caffe-ssd编译、训练、测试全过程(最后有彩蛋)
大家好,终于把SSD整通了,现在我把整个过程搭建给你们讲讲。
caffe_ssd多目标检查效果还是非常好的,在线测试,FPS在20左右。我的训练的还是官方的数据集,其实我们可通过做自己的数据集得到预测模型也是可以的。
一、SSD编译
https://github.com/weiliu89/caffe.git
git checkout ssd跟编译caffe 是一样的,进入到caffe的根目录里:
cp Makefile.config.example Makefile.config进入Makefile.config,设置如下,我们需要使用USE_CUDNN(前提你安装了CUDNN,整个详细的参考,戴尔笔记本双显卡配置nvidia367+cuda8.0+caffe)

mkdir build
cd build
cmake ..
make all -j
make install
make runtest
make pycaffe
二、下载数据集
1、预训练模型下载:
链接: https://pan.baidu.com/s/1nuGojSP 密码: v9bg
2、下载VOC2007、VOC2012数据集
官网下载太慢了,我已经上传到了百度云
链接: https://pan.baidu.com/s/1mhVjuSo 密码: 8nm7
在home主目录下
mkdir data
cd data把刚才下载的数据解压到data目录下
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar(安装我整个顺序解压就可以了)
三、生成LMDA文件(自己制作数据也需要这样的)
我这里把pycaffe的环境加入~/.bashrc文件中
export PYTHONPATH=$PYTHONPATH:..../caffe/python
source ~/.bashrc进入到caffe 的根目录下
./data/VOC0712/create_list.sh
./data/VOC0712/create_data.sh四、训练数据集及在线演示
1、训练数据集
打开caffe/examples/ssd/ssd_pascal.py,看到gpus='0,1,2,3' 该成gpus='0'
具体怎么看自己gpu id?
nvidia-smi
修改下 batch_size=1和 test_batch_size=1 (显存太小了,所以把网格设小点)
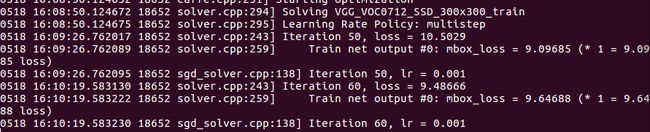
注意:迭代数增加,loss应该是逐渐减小,不然就容易发散了。
大概迭代到10000次,会test下,把test_batch_size设置为1,不然会出现显存溢出的情况
2、测试下:(我把训练好的模型进行测试,迭代了240000次)
python examples/ssd/score_ssd_pascal.py其实一般的情况在0.7左右
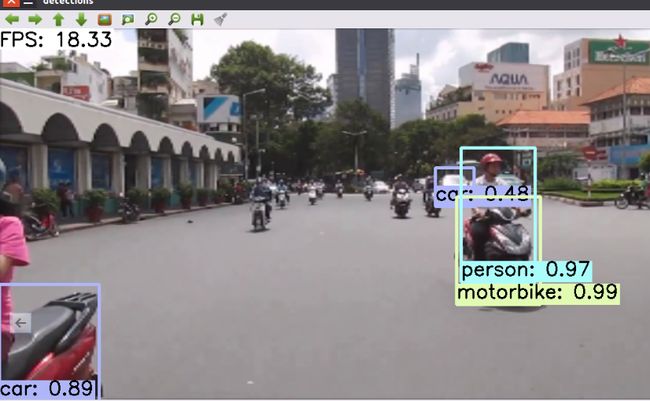
3、在线演示

见鬼了,在右边的空着的椅子出现个person:0.67 ,吓到我了
视频演示:
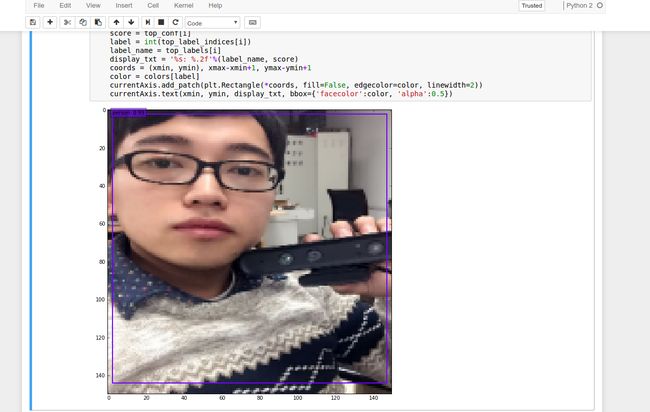
单张图片演示:我们可以使用:jupyter notebook
好了,下期给大家讲讲怎么制作自己的数据集,进行训练模型。
------------------------------2017.6.14 QAQ----------------------------------------
在生成lmda文件的时候,出现python一些错误?
终端执行:
sudo apt-get install python-skimage python-protobuf