用户画像第四章(企业级360°用户画像_标签开发_挖掘标签_用户购物性别模型-USG)
用户购物性别模型-USG
USG模型引入
USG(User Shopping Gender)
2.5.1.AI驱动的电商用户模型:性别属性是这样确定的
首先带领大家了解一下,如何通过大数据来确定用户的真实性别。
我们经常谈论的用户精细化运营,到底是什么?简单来讲,就是将网站的每个用户标签化,制作一个属于他自己的网络身份证。然后,运用人员通过身份证来确定活动的投放人群,圈定人群范围,更为精准的用户培养和管理。当然,身份证最基本的信息就是姓名,年龄和性别,与现实不同的是,网络上用户填写的资料不一定完全准确,还需要进行进一步的确认和评估。
确定性别这件事很重要,简单举个栗子,比如店铺想推荐新品的Bra,如果粗糙的全部投放人群或者投放到不准确性别的人群,那后果可想而知了。下面来介绍一下具体的识别思路

2.5.1.1.用户画像需要的数据
用户平时在电商网站的购物行为、浏览行为、搜索行为,以及订单购买情况都会被记录在案,探查其消费能力,兴趣等。数据归类后,一般来讲,可以通过三类数据对用户进行分群和定义。
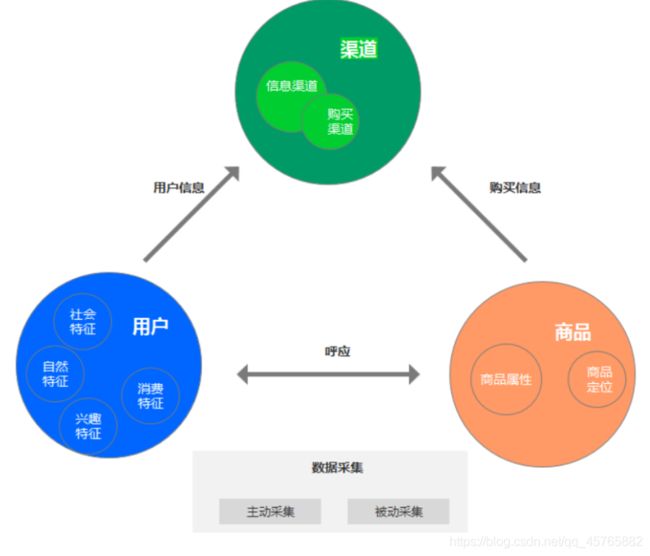
、用户信息
社会特征:马克思的人性观把人分为社会属性和自然属性。社会特征主要指的是人在社会上的阶级属性,当然也包括服从性、依赖性或者自觉性等,这是人类发展的必然的基本要求。
自然特征:也可以说成是人的生物性,通常来讲可以是食欲,物欲或者购买欲,自我保存能力。但不同人会有不同的自然特征,比如学习能力和逻辑思维等。
兴趣特征:对于电商来讲,主要是对某件商品,某个品牌或者品类的兴趣程度,如加购、浏览、收藏、搜索和下单行为。
消费特征:消费能力的评估,消费倾向的评估,能够判断用户的消费层级,是高消费力还是低消费力。
2、商品
商品属性:基本信息,品类,颜色尺码型号等。
商品定位:商品层级,是否为高中低端,商品类型倾向于哪类客户,区域或者其他的特征。
最后通过以上的信息来获取用户信息,判断其具体的画像特征,然后得到类似于酱紫的网络身份证。


业务目标: 精准投放:针对已有产品,寻找某性别偏好的精准人群进行广告投放。
技术目标: 对用户购物性别识别:男性,女性,中性
解决思路:选择一种分类算法,建立机器学习算法模型,对模型进行应用
线上投放:对得到的数据进行小范围内的测试投放,初期不宜过大扩大投放范围
效果分析:对投放的用户进行数据分析,评估数据的准确性。若不够完美,则需要重新建模和测试。
2.5.1.2.如何理解建模过程
重点来了,虽然能够通过用户的行为、购买和兴趣数据,了解用户的基本信息,但是仍然不清楚如何建模?用什么语言建模?其实,购物性别的区分使用的是spark,但是机器学习算法也有很多分类,包含逻辑回归,线性支持向量机,朴素贝叶斯模型和决策树。那么,又该如何选择呢?

