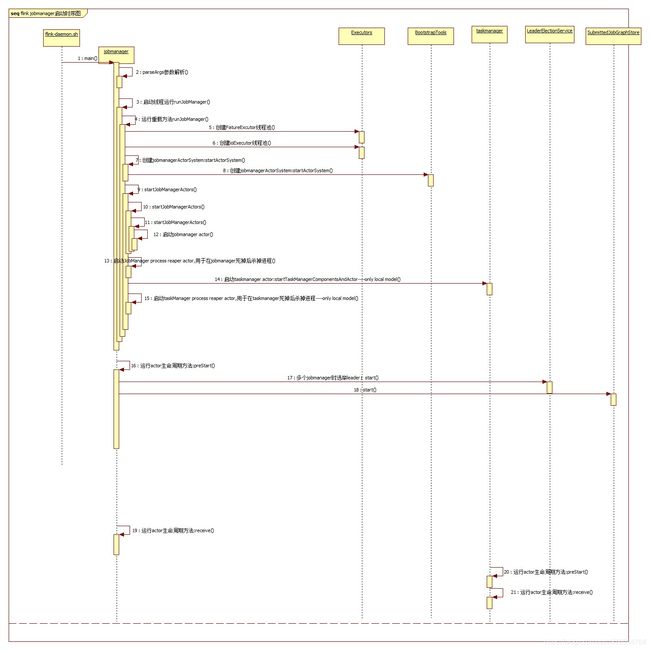
注:第一次写博客,有不完善或者不正确的地方欢迎指导补充