虚拟内存及缓冲区管理
在刚开始接触TQ2440并测试TEST程序时,当时就产生了一个疑惑,把程序下载到NAND和SDRAM中,其中断均能正确执行,当时以为,程序有可能采用了动态添加中断向量技术,即在SDRAM中运行时在向量0x18处添加跳转指令的二进制编码。虽然能够实现,但在实际编程时会非常麻烦。
ARM采用了虚拟内存映射技术即MMU,负责虚拟地址到物理地址的映射,并提供硬件机制的内存访问权限检查,通过使用CACHE及WRITE BUFFER技术缩小处理器和存储系统的差别,从而提高系统的整体性能。
在系统加电时,将ROM/FLASH映射为地址0,进行一些初始化工作并将程序加载到SDRAM中去,然后启用MMU,将虚拟地址0映射到SDRAM地址(0x30000000),这样当中断产生时读取0x18处的指令时实际读取的是0x30000018处的指令,这样中断就就可以正确执行。
S3c2440内存管理单元有如下特征:
4种映射长度,段1M、大页64k、小页4k,极小页1k
指令TLB(含64个条目)、数据TLB(含64个条目)
硬件访问页表地址映射、权限检查由硬件自动完成
第一节CP15寄存器的功能及读写
ARM的虚拟地址管理主要通过CP15相关寄存器来实现的,CP15包括了16个32位寄存器,编号为0~15,实际上对于某些编号的寄存器可能对应有多个物理寄存器,在指令编码时指定标志位来区分。
CP15寄存器功能
| 编号 |
MMU功能 |
| C0 |
ID编码(只读) |
| C1 |
开启/禁止MMU/CACHE/WRITE等功能 |
| C2 |
地址转换表基地址 |
| C3 |
域访问控制 |
| C4 |
保留 |
| C5 |
内存失效状态 |
| C6 |
内存失效状态 |
| C7 |
CACHE及WRITE控制 |
| C8 |
TLB控制 |
| C9 |
CACHE锁定 |
| C10 |
TLB锁定 |
| C11 |
保留 |
| C12 |
保留 |
| C13 |
进程PID |
| C14 |
保留 |
| C15 |
|
CP15寄存器的读写
MCR ARM寄存器到协处理器寄存器数据传送
MRC 协处理器寄存器到ARM寄存器数据传送
格式:
MCR/MRC P15,0,
其中RD为ARM寄存器
CRN为协处理器寄存器
CRM附加的目标寄存器或源操作数寄存器,用于区分一个编号的不同物理寄存器,当指令不需要提供附加信息时,将CRMC0指定为,OPCODE_2指定为0
MCR P15,0,R4,C1,C0,0 R4->C1
MRC P15,0,R4,C1,C0,0 R4<-C1
C1寄存器位相关功能
M[0]:0禁止|1启用MMU
A[1]:0禁止地址对齐检查|1使能地址对齐检查
C[2]:0禁止数据CACHE|1使能数据CACHE
W[3]:0禁止写缓冲|1使能写缓冲
I[12]:0禁止代码CACHE|1使能代码CACHE
第二节 地址转换过程
MMU地址转换过程及描述符定义
描述符定义:
| 第一级段、粗页和细页描述符 |
||||||||||||||||
| 类型 |
31 20 |
19 12 |
11 |
10 |
9 |
8 5 |
4 |
3 |
2 |
1 |
0 |
|||||
| 粗页 |
二级页表基地址[31:10] |
|
Domain |
1 |
|
|
0 |
1 |
||||||||
| 段 |
物理地址基地址[31:20] |
|
AP |
|
Domain |
1 |
C |
B |
1 |
0 |
||||||
| 细页 |
二级页表基地址[31:12] |
|
|
Domain |
1 |
|
|
1 |
1 |
|||||||
| 第二级极大页、小页和极小页描述符 |
||||||||||||||||
|
|
31 16 |
15 12 |
11 |
10 |
|
9 8 |
7 6 |
5 4 |
3 |
2 |
1 |
0 |
||||
| 极大 |
物理地址基地址[31:16]64k |
|
Ap3 |
Ap2 |
Ap1 |
Ap0 |
C |
B |
0 |
1 |
||||||
| 小页 |
物理地址基地址[31:12]4k |
Ap3 |
Ap2 |
Ap1 |
Ap0 |
C |
B |
1 |
0 |
|||||||
| 极小 |
物理地址基地址[31:10]1k |
|
|
ap |
C |
B |
1 |
1 |
||||||||
虚拟地址空间到物理地址空间映射是以内存块为单位进行的,即虚拟存储空间中一块连续的存储空间被映射成物理存储空间中同样大小的一块连续存储空间,每一个描述符实际记录了一个虚拟地址与物理地址之间的对应关系,ARM支持多种地址变换。
