DStream
Spark DStreams
DStreams是什么?
是构建在Spark RDD之上的一款流处理工具。言外之意Spark DStream并不是严格意义的流处理。底层通过将RDD在时间轴上拆解成多个小的RDD-macro batch(构建在RDD之上的微批,严格意义上并不是真正的流),掺水了
流&批处理
| 计算类型 | 数据量级 | 计算延迟 | 输入数据 | 输出 | 计算形式 |
|---|---|---|---|---|---|
| 批处理 | MB=>GB=>TB | 几十分钟/几个小时 | 固定输入(全量) | 固定输出 | 最终终止 |
| 流处理 | Byte级别/记录级别 | 亚秒级延迟(Spark秒级,Storm毫秒级) | 持续输入(增量) | 持续输出 | 7*24小时 |
流处理框架:
一代:Kafka Streaming(构建在消息队列之上,工具级别)、
Storm(真正的实时流处理,延迟较低),自己没法进行状态管理,需要借助外围存储系统,吞吐量低(数据量的吞吐能力低,胃小)
二代?:Spark DStream(微批,不要说是流,实时性差【致命缺点】)
三代:Flink
由于DStream是构建在RDD之上,对习惯了批处理的工程师使用上比较友好。很多大数据工程师都有着MapReduce使用经验,如果使用批去模拟流,比较容易接受。同时DStream是构建在RDD(批处理)之上,因此在使用角度上讲,DStream操作流就好比在操作批处理。因此在使用难度上比Strom相对来说要简单。由于Spark框架的实现的核心是偏向批处理的,流处理只是从批中演变而来,因此DStream在做流处理的啥时候延迟较高。
前几年强调云计算Hadoop计算集群,Strom计算集群,强度云计算的实时性
现在雾计算(颗粒化计算),强调更好的实时性,在端进行计算
DStream原理(了解)
Discretized(离散) Streams (DStreams)在内部,它的工作原理如下。 Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理以批量生成最终结果流。

快速入门
- pom
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
- Driver
package com.baihzi.ds
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkDStreamHelloWorld {
def main(args: Array[String]): Unit = {
//1、创建StreamingContext
val sparkConf = new SparkConf()
.setMaster("local[5]")
.setAppName("HelloWord")
val ssc = new StreamingContext(sparkConf,Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志输出
//2、构建DStream对象 细化
val linesStream = ssc.socketTextStream("CentOS",9999)
//3、对数据流进行计算 marco-rdd 转换
linesStream.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.print()
//4启动计算
ssc.start()
ssc.awaitTermination()
}
}
- 启动网络服务
[root@CentOS ~]# yum install -y nc #安装 netcat
[root@CentOS ~]# nc -lk 9999
this is a demo this
this is a demo
this
程序结构
1、创建StreamingContext
2、指定流处理的数据源 #网络套接字(socket)-测试、文件系统-了解、kafka(必须掌握)、自定义Receiver-了解
3、对DStream做转换 #基本上和RDD转换保持一致
4、启动任务ssc.start
5、等待任务关闭 ssc.awaitTermination() //通过UI页面kill
Input DStreams 和 Receivers
Spark的每一个InputDstream对应一个Receiver实现(除文件系统输入流以外) ,每一个Receiver对象负责接受外围系统的数据,并且将数据存储到Spark的内存中(设置存储级别-内存、磁盘),也侧面反映了为什么说Spark DStream吞吐量比较大。
Spark提供了两种类型的输入源:
- Basic sources:file systems以及socket 连接,无需用户导入第三方包
- Advanced sources: spark本身不提供,需要导入第三方依赖,比如:Kafka
一般来说一个Receiver也需要消耗一个Core的计算资源,在运行Spark流计算的时候,一定要提前预留多一些Cores n, n> Receiver 个数
File Streams
以流的形式读取 静态资源文件,系统会尝试检测文件系统,一旦文件系统有新数据产生,系统会加载新文件-(仅仅加载一次)。
一定确保文件系统时间和计算节点时间保持同步。
val linesStream = ssc.textFileStream("hdfs://CentOS:9000/words")
linesStream.flatMap(_.split("\\s+")) //细化
.map((_,1))
.reduceByKey(_+_)
.print() //将计算结果打印
0.同步时钟
[root@CentOS ~]# date
[root@CentOS ~]# date -s ‘2019-09-28 11:35:25’[root@CentOS ~]# clock -w
1.先将需要采集的文件上传到HDFS的非采集目录
[root@CentOS ~]# hdfs dfs -put install.log /
2.将上传完成数据移动到采集目录
[root@CentOS ~]# hdfs dfs -mv /install.log /words
或者使用
val linesStream = ssc.fileStream[LongWritable,Text,TextInputFormat]("hdfs://CentOS:9000/words")
linesStream.flatMap(t=>t._2.toString.split("\\s+")) //细化
.map((_,1))
.reduceByKey(_+_)