构造决策树的步骤为:
通过训练数据来构建一棵用于分类的树,从而对未知数据进行高效分类。
以上步骤中,能够得出一个结论,在构建决策树的过程中,最重要的是如何找到最好的分割点。决策树值得注意的问题是过拟合问题,整个算法必须解决「如何停止分割」和「如何选择分割」两个关键问题。
2.5.1.2.模型确立过程
在建模前期,首要考虑的事情就是先确定指标,以及对样本的定义。购物性别指的是什么?通过哪些数据来确定购物性别,样本的准确性,如何验证数据的可信度等。
2.5.1.3.购物性别的定义
先看下图,具体的逻辑可从图中查看。一般来讲,用户填写的资料不一定真实,我们对他/她的性别数据持怀疑态度,所以,就需要其他数据进行辅助证明其性别。

根据数据结果,最终,确认了购物性别的定义。分为:
购物性别男:N月购买的男性特征类目子下单数> N月购买的女性特征类目子下单数
购物性别女:N月购买的男性特征类目子下单数> N月购买的女性特征类目子下单数
购物性别中性:未下单男女特征类目
N需要具体根据业务场景来定。
2.5.1.4.建模数据准备过程
本节是具体的操作过程,模型的实操阶段。一般来讲,不同模型的训练其实大体雷同。从技术上来讲,各家算法大多使用sparkmllib,不同点是所运算的模型都是针对于场景来定的。

在全部样本中,取80%的数据用于训练模型 在全部样本中,取20%的数据用户数据测试
2.5.1.5.模型效果分析
行业内当前采用数据挖掘、机器学习和推荐系统中的评测指标—准确率(Precision)、召回率(Recall),准确率是应用最广的数据指标,也很清晰易懂,以男性为例

准确率=命中的男性用户数量/所有预测男性数量,一般来讲,准确率可以评估模型的质量,他是很直观的数据评价,但并不是说准确度越高,算法越好。
召回率=命中的男性用户数量/所有男性数量,反映了被正确判定的正例占总的正例的比重。
模型建立完后,需根据模型的结果与预期的对比,进行调优。
2.5.1.6.最后要说的
购物性别定义对于用户精准营销十分重要,疑难杂症,对症下药,才能出现更好的疗效。
对于新手来说,初期一定是对模型性能及效果分析不是很熟练,可先用小数据量进行测试, 走通全流程 建表要规范,方便后期批量删除,因为建模是个反复的过程。
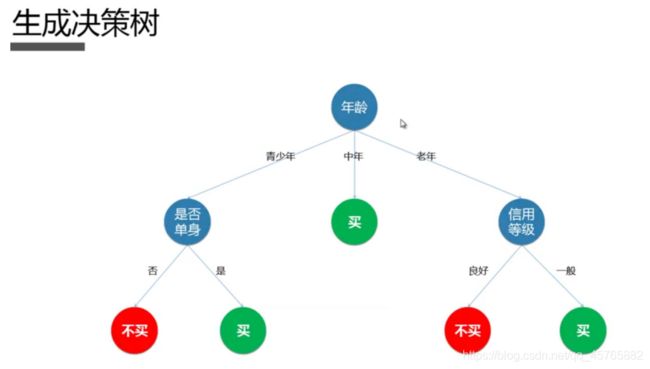
2.6.决策树分类算法详解

决策树是最经典的机器学习模型之一。它的预测结果容易理解, 易于向业务部门解释,
预测速度快,可以处理类别型数据和连续型数据。在机器学习的数据挖掘类求职面试中,决策树是面试官最喜欢的面试题之一。
2.6.1.算法原理











2.6.代码实现:
package cn.itcast.up.ml
import java.util.Date
import cn.itcast.up.base.BaseModel2
import cn.itcast.up.bean.HBaseMeta
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature._
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.sql.{Column, DataFrame, functions}
object USGModel extends BaseModel2{
def main(args: Array[String]): Unit = {
execute()
}
/**
* 获取标签id(即模型id,该方法应该在编写不同模型时进行实现)
* @return
*/
override def getTagID(): Int = 56
/**
* 开始计算
*inType=HBase##zkHosts=192.168.10.20##zkPort=2181##
*hbaseTable=tbl_goods##family=detail##selectFields=cOrderSn,ogColor,productType
* @param fiveDF MySQL中的5级规则 id,rule
* @param hbaseDF 根据selectFields查询出来的HBase中的数据
* @return userid,tagIds
*/
override def compute(fiveDF: DataFrame, hbaseDF: DataFrame): DataFrame = {
import org.apache.spark.sql.functions._
import spark.implicits._
//fiveDF.show()
//fiveDF.printSchema()
val ordersDF: DataFrame = spark.read
.format("cn.itcast.up.tools.HBaseSource")
.option(HBaseMeta.ZKHOSTS, "bd001")
.option(HBaseMeta.ZKPORT, "2181")
.option(HBaseMeta.HBASETABLE, "tbl_orders")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "memberId,orderSn")
.load()
//ordersDF.show(10)
val goodsDF: DataFrame = spark.read
.format("cn.itcast.up.tools.HBaseSource")