通常,以段为单位的地址变换过程只需要一级页表,而以页为单位的地址变换过程还需要二级页表。
地址转换过程
1. 从CP15寄存器C2得到一级页表的基地址
2. 将虚拟地址[31:20]作为页表的索引,得到页表中该虚拟地址的描述符。
3. 判断该描述符是否为段描述符,如为段描述符,将该描述符[31:20]和虚拟地址[19:0]作为偏移量组成一个32位的物理地址进行访问。
4. 如为粗页表描述符,则将该粗页表描述符[31:10]作为二级页表的基地址,并将虚拟地址[19:12]位作为索引得到在二级页表中该虚拟地址的描述符。
判断二级页表符的类型
① 为极大页描述符表将该描述符[31:16]作为基地和虚拟地址[15:0]作为偏移量得到该虚拟地址的32位物理地址进行访问。
② 为小页描述符表将描述符[31:12]作为基地和虚拟地址[11:0]作为偏移量得到该虚拟地址的32位物理地址进行访问。
5. 如为细页表描述符,将该组页表描述符[31:12]作为二级页表的基地址,并将虚拟地址[19:10]位作为索引得到在二级页表中该虚拟地址的描述符。
判断二级页表符的类型
① 为大页描述符表将该描述符[31:16]作为基地和虚拟地址[15:0]作为偏移量得到该虚拟地址的32位物理地址进行访问。
②为小页描述符表将该描述符[31:12]作为基地和虚拟地址[11:0]作为偏移量得到该虚拟地址的32位物理地址进行访问。
③为小极页描述符表将描述符[31:10]作为基地和虚拟地址[9:0]作为偏移量得到该虚拟地址的32位物理地址进行访问。
其转换过程如下图如示:
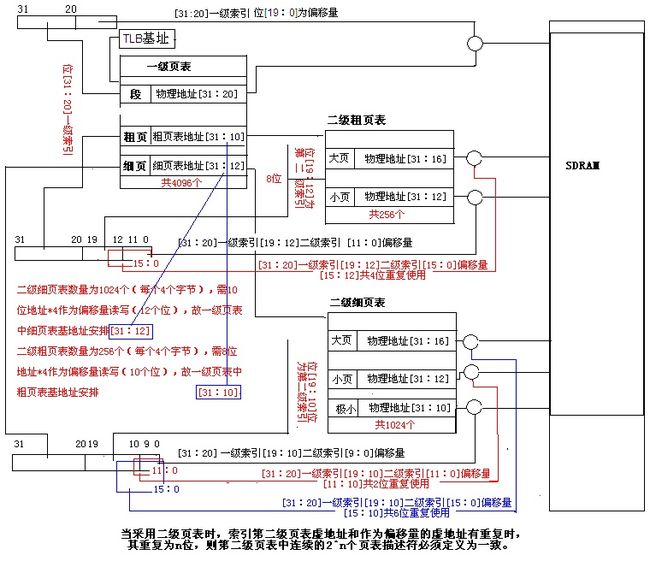
当采用段描述符时,虚地址[19:0]共20位作为偏移量可寻址空间为1M
当采用二级描述符时:
第一级为粗页时,虚地址[19:12]共8位作为第二级的索引量,可寻址256个第二级页表。
1.当第二级为小页描述符时,虚地址[11:0]作为偏移量,可寻址空间2^12=4k,一个粗页表总可寻址4k*256=1M。
2.当第二级为大页描述符时,虚地址[15:0]作为偏移量,可寻址空间2^16=64k 但是,虚地址[19:15:12]是作为第二级大页描述符的索引,虚地址[15:0]作为偏移量,也就是说虚地址[15:12]被重复使用。我们考虑一下从0x0~0xffff(64K)空间地址的转换问题,显然虚地址[15:12]将从0~f,也就是说二级页表开始的16个描述符都将被访问,如果每个描述符定义的页物理基地址不一致,如第二级第一个页表定义物理基地址为0x300000000;第2个页表为0x30001000,第16个页表定义的物理基地址为0x300f000时,0~ffff(64K)空间将被映射到0~fffff(1M)地址空间,显然这是不正确的。为了得到正确的结果,我们可以将这粗页表中16个连续的大页描述符定义为同一大页描述符,其物理基地址一致。
结论:当采用二级页表时,索引第二级页表虚地址和作为偏移量的虚地址有重复时,其重复为n位,则第二级页表中连续的2^n个页表描述符必须定义为一致。如上所示[15:12]位重复,n=4,则连续16个描述符必须相同。
第一级为细页表时,其情况类似,不再分析。
地址映射具体实例:
我们将以下图所示的过程对虚拟地址0x00000018和0x30605600的转换过程进行详细的说明:
TLB寄存器值0x33ffc000是整个页表的基地址
0x00000018地址转换:将虚地址[31:20]位0x0作为索引*4(每个描述符占4个字节)再与页表基地址相加得0x33ffc000,即页表中第一个描述符,因为该描述符为段描述符,将其[31:20]位0x300左移20位充0为0x30000000作为该段物理基地址,并将虚地址[19:0]位0x18作为偏移地址与该段物理基地相加得0x30000018。该地址就为虚地址0x18对应的物理地址。
0x30605600地址转换:将虚地址[31:20]位0x306作为索引*4(每个描述符占4个字节)再与页表基地址相加得0x33ffcc18,即页表中第775个描述符,因为该描述符为粗页描述符,将其[31:10]位0xcffc0左移10位为0x33ff0000作为第二级页表的基地址。再将虚地址[19:12]位0x05作为索引*4(每个描述符占4个字节)与0x33ff0000相加得到该虚拟地址的第二级页描述符地址0x33ff0014。因为该描述符为第二级小页描述符,将其[31:12]位0x30605左移12位得0x30605000作为该粗页的物理基地址,并与虚地址[11:0]位0x600作为偏移量相加得0x30605600作为该虚地址转换后的物理地址。