.print() //将计算结果打印
Socket形式(测试)
val linesStream = ssc.socketTextStream("CentOS",9999)
Custom Receivers
package com.baihzi.customreceivers
import org.apache.spark.internal.Logging
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
import scala.util.Random
class CustomReciver(storageLevel: StorageLevel) extends Receiver[String](storageLevel :StorageLevel)with Logging{
override def onStart(): Unit = {
new Thread("Socket Receiver"){
override def run(): Unit = { receive()}
}.start()
}
override def onStop(): Unit = {
println("释放资源")
}
private def receive(){//负责从外围系统读取数据
val lines = List("this is a demo","hello word","good good study")
try{
var userInput:String = lines(new Random().nextInt(lines.size))
while (!isStopped() && userInput !=null){
store(userInput)//将获取的数据存储到Spark的内存中
Thread.sleep(800)
userInput = lines(new Random().nextInt(lines.size))
}
} catch {
case e: Exception =>
restart("Error connecting to", e)
}
}
}
val linesStream = ssc.receiverStream[String](new CustomReciver(StorageLevel.MEMORY_ONLY))
//3.对数据流进行计算 marco-rdd 转换
linesStream.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.print() //将计算结果打印
Spark 和Kafka整合(掌握)
[root@CentOS ~]# tar -zxf kafka_2.11-2.2.0.tgz -C /usr
[root@CentOS ~]# cd /usr/kafka_2.11-2.2.0/
[root@CentOS kafka_2.11-2.2.0]# vi config/server.properties
listeners=PLAINTEXT://CentOS:9092
log.dirs=/usr/kafka-logs
zookeeper.connect=CentOS:2181
#启动服务
[root@CentOS kafka_2.11-2.2.0]# bin/kafka-server-start.sh -daemon config/server.properties
#查看topic列表
[root@CentOS kafka_2.11-2.2.0]# bin/kafka-topics.sh --list --bootstrap-server CentOS:9092
#创建topic
[root@CentOS kafka_2.11-2.2.0]# bin/kafka-topics.sh --create --topic topic01 --partitions 1 --replication-factor 1 --bootstrap-server CentOS:9092
#发布消息
[root@CentOS kafka_2.11-2.2.0]# bin/kafka-console-producer.sh --topic topic01 --broker-list CentOS:9092
#订阅消息
[root@CentOS kafka_2.11-2.2.0]#
bin/kafka-console-consumer.sh --topic topic02 --bootstrap-server CentOSAA:9092,CentOSBB:9092,CentOSCC:9092 --property print.key=true --property print.value=true
参考:http://spark.apache.org/docs/latest/streaming-kafka-integration.html
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
spark-streaming-kafka-0-10兼容kafka-0.10+版本,由于Kafka-0.8版本和Kafka-0.10版本的消费者API发生了变化,原因是因为在Kafka-0.10+开始消费者支持分区的自动发现。
package com.baihzi.kafka
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkDStreamKafka {
def main(args: Array[String]): Unit = {
//1、创建StreamingContext
val sparkConf = new SparkConf()
.setMaster("local[5]")
.setAppName("HelloWord")
val ssc = new StreamingContext(sparkConf,Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志输出
//2、构建DStream对象
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "CentOS:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "g1",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Array[String]("topic01").toSet,kafkaParams)
)
.map(record=>(record.value()))