.option(HBaseMeta.ZKHOSTS, "bd001")
.option(HBaseMeta.ZKPORT, "2181")
.option(HBaseMeta.HBASETABLE, "tbl_goods")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "cOrderSn,ogColor,productType")//如果有更多的特征,可能需要 PCA降维
.load()
//goodsDF.show(10)
//颜色ID应该来源于字典表,这里简化处理
val color: Column = functions
.when('ogColor.equalTo("银色"), 1)
.when('ogColor.equalTo("香槟金色"), 2)
.when('ogColor.equalTo("黑色"), 3)
.when('ogColor.equalTo("白色"), 4)
.when('ogColor.equalTo("梦境极光【卡其金】"), 5)
.when('ogColor.equalTo("梦境极光【布朗灰】"), 6)
.when('ogColor.equalTo("粉色"), 7)
.when('ogColor.equalTo("金属灰"), 8)
.when('ogColor.equalTo("金色"), 9)
.when('ogColor.equalTo("乐享金"), 10)
.when('ogColor.equalTo("布鲁钢"), 11)
.when('ogColor.equalTo("月光银"), 12)
.when('ogColor.equalTo("时尚光谱【浅金棕】"), 13)
.when('ogColor.equalTo("香槟色"), 14)
.when('ogColor.equalTo("香槟金"), 15)
.when('ogColor.equalTo("灰色"), 16)
.when('ogColor.equalTo("樱花粉"), 17)
.when('ogColor.equalTo("蓝色"), 18)
.when('ogColor.equalTo("金属银"), 19)
.when('ogColor.equalTo("玫瑰金"), 20)
.otherwise(0)
.alias("color")
//类型ID应该来源于字典表,这里简化处理
val productType: Column = functions
.when('productType.equalTo("4K电视"), 9)
.when('productType.equalTo("Haier/海尔冰箱"), 10)
.when('productType.equalTo("Haier/海尔冰箱"), 11)
.when('productType.equalTo("LED电视"), 12)
.when('productType.equalTo("Leader/统帅冰箱"), 13)
.when('productType.equalTo("冰吧"), 14)
.when('productType.equalTo("冷柜"), 15)
.when('productType.equalTo("净水机"), 16)
.when('productType.equalTo("前置过滤器"), 17)
.when('productType.equalTo("取暖电器"), 18)
.when('productType.equalTo("吸尘器/除螨仪"), 19)
.when('productType.equalTo("嵌入式厨电"), 20)
.when('productType.equalTo("微波炉"), 21)
.when('productType.equalTo("挂烫机"), 22)
.when('productType.equalTo("料理机"), 23)
.when('productType.equalTo("智能电视"), 24)
.when('productType.equalTo("波轮洗衣机"), 25)
.when('productType.equalTo("滤芯"), 26)
.when('productType.equalTo("烟灶套系"), 27)
.when('productType.equalTo("烤箱"), 28)
.when('productType.equalTo("燃气灶"), 29)
.when('productType.equalTo("燃气热水器"), 30)
.when('productType.equalTo("电水壶/热水瓶"), 31)
.when('productType.equalTo("电热水器"), 32)
.when('productType.equalTo("电磁炉"), 33)
.when('productType.equalTo("电风扇"), 34)
.when('productType.equalTo("电饭煲"), 35)
.when('productType.equalTo("破壁机"), 36)
.when('productType.equalTo("空气净化器"), 37)
.otherwise(0)
.alias("productType")
//使用运营的统计数据对数据进行标注
//训练的目的就是从已标注数据中找到规律,以后新来了一条数据,就可以进行预测
val label: Column = functions
.when('ogColor.equalTo("樱花粉")
