需求
上周五产品提了一个需求,内容大致是: 统计当月某个时间段的数据,按公司统计。而我了解后得知这个表涉及的功能长年以来都被抱怨经常提示服务器错误,或者查询极慢!
内容分析
简单地在从库查了下,该表目前为SaaS类型的客户副订单表,千万行数据32个字段,索引没有规划过的迹象,(状态、小范围字段等都加上了索引,了解过B-tree原理的朋友应该知道这样几乎是没有意义的,甚至会拖后腿)。
- 索引比数据大
- 索引之间也没有关联性
- 使用select * 查,不做限制
很多小公司存在这种情况,数据不多情况下万事大吉,出问题后加机器,治标不治本
再分析
好了不多废话,报表的查询大概sql如下:
SELECT 公司id,sum(CEILING(字段1/60)) as sum,sum(字段2/60) as real_sum
FROM `table`
WHERE `公司id` IN (1,12,15,.....)
AND `add_time` > 1590940800 AND `add_time` < 1592755200
AND `status` < 3 AND `字段1` > 0 GROUP BY `公司id`(请忽略函数计算内容,懒得再写案例了,这就是我真实的案例)
这条sql最终查询了300s仍在执行,再等下去也没有意义,好好分析一下原因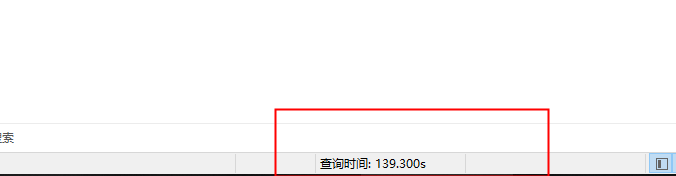
通常等待过长要么进行了全文搜索,要么做了错误的连接,如关联子查询等,这时候用执行计划EXPLAIN 关键字分析
EXPLAIN SELECT 公司id,sum(CEILING(字段1/60)) as sum,sum(字段2/60) as real_sum
FROM `table`
WHERE `公司id` IN (1,12,15,.....)
AND `add_time` > 1590940800 AND `add_time` < 1592755200
AND `status` < 3 AND `字段1` > 0 GROUP BY `公司id`结果如下
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtererd | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | ws_call_log | index | createdate,公司id,add_time_index | 公司id | 4 | null | 11121921 | 2.21 | Using where |
重点!
从计划任务看没啥大问题,该走索引的走索引,这时候注意key只使用一个索引:“公司id”,目前在库内的公司id大概200多个,换句话说如果在11121921行数据中找200行索引,在这个量级下作用是微乎其微的,所以我们在建索引的时候必须考虑实际业务情况
(至于怎么建有效的索引可以参考《高性能MySQL_第3版》),而这时的解决方法有两种
- 建一个 “公司id和add_time”的复合索引(最左匹配原则)
- 使用关键字force index 强制使用“公司id和add_time”的索引
这里我先使用force index,因为正常业务进行的生成环境下建立索引会使得整个表锁住,甚至会造成大量的sql等待表锁,有非常大的风险,所以建议修改索引尽量在流量少或者晚上业务少的时间段执行,避免不必要的影响
最终的sql为:
SELECT 公司id,sum(CEILING(字段1/60)) as sum,
sum(字段1/60) as real_sum FROM `table`
FORCE INDEX ( 公司id,add_time )
WHERE `公司id` IN (1,12,15,22,66,77,.....) AND
`add_time` > 1590940800 AND `add_time` < 1592755200
AND `status` < 3 AND `字段1` > 0 GROUP BY `公司id`EXPLAIN分析后,可以看到key使用了两个索引,最后执行的速度:5秒,当然还有其他的提升空间,不过提升空间不大,往后就是分区分表分库,换时序数据库等的事情了
