Raft
Raft协议在nebula中的实现:
一个raft group中有三种类型节点:leader、follower、candidate(新增learner)。
简单来说,一个raft节点的组成如下图:
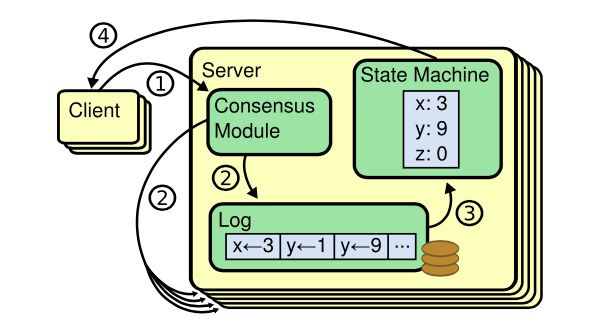
图1:raft节点组成
**Log entries:**日志中的每一个条目包含了一条指令,交给状态机执行。
**leader:**同一时刻raft group最多只有一个leader,负责接受client的写请求。
follower:每个节点的初始状态,接受leader或candidate的请求并响应。
candidate:触发选举条件时由follower过渡到leader的中间状态。
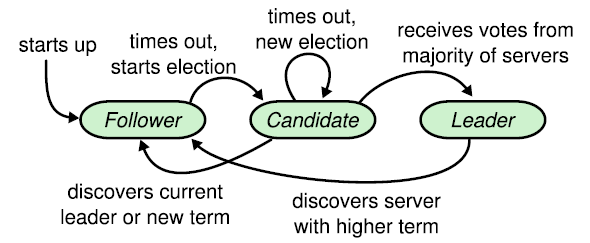
图2:Raft节点的转换过程
termID:全局的、连续递增的变量,标志集群在某个leader的任期号。
proposedTermID:一般情况下,proposedTermID等于termID,当一个节点成为candidate时,proposedTermID加1,用于表面自己的任期ID比其他节点更大,在遇到其他candidate时,更大的proposedTermID更具有选举的优先性。
election timeout:每个节点维护的一个变量,为一定范围内的随机数
选举定时器:当计时器从初始状态过了election timeout时间,该节点就会变成candidate,同时proposedTermID加1。
heartbeat:leader隔一段时间向follower发送的包,用于重置他们的选举定时器,维护自己的leader地位。
lastLogID:日志条目中最后一条日志的ID
lastLogTerm:日志条目中最后一条日志的所在的leader的Term
committedLogID:最大的被应用到状态机中的日志ID
领导人选举
当follower在election timeout时间内没有收到heartbeat时,将会自动触发选举过程:
1.proposedTerm加1,切换到candidate状态
2.给其他节点发送AskForVoteRequest并等待回复(如果只有自己一个节点则自动成为leader)
3.下面的代码片段说明了当一个节点收到AskForVoteRequest时,投票前先经过的判断条件,保证新的leader的日志是最新的,任期ID是最大的(至少对大部分节点来说)。
// 比较Vote请求的term和自身term(如果自己是candidate,则比较竞选的任期ID)
auto term = role_ == Role::CANDIDATE ? proposedTerm_ : term_;
if (req.get_term() <= term) {
VLOG(2) << idStr_
<< (role_ == Role::CANDIDATE
? "The partition is currently proposing term "
: "The partition currently is on term ")
<< term
<< ". The term proposed by the candidate is"
" no greater, so it will be rejected";
resp.set_error_code(cpp2::ErrorCode::E_TERM_OUT_OF_DATE);
return;
}
// 检查最后一条日志所在的leader的任期ID
if (req.get_last_log_term() < lastLogTerm_) {
VLOG(2) << idStr_
<< "The partition's last term to receive a log is "
<< lastLogTerm_
<< ", which is newer than the candidate's"
". So the candidate will be rejected";
resp.set_error_code(cpp2::ErrorCode::E_TERM_OUT_OF_DATE);
return;
}
if (req.get_last_log_term() == lastLogTerm_) {
// 如果上面都通过,则检查最后一条日志的ID
if (req.get_last_log_id() < lastLogId_) {
VLOG(2) << idStr_
<< "The partition's last log id is " << lastLogId_
<< ". The candidate's last log id is smaller"
", so it will be rejected";
resp.set_error_code(cpp2::ErrorCode::E_LOG_STALE);
return;
}
}
当收到的responses中票数不少于总节点半数时,成功当选leader。否则等待election timeout,发起新一轮选举,当然选举前proposedTerm加1。
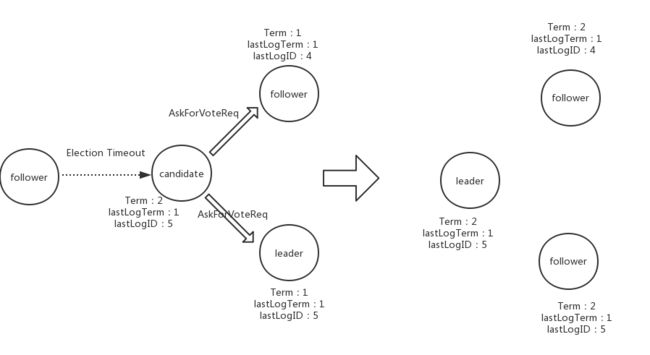
思考:
- 当出现两个candidate时,且他们的状态一样(term等),raft如何保证某一个节点只投给一个candidate呢?