.or('ogColor.equalTo("白色"))
.or('ogColor.equalTo("香槟色"))
.or('ogColor.equalTo("香槟金"))
.or('productType.equalTo("料理机"))
.or('productType.equalTo("挂烫机"))
.or('productType.equalTo("吸尘器/除螨仪")), 1) //女
.otherwise(0)//男
.alias("gender")//决策树预测label
//最终需要找到用户和用户所购买的所有商品,进行训练,找到商品和性别之间的关系
val source = goodsDF.select('cOrderSn as "orderSn", color, productType, label)
.join(ordersDF, "orderSn")
.select('memberId as "userId", 'color, 'productType, 'gender)
//source.show(10)
//机器学习部分
//https://www.cnblogs.com/itboys/p/8312894.html
//1.处理label,将元数据添加到标签列中
val labelIndexer: StringIndexerModel = new StringIndexer()
.setInputCol("gender")
.setOutputCol("label")
.fit(source)
//2.处理features,将多个列合并为向量列的特征变换器
val featureVectorAssembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("color", "productType"))
.setOutputCol("features")
val featureDF: DataFrame = featureVectorAssembler.transform(source)
//featureDF.show(10)
//对特征进行索引,大于3个不同的值的特征被视为连续特征
//VectorIndexer是对数据集特征向量中的类别(离散值)特征(index categorical features categorical features)进行编号。
//它能够自动判断那些特征是离散值型的特征,并对他们进行编号,具体做法是通过设置一个maxCategories,
//特征向量中某一个特征不重复取值个数小于maxCategories,则被重新编号为0~K(K<=maxCategories-1)。
//某一个特征不重复取值个数大于maxCategories,则该特征视为连续值,不会重新编号(不会发生任何改变)
//主要作用:提高决策树或随机森林等ML方法的分类效果
val featureVectorIndexer: VectorIndexerModel = new VectorIndexer()
.setInputCol("features")
.setOutputCol("featureIndexed")
.setMaxCategories(3)
.fit(featureDF)
//3.创建决策树
val decisionTreeClassifier: DecisionTreeClassifier = new DecisionTreeClassifier()
.setFeaturesCol("featureIndexed")
.setPredictionCol("predict")
.setImpurity("gini") //Gini不纯度
.setMaxDepth(5) //树的最大深度
.setMaxBins(5)//离散化连续特征的最大划分数
//4.还原label
val labelConverter: IndexToString = new IndexToString()
.setInputCol("label")
.setOutputCol("labelConverted")
.setLabels(labelIndexer.labels)
//5.划分训练集/测试集
val Array(traiData,testData) = source.randomSplit(Array(0.8,0.2))
//6.使用Pipeline串联
val pipeline: Pipeline = new Pipeline()
.setStages(Array(labelIndexer,featureVectorAssembler,featureVectorIndexer,decisionTreeClassifier,labelConverter))
val model: PipelineModel = pipeline.fit(traiData)
//7.预测
val predictTestDF: DataFrame = model.transform(testData)
val predictTrainDF: DataFrame = model.transform(traiData)
//predictTestDF.show(10,false)
//predictTrainDF.show(10,false)
//8.查看损失
evaluateAUC(predictTrainDF,predictTestDF)
//9.查看决策树