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKey(_+_)
.print()
//4启动计算
ssc.start()
ssc.awaitTermination()
}
}
流计算常见算子
由于Spark DStream算子和RDD的算子几乎是一模一样,所以具体的算子的使用大家参考RDD转换算子。
| Transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new “state” DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
countByValue
//this this is
ssc.socketTextStream("CentOS",9999)
.flatMap(_.split("\\s+"))
.countByValue()
.print()// this 2 is 1
join
//001 zhangsan
val userStream=ssc.socketTextStream("CentOS",9999)
.map(line=> line.split("\\s+"))
.map(ts=>(ts(0),ts(1)))
//001 apple
val orderStream=ssc.socketTextStream("CentOS",8888)
.map(line=> line.split("\\s+"))
.map(ts=>(ts(0),ts(1)))
userStream.join(orderStream)
.print()
一般很少使用,原因必须保证需要join的数据同时发送出去,才可能发生join。
transform(流到批的join)
ssc.socketTextStream("CentOS",9999)
.map(line=> line.split("\\s+"))
.map(ts=>(ts(0),ts(1)))
.transform(rdd=> rdd.leftOuterJoin(userRDD))
.map(t=>(t._1,t._2._1,t._2._2.getOrElse("未知")))
.print()
可以获取到DStream底层RDD对象,直接操作RDD算子。
其它算子使用细节参考:https://blog.csdn.net/weixin_38231448/article/details/89516569
状态计算
Spark提供了两个算子updateStateByKey(func)|mapWithState它们都可完成对(K,V)数据有状态计算-持续计算。
-
updateStateByKey(func)- 全量更新
package com.baihzi.status
import com.baihzi.customreceivers.CustomReciver
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*没更新的部分也会一起输出*/
object SparkDStreamUpdateStateByKey {
def main(args: Array[String]): Unit = {
//1、创建StreamingContext
val sparkConf = new SparkConf()
.setMaster("local[5]")
.setAppName("HelloWord")
val ssc = new StreamingContext(sparkConf,Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志输出
//2、构建DStream对象 细化
ssc.checkpoint("file:///E:/checkpoints")
ssc.socketTextStream("CentOS",9999)
//3、对数据流进行计算 marco-rdd 转换
.flatMap(_.split("\\s+"))
.map((_,1))
.updateStateByKey((vs:Seq[Int],state:Option[Int])=>{
Some(vs.fold(0)(_+_)+state.getOrElse(0))
})
.print()
//4启动计算
ssc.start()
ssc.awaitTermination()
}
}
-
mapWithState - 增量更新 √
package com.baihzi.status
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
object SparkDStreamMapWithSate {
def main(args: Array[String]): Unit = {
//1、创建StreamingContext
val sparkConf = new SparkConf()
.setMaster("local[5]")
.setAppName("HelloWord")
val ssc = new StreamingContext(sparkConf,Seconds(1))
ssc.sparkContext.setLogLevel("FATAL")//关闭日志输出
//2、构建DStream对象 细化
ssc.checkpoint("file:///E:/checkpoints")
ssc.socketTextStream("CentOS",9999)
//3、对数据流进行计算 marco-rdd 转换
.flatMap(_.split("\\s+"))
.map((_,1))
.mapWithState(StateSpec.function((k:String,v:Option[Int],s:State[Int])=>{
s.getOption().getOrElse(0)
(k,s.getOption().getOrElse(0))
}))
.print()
//4启动计算
ssc.start()
ssc.awaitTermination()
}
}
如果用户想使用这些有状态算子,必须给Spark设置checkpointdir,存储程序计算状态
-
故障恢复
Spark在第一次启动的的时候会尝试从checkpointDir进行恢复,该目录存储程序执行流程以及状态数据,如果有则直接从检查点自动恢复,否则执行()=>StreamingContex函数重新计算。(代码片段也会进行快照,以至于代码不能再更改)
package com.baihzi.status