先到者先得票,从上面代码片段的选举判断条件可以看出:当一个节点收到AskForVoteRequest时,如果判断条件通过并给他投票后,自身的term会更新(跟candidate的term保持一致)。
这样当后来的candidate发来请求时,根据判断条件 req.get_term() <= term 为false可知,该节点会reject该vote请求,因此这种情况下不会重复投票。
- 问题描述:参考GitHub Issue
初始集群中3个节点,A,B,C
A是leader,都接收了log 1
A网络故障,B成为leader,B,C接收log 2
B网络故障,集群中没有领导
A恢复,但是集群中将不会很快选出leader
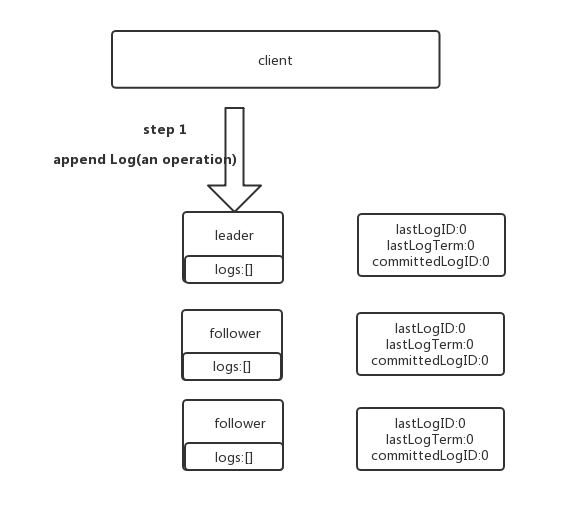
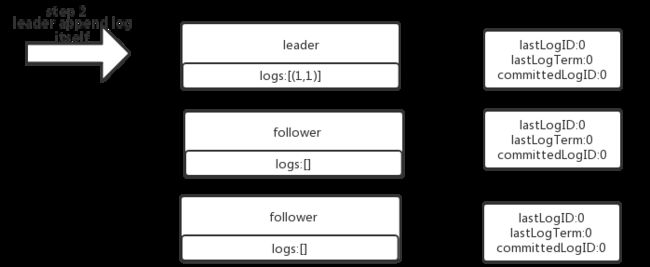
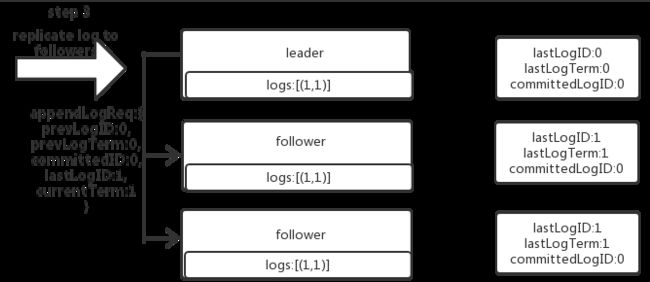
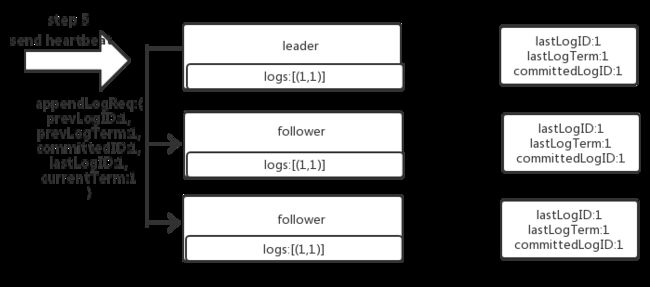
没有严格按照raft协议实现,导致bug。在raft原版论文中,一旦收到一个RPC(无论是request还是response),都会检查它携带的term,并与自身currentTerm比较,一旦自身currentTerm 假设日志表示方式如下: 一个标准的日志复制过程如下: 接着将日志复制给自己所在raft group中的其他成员,每个成员检查自己是否能追加日志: 如果日志有冲突:要么回滚,要么跟上leader的日志: 如果follower可以追加日志(leader的prevLog=follower的lastLog),则从当前lastLogID后开始追加发过来的所有日志: 最后,检查能否有可以提交的日志,能提交的则提交(当然第一次发过来appendLogRequest时,follower即使追加日志了,也没法提交) [外链图片转存中…(img-gk6oBrp8-1567145937346)] 日志复制流程图 **思考:**异常情况分析 1.图1 2.图2 3.raft 论文 4.nebula source code日志复制
logs:[(1,1),(2,1),(3,2)]
//每个pair的第一个元素代表该日志条目在日志中的索引,第二个元素标识它被创建时的领导人任期ID
// Check the last log
CHECK_GE(req.get_last_log_id_sent(), committedLogId_) << idStr_;
if (lastLogTerm_ > 0 && req.get_last_log_term_sent() != lastLogTerm_) {
VLOG(2) << idStr_ << "The local last log term is " << lastLogTerm_
<< ", which is different from the leader's prevLogTerm "
<< req.get_last_log_term_sent()
<< ". So need to rollback to last committedLogId_ " << committedLogId_;
wal_->rollbackToLog(committedLogId_);
lastLogId_ = wal_->lastLogId();
lastLogTerm_ = wal_->lastLogTerm();
resp.set_last_log_id(lastLogId_);
resp.set_last_log_term(lastLogTerm_);
resp.set_error_code(cpp2::ErrorCode::E_LOG_GAP);
return;
} else if (req.get_last_log_id_sent() > lastLogId_) {
// There is a gap
VLOG(2) << idStr_ << "Local is missing logs from id "
<< lastLogId_ << ". Need to catch up";
resp.set_error_code(cpp2::ErrorCode::E_LOG_GAP);