val treeModel: DecisionTreeClassificationModel = model.stages(3).asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model:\n" + treeModel.toDebugString)
//10.预测用户的性别, 分组聚合
//预测规则A:每个订单的男性商品>=80%则认定为该订单的用户为男,或女商品比例达到80%则认定为该订单的用户为女;
//由于是家电产品,一个订单中通常只有一个商品。调整规则A为规则B:
//预测规则B:计算每个用户近半年内所有订单中的男性商品超过60%则认定该用户为男,或近半年内所有订单中的女性品超过60%则认定该用户为女
val ruleMap: Map[String, Long] = fiveDF.collect().map(row=>(row.getString(1),row.getLong(0))).toMap
println(ruleMap)
//Map(0 -> 57, 1 -> 58, -1 -> 59)
val getGenderTagUDF = udf((maleCount: Double, femaleCount: Double, total: Double)=> {
val maleRatio = maleCount / total
val femaleRatio = femaleCount / total
if (maleRatio >= 0.6) {
ruleMap("0") //男
}
if (femaleRatio >= 0.6) {
ruleMap("1")
}
ruleMap("-1")
})
val tempDF: DataFrame = predictTestDF.union(predictTrainDF)
.select('userId,
when('predict === 0, 1).otherwise(0).as("male"), //计算每个用户所有订单中的男性商品的订单数
when('predict === 1, 1).otherwise(0).as("female")) //计算每个用户所有订单中的女性商品的订单数
.groupBy('userId)
.agg(
count('userId) cast DoubleType as "total",
sum('male) cast DoubleType as "maleCount",
sum('female) cast DoubleType as "femaleCount")
tempDF.show(20,false)
val newDF: DataFrame = tempDF.select('userId, getGenderTagUDF('maleCount, 'femaleCount, 'total) as "tagIds")
newDF.show(10)
println(new Date().toLocaleString)//需要20多分钟
newDF
}
/**
* @param predictTestDF
* @param predictTrainDF
*/
def evaluateAUC(predictTrainDF: DataFrame,predictTestDF: DataFrame): Unit = {
// 1. ACC
val accEvaluator = new MulticlassClassificationEvaluator()
.setPredictionCol("predict")
.setLabelCol("label")
.setMetricName("accuracy")//精准度
val trainAcc: Double = accEvaluator.evaluate(predictTrainDF)
val testAcc: Double = accEvaluator.evaluate(predictTestDF)
println(s"训练集上的 ACC 是 : $trainAcc")
println(s"测试集上的 ACC 是 : $testAcc")
//训练集上的 ACC 是 : 0.7512278050623347
//测试集上的 ACC 是 : 0.7660406885758998
// 2. AUC
val trainRdd: RDD[(Double, Double)] = predictTrainDF.select("label", "predict").rdd
.map(row => (row.getAs[Double](0), row.getAs[Double](1)))
val testRdd: RDD[(Double, Double)] = predictTestDF.select("label", "predict").rdd
.map(row => (row.getAs[Double](0), row.getAs[Double](1)))
val trainAUC: Double = new BinaryClassificationMetrics(trainRdd).areaUnderROC()
val testAUC: Double = new BinaryClassificationMetrics(testRdd).areaUnderROC()
println(s"训练集上的 AUC 是 : $trainAUC")
println(s"测试集上的 AUC 是 : $testAUC")
//训练集上的 AUC 是 : 0.6591635864480606
//测试集上的 AUC 是 : 0.7046995800897444
}
}