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, State, StateSpec, StreamingContext}
object SparkDStreamRecover {
/*只输出更新的部分*/
def main(args: Array[String]): Unit = {
val checkpointDir = "file:///E:/checkpoints"
val ssc:StreamingContext = StreamingContext.getActiveOrCreate(checkpointDir, () => {
println("============================")
//1.创建StreamingContext
val sparkConf = new SparkConf().setMaster("local[5]").setAppName("HelloWorld")
var ssc = new StreamingContext(sparkConf, Seconds(1)) //1s一次微批
ssc.checkpoint(checkpointDir)
ssc.socketTextStream("CentOS", 9999)
.flatMap(_.split("\\s+"))
.map((_, 1))
.mapWithState(StateSpec.function((k: String, v: Option[Int], s: State[Int]) => {
val historyCount = s.getOption().getOrElse(0) //从历史状态中获取数据
s.update(historyCount + v.getOrElse(0)) //更新历史状态
(k, s.getOption().getOrElse(0))
}))
.print()
ssc
})
ssc
//4.启动计算
ssc.sparkContext.setLogLevel("FATAL")//关闭日志输出
ssc.start()
ssc.awaitTermination()
}
}
窗口计算(重点)
检测系统:仅仅是一种检测手段,可有可无(一分钟内一个行为的频率)
惩罚协调:
使用场景:实时的计算,某一个时间段的计量,电量,某个路口的拥堵程度(某讴歌时间段经过某个路口的车流量)
Spark Streaming支持针对某个时间窗内实现对数据计算,如下:
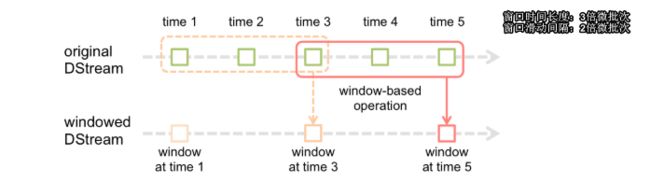
上图描绘的是 以3倍的微批次作为一个窗口长度,并且以2倍微批次作为滑动间隔。将落入到相同时间窗口的微批次合并成一个相对较大的微批次-窗口批次。
Spark要求所有的窗口长度以及滑动的间隔必须是微批次的整倍数
- 滑动窗口:窗口长度>滑动间隔 窗口与窗口之间存在元素的重叠
- 滚动窗口:窗口长度=滑动间隔 窗口与窗口之间没有元素的重叠
目前不存在 窗口长度 < 滑动间隔 这种窗口
Spark窗口计算的时间以计算节点的时间为准,本应该是数据的产生的时间
窗口计算时间属性:Event Time- 事件时间<Ingestion Time - 摄取时间<Processing Time -处理时间
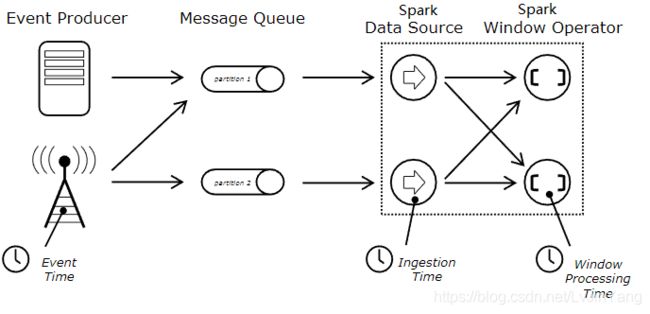
Spark DStreaming 目前仅仅支持 Processing Time -处理时间, 但是Spark的Structured Streaming 支持Event Time(后续讲解)
窗口算子
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上面的“reduceByKeyAndWindow()”的更有效版本,其中每个窗口的reduce值是使用前一个窗口的reduce值递增计算的。这是通过减少进入滑动窗口的新数据和“反向减少”离开窗口的旧数据来实现的。例如,当窗口滑动时,“加”和“减”键的计数。然而,它仅适用于“可逆的缩减函数”,即,那些具有相应的“逆减”函数的函数(作为参数ViFunc)。像在“reducebykeyandwindown”中一样,reduce任务的数量可以通过一个可选参数进行配置。请注意,必须启用[检查点](http://Skp.Apache .org/DOCS/最新/流编程指南.html检查点),以便使用此操作。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
window(windowLength, slideInterval)
package com.baihzi.dstreamwindow
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Milliseconds, Seconds, StreamingContext}
object DStreamWindow {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("windowWordCount").setMaster("local[6]")
val ssc = new StreamingContext(sparkConf,Milliseconds(100))
ssc.sparkContext.setLogLevel("FATAL")
ssc.socketTextStream("CentOS",9999,StorageLevel.MEMORY_AND_DISK_2)
.flatMap(_.split("\\s+"))
.map((_,1))
.window(Seconds(4),Seconds(2))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
以上window后可以更的算子:count、reduce、reduceByKey、countByValue为了方便起见Spark提供合成算子例如
window+count 等价于 countByWindow**(windowLength, slideInterval)、window+reduceByKey 等价 reduceByKeyAndWindow
reduceByKeyAndWindow
val sparkConf=new SparkConf().setAppName("WondowWordCount").setMaster("local[6]")
val ssc = new StreamingContext(sparkConf,Milliseconds(100))
ssc.sparkContext.setLogLevel("FATAL")