return;
} else if (req.get_last_log_id_sent() < lastLogId_) {
// Local has some extra logs, which need to be rolled back
wal_->rollbackToLog(req.get_last_log_id_sent());
lastLogId_ = wal_->lastLogId();
lastLogTerm_ = wal_->lastLogTerm();
resp.set_last_log_id(lastLogId_);
resp.set_last_log_term(lastLogTerm_);
}
// Append new logs
size_t numLogs = req.get_log_str_list().size();
LogID firstId = req.get_last_log_id_sent() + 1;
VLOG(2) << idStr_ << "Writing log [" << firstId
<< ", " << firstId + numLogs - 1 << "] to WAL";
LogStrListIterator iter(firstId,
req.get_log_term(),
req.get_log_str_list());
//从follower自己的lastLogID+1的位置开始,追加日志到WAL
if (wal_->appendLogs(iter)) {
CHECK_EQ(firstId + numLogs - 1, wal_->lastLogId());
lastLogId_ = wal_->lastLogId();
lastLogTerm_ = wal_->lastLogTerm();
resp.set_last_log_id(lastLogId_);
resp.set_last_log_term(lastLogTerm_);
} else {
LOG(ERROR) << idStr_ << "Failed to append logs to WAL";
resp.set_error_code(cpp2::ErrorCode::E_WAL_FAIL);
return;
}
// leader告诉follower:有新的日志可以commit(我已得到大多数成员的确认)了
if (req.get_committed_log_id() > committedLogId_) {
// 提交日志
// We can only commit logs from firstId to min(lastLogId_, leader's commit log id),
// follower can't always commit to leader's commit id because of lack of log
LogID lastLogIdCanCommit = std::min(lastLogId_, req.get_committed_log_id());
CHECK(committedLogId_ + 1 <= lastLogIdCanCommit);
if (commitLogs(wal_->iterator(committedLogId_ + 1, lastLogIdCanCommit))) {
VLOG(2) << idStr_ << "Follower succeeded committing log "
<< committedLogId_ + 1 << " to "
<< lastLogIdCanCommit;
committedLogId_ = lastLogIdCanCommit;
resp.set_committed_log_id(lastLogIdCanCommit);
} else {
LOG(ERROR) << idStr_ << "Failed to commit log "
<< committedLogId_ + 1 << " to "
<< req.get_committed_log_id();
resp.set_error_code(cpp2::ErrorCode::E_WAL_FAIL);
return;
}
}
参考: