用树莓派打造自己的对话式智能家居控制中心——Hi,Messy(二)
日常前言
项目教程目录:https://blog.csdn.net/qq_41082014/article/details/86605663
第一篇的唤醒相信度娘搜一下关键词snowboy都能出现与之相似的内容,但是能度娘到的关于snowboy的信息也仅限与此,相信很多人和我当初一样,虽然能唤醒了,但是做不了更多的事情,比如唤醒之后想录个音,或者用pygame、mplayer这样的工具放首歌,snowboy都会直接终止进程,报错无设备,必须要重启才能解决。

So,作为Hi,Messy的第二篇文章,便来出手解决这个问题
先找官方
官方文档
官方文档地址,一圈搜罗后,官方文档只介绍了如何进行单次唤醒和怎么使用它们的webapi,没什么用。
官方demo
那官方文档里找不到,记得官方的资源里面好像有几个demo,去看看呢。诶,果真就在demo里面发现了官方写的录音的代码,下图是官方介绍

核心代码如下,官方是使用的speech_recognition这么一个库,然后用内置的谷歌的语音识别api进行识别。亲自上手后发现,这个库录音的数据类型是库自己定义的
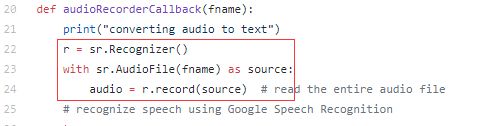

detector.start的参数audio_recorder_callback的官方定义是当触发唤醒词后,保存后续的短语,偶然间发现,他是能保存录音文件,再看看官方demo,发现官方的demo是在使用speech_recognition后又把这个文件给删除了,醉了。本来以为到这里就可以结束了,但后面又发现,只能指定一个时间进行录音,功能太局限,所以,直接放弃官方,自寻出路!

定制开始
好了,前面写了那么多,我只是想把过程给记录下来,让童鞋们少走弯路。接下来,正片开始。
先把我们需要的文件从官方里拷出来,一共5个文件,一个文件夹。拷完之后,git下来的snowboy这个文件夹就可以删除了。
cp yuyin/snowboy/examples/Python3/snowboydetect.py yuyin/alexa/
cp yuyin/snowboy/resources/alexa/alexa-avs-sample-app/alexa.umdl yuyin/alexa/
cp yuyin/snowboy/examples/Python3/demo.py yuyin/alexa/alexa.py
cp -r yuyin/snowboy/resources yuyin/alexa/func_alexa
cp yuyin/snowboy/swig/Python3/_snowboydetect.so yuyin/alexa/func_alexa
cp yuyin/snowboy/swig/Python3/snowboydecoder.py yuyin/alexa/func_alexa
先把目录结构建起来,最终效果如下图(如有不知道的目录,手动建一下,后续需要使用)
- 根目录

- music_messy

定制灵魂功能
铺垫了这么多,终于来到了最关键的步骤,唤醒后,录制一段音频。前面说过了,只录音的功能太过局限,所以接下来,我们要做的是可不止录音这么简单
- 代码结构阐述
- 进入第一个循环,根据当前环境的音量是否高于阈值(判断是否有声音输入)
- 若有,进入第二个循环,判断当前环境的音量是否低于阈值(判断录入是否结束),若低于,则两个循环都结束
- 若第一个循环进行5s后,依然无声音输入,则循环结束(判断超时)
开锤代码
核心功能:判断声音大小
# func_messy/volume.py
import pyaudio
import numpy as np
# 定义录制声音的参数
CHUNK = 180
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
def volume():
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
while 1:
for i in range(0, 100):
data = stream.read(CHUNK)
audio_data = np.fromstring(data, dtype=np.short)
temp = np.max(audio_data)
print(temp)
volume_detection()
这个可以直接在本地pc跑下试试,一般来说 0-500 就是正常的环境声音数值,500-1w 就是有人说话的数值了,1w以上基本就是和麦克风嘴对嘴讲话了![]() (录音文件的完整代码查看GIT [ 完整功能:
(录音文件的完整代码查看GIT [ 完整功能:代码结构阐述和最终保存录音文件]

调用录音功能,重头戏来了!!!
我们复制过来的demo中有这样一段代码,我们在这里调用方法进行替换
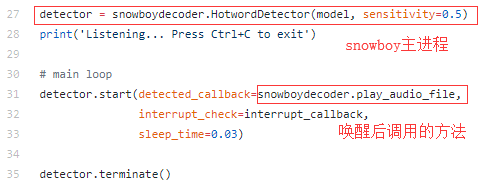
# alexa.py
import volume
detector = snowboydecoder.HotwordDetector(model, sensitivity=0.5)
def main():
detector.terminate()
volume.volume()
detector.start(detected_callback=main,
interrupt_check=interrupt_callback,
sleep_time=0.03)
detector.terminate()
注意到第五行的detector.terminate()了吗,这是snowboy官方定义的结束唤醒程序的函数(snowboydecoder.py的最后),该条代码很重要,因为snowboy已经在内部使用pyaudio库,如果这时在手动调用pyaudio,会造成三种情况:
- 一:录下来的文件没有声音
- 二:系统直接提示未知的媒体设备(Device unavailable)
- 三:snowboy程序被挤掉,系统提示无媒体设备(No available audio device)
当detector.start的循环被终止的时候,可以看到,接下去的一句就是使用这个函数来终止整个程序。但是,这么重要的一个函数,度娘完全没有搜到过,就连官方自己都没说,还是最后查阅源码文件才知道的…
再次唤醒
python3 alexa.py alexa.umdl
如果直接用的我的GIT上的项目代码的话,应该是可以看到在music_messy/said/看到i_said.wav这个文件,打开即可听到自己的声音咯
最后
在码代码的过程中还是会经常出现Device unavailable的错误,只好把需要用到媒体设备的代码全部放到不报错的地方。后来知道是pulseaudio没有启动的问题,但我一直启动不了这个东西

如果有大佬知道,可以评论一下或者加q群q我(576072252),谢谢
本文作者: Messy
原文链接:https://www.messys.top/detail/24
版权声明: 本博客所有文章除特别声明外, 均采用 CC BY-NC-SA 4.0 许可协议. 转载请注明出处!