ssc.socketTextStream("CentOS",9999,StorageLevel.MEMORY_AND_DISK)
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKeyAndWindow((v1:Int,v2:Int)=>v1+v2,Seconds(4),Seconds(3))
.print()
ssc.start()
ssc.awaitTermination()
如果窗口重合过半,在计算窗口值的时候,可以使用下面方式计算结果
package com.baihzi.dstreamwindow
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Milliseconds, Seconds, StreamingContext}
object ReduceByKeyAndWindowBig {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("wordCount").setMaster("local[6]")
val ssc = new StreamingContext(sparkConf,Milliseconds(100))
ssc.sparkContext.setLogLevel("FATAL")
ssc.checkpoint("file:///E:/checkpoints")
ssc.socketTextStream("CentOS",9999,StorageLevel.MEMORY_AND_DISK)
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKeyAndWindow(//当窗口重叠 超过50% 使用一下计算效率较高
(v1:Int,v2:Int)=>v1+v2,//上一个窗口结果+新进来的元素
(v1:Int,v2:Int)=>v1+v2,//减去移出元素
Seconds(4),
Seconds(1),
filterFunc = (t)=>t._2>0
)
.print()
ssc.start()
ssc.awaitTermination()
}
}
DStreams输出
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
val sparkConf=new SparkConf().setAppName("WondowWordCount").setMaster("local[6]")
val ssc = new StreamingContext(sparkConf,Milliseconds(100))
ssc.sparkContext.setLogLevel("FATAL")
ssc.socketTextStream("CentOS",9999,StorageLevel.MEMORY_AND_DISK)
.flatMap(_.split("\\s+"))
.map((_,1))
.reduceByKeyAndWindow(
(v1:Int,v2:Int)=>v1+v2,//上一个窗口结果+新进来的元素
Seconds(60),
Seconds(1)
)
.filter(t=> t._2 > 10)
.foreachRDD(rdd=>{
rdd.foreachPartition(vs=>{
vs.foreach(v=>KafkaSink.send2Kafka(v._1,v._2.toString))
})
})
ssc.start()
ssc.awaitTermination()
object KafkaSink {
private def createKafkaProducer(): KafkaProducer[String, String] = {
val props = new Properties()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOS:9092")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
props.put(ProducerConfig.BATCH_SIZE_CONFIG,"10")
props.put(ProducerConfig.LINGER_MS_CONFIG,"1000")
new KafkaProducer[String,String](props)
}
val kafkaProducer:KafkaProducer[String,String]=createKafkaProducer()
def send2Kafka(k:String,v:String): Unit ={
val message = new ProducerRecord[String,String]("topic01",k,v)
kafkaProducer.send(message)
}
Runtime.getRuntime.addShutdownHook(new Thread(){
override def run(): Unit = {
kafkaProducer.flush()
kafkaProducer.close()
}
})
}
对于Spark而言,默认只有当窗口的时间结束之后才会将窗口的计算结果最终输出,通常将该种输出方式为
钳制输出形式。
VALUE_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
props.put(ProducerConfig.BATCH_SIZE_CONFIG,“10”)
props.put(ProducerConfig.LINGER_MS_CONFIG,“1000”)
new KafkaProducerString,String
}
val kafkaProducer:KafkaProducer[String,String]=createKafkaProducer()
def send2Kafka(k:String,v:String): Unit ={
val message = new ProducerRecordString,String
kafkaProducer.send(message)
}
Runtime.getRuntime.addShutdownHook(new Thread(){
override def run(): Unit = {
kafkaProducer.flush()
kafkaProducer.close()
}
})
}
> 对于Spark而言,默认只有当窗口的时间结束之后才会将窗口的计算结果最终输出,通常将该种输出方式为`钳制`输出形式。
使用场景:找不活跃用户,发优惠卷