spark streaming 滑动窗口
滑动窗口
DStream.window(window length,sliding interval)
batch interval:批处理时间间隔,spark streaming将消息源(Kafka)的数据,以流的方式按批处理时间间隔切片,一个批处理间隔时间对应1个切片对应生成的1个RDD
window length :窗口时间长度,每个批处理间隔将会实际处理的RDD个数(1...n)。是批处理间隔的N(N>=1)倍。
sliding interval:滑动窗口时间长度,窗口操作执行的时间间隔。如果设置为=batch interval,则每个批处理时间间隔都会执行一次窗口操作,如果设置为=N*processingInterval(N>1,N为Int),则每N个批处理时间间隔会执行一次窗口操作。
假设spark streaming 从kafka的largest 偏移量处开始消费
对于一个新的消费者:
每隔一次batch interval,会更新一次offset(拉取的数据为该batch interval内进入kafka的实时数据)
每隔一次sliding interval,会进行生成windowed DStream 操作,并执行逻辑,最后更新一次offset。其中生成的 windowed DStream的数据源为当前最后 window length对应的N个RDD的和(N>=sliding interval,且N=n*batch interval)。
对于一个旧的消费者:
每隔一次batch interval,会更新一次offset(拉取的数据为该batch interval内进入kafka的实时数据+之前保存的offset位置到当前位置的历史数据)
每隔一次sliding interval,会进行生成windowed DStream 操作,并执行逻辑,最后更新一次offset。其中生成的 windowed DStream的数据源为当前最后 window length包含的N个RDD的和(N>=sliding interval,且N=n*batch interval)。
1.如果,window length=3Min,sliding interval=1Min,batch interval=1Min,假设spark streaming 从kafka的largest 偏移量处开始消费。
上述语义为:每隔1分钟,将当前最后3分钟的数据生成一个windowed DStream(如果有多个RDD,则合并他们)
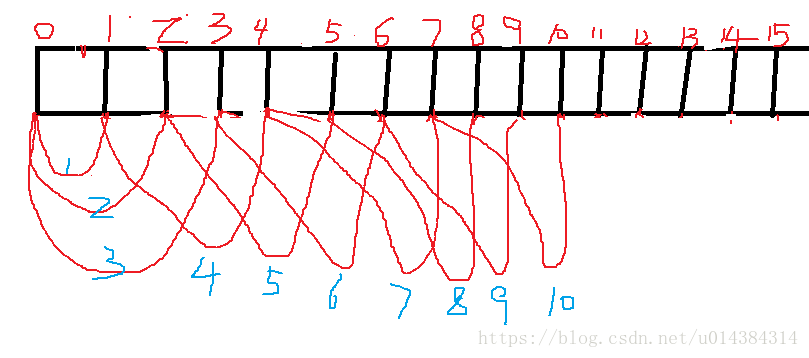
在第一个分钟里,会从kafka里面拉取新进入kafka里的第一分钟的数据并封装为RDD存储到内存,并拉取当前最后1分钟的数据生成一个windowed DStream执行print等action操作(为什么是当前最后1分钟?因为当前只有1分钟的数据)
两分钟过去后,会从kafka里面拉取新进入kafka里的第2分钟的数据并封装为RDD存储到内存,并拉取当前最后2分钟的数据生成一个windowed DStream执行print等action操作
3分钟过去后,会从kafka里面拉取新进入kafka里的第3分钟的数据并封装为RDD存储到内存,并拉取当前最后3分钟的数据生成一个windowed DStream执行print等action操作
4分钟过去后,会从kafka里面拉取新进入kafka里的第4分钟的数据并封装为RDD存储到内存,并拉取当前最后3分钟的数据生成一个windowed DStream执行print等action操作
5分钟过去后,会从kafka里面拉取新进入kafka里的第5分钟的数据并封装为RDD存储到内存,并拉取当前最后3分钟的数据生成一个windowed DStream执行print等action操作
....
2. 如果,window length=3Min,sliding interval=2Min,batch interval=1Min,假设spark streaming 从kafka的largest 偏移量处开始消费。
上述语义为:每隔2分钟,将当前最后3分钟的数据生成一个windowed DStream(如果有多个RDD,则合并他们)
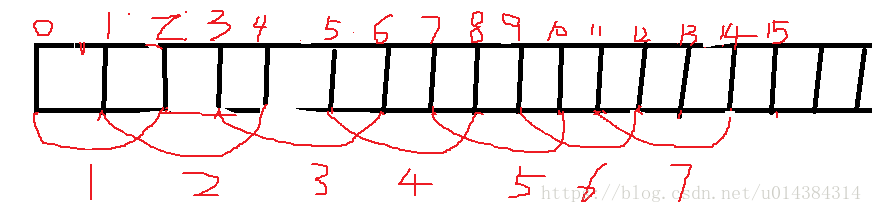
在14个batch interval 里会执行7次窗口数据处理,除了第一个窗口长度为2个batch interval以外,其他都为3个batch interval。
在第一个分钟里,会从kafka里面拉取新进入kafka里的第一分钟的数据并封装为RDD存储到内存
两分钟过去后,会从kafka里面拉取新进入kafka里的第2分钟的数据并封装为RDD存储到内存,执行print等action操作,这次会执行2个RDD里面的数据。
3分钟过去后,会从kafka里面拉取新进入kafka里的第3分钟的数据并封装为RDD存储到内存,不会执行print等action操作
4分钟过去后,会从kafka里面拉取新进入kafka里的第4分钟的数据并封装为RDD存储到内存,并拉取当前最后3分钟的数据生成一个windowed DStream执行print等action操作
5分钟过去后,会从kafka里面拉取新进入kafka里的第5分钟的数据并封装为RDD存储到内存,不会执行print等action操作
6分钟过去后,会从kafka里面拉取新进入kafka里的第6分钟的数据并封装为RDD存储到内存,并拉取当前最后3分钟的数据生成一个windowed DStream执行print等action操作
7分钟过去后,会从kafka里面拉取新进入kafka里的第7分钟的数据并封装为RDD存储到内存,不会执行print等action操作
.....
在实际应用中:window length - sliding interval >=应用中给定的需要统计的累计最大时长,这样才不会因为当前窗口遗漏某些特殊时间段的数据。
如有这样一个逻辑:要求判断连续30分钟的数据满足条件A,则得出结果B
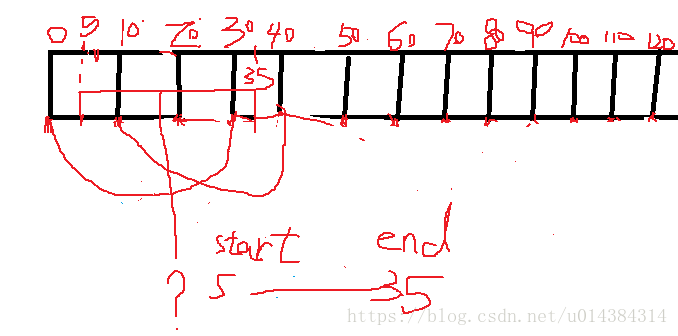
如果,让window length=30,sliding interval=10,batch interval=10,即window length - sliding interval < 30分钟
那么 从第5分钟开始连续,直到35分钟时结束连续的这段数据,将不能正常得到结果B
如果,让window length=40,sliding interval=10,batch interval=10,即window length - sliding interval =30分钟
那么 从第5分钟开始连续,直到35分钟时结束连续的这段数据,将可以正常得到结果B
觉得还行的话,右上角点个赞哟。