描述符表的计算及添加
设定:
因为段描述符可以映射1M的空间,需要映射多少M就需要多少个连续的段描述符
1. 将虚拟结束地址和起始地址右移20位(除1M)相减,得段描述符数量用来控制需要循环的次数
2. 根据TLB和虚拟起始地址得到在页表描述符的起始地址
3. 将需要映射的物理地址右移20位(除1M)
4. 将移位后的物理地址填入起始位置页表描述符的[31:20]位,并将描述符属性加入描述符相应位置[11:0]AP、Domain、CB、10(段描述符标志)
5. 将描述符起始地址加4(描述符为4个字节)指向下一个描述符
6. 将移位后的物理地址加1(实际上在基地址的位[20]加1)指向下一M物理空间。
7. 循环至第4步,至到所有描述符被赋值。
第三节Cache和写缓冲
ARM920T有16K的数据Cache和16K的指令Cache,这两个Cache是基本相同的,数据Cache多了一些写回内存的机制,后面我们以数据Cache为例来介绍Cache的基本原理。我们已经知道,Cache中的存储单位是Cache Line,ARM920T的一个Cache Line是32字节,因此16K的Cache由512条Cache Line组成。要了解Cache的基本原理,我们从如何设计Cache这个问题入手。
设计Cache的一种最朴素的想法是,把VA分成以32字节为单位,从任何一个对齐到32字节地址边界的VA开始连续的32个字节(比如0x00-0x1f,0x20-0x3f,0x40-0x5f等等)都可以缓存到512条Cache Line中的任何一条。那么一条Cache Line中的32个字节怎么知道是来自哪个VA的呢?这就需要把VA也保存在Cache中,由于这32字节的起始地址是对齐到32字节地址边界的,末5位全为0,因此只需要保存VA[31:5]即可,这称为VA Tag[4],Tag是VA的一部分,是Cache Line中数据的标识,表明这32字节数据来自哪个VA。这样设计的Cache称为全相联Cache(Fully Associative Cache),图示如下:
图 17. 全相联Cache
给定一个VA,如何在Cache中查找对应的数据呢?首先到Cache中比较查找哪一行的Tag等于VA[31:5],找到对应的Cache Line后,再根据VA[4:0]决定要访问的是该Cache Line缓存的32个字节中的哪一个字节。由于有512条Cache Line,如果这个VA没有缓存在Cache中则需要比较512次才知道,这是最坏的情况,也是最常见的情况,下面我们要改进Cache的设计来解决这个问题。
全相联Cache的特点是任何VA都可以缓存到任何一条Cache Line,给定一个VA做查找时,由于它有可能缓存在512条Cache Line中的任何一条,就只好全部都找一遍了。如果限定某一个VA只允许缓存在某一条Cache Line中,那么查找的过程就快多了:检查一下应该缓存这个VA的那条Cache Line,看Tag一致不一致,如果一致就是Cache Hit,如果不一致就是Cache Miss,可以直接访问物理内存而不必再找其它Cache Line了。这种设计称为直接映射Cache(Direct Mapped Cache),如下图所示:
图 18. 直接映射Cache
地址0~31应该缓存在第1条Cache Line中,地址32~63应该缓存在第2条Cache Line中,依此类推,地址16352~16383应该缓存在第512条Cache Line中,下一个地址应该是16384(16K)了,我们又回到开头,地址16K~16K+31应该缓存在第1条Cache Line中,地址16K+32~16K+63应该缓存在第2条Cache Line中,依此类推,再次回到开头的地址应该是32K,32K~32K+31应该缓存在第1条Cache Line中,32K+32~32K+63应该缓存在第2条Cache Line中,依此类推。读者应该可以总结出规律了:给定一个VA,将它除以16K得的余数决定了它应该缓存在哪一条Cache Line中,那么除以16K的商数部分就应该是VA Tag,用以区别Cache Line中缓存的到底是0还是16K还是32K地址上的数据。那么除以16K的商数和余数怎么表示呢?VA[31:14]就是除以16K的商数,VA[13:0]就是余数,所以上图的Tag处标着VA[31:14]。余数VA[13:0]是16K Cache里的一个字节偏移量,而Cache是按32字节一个Cache Line组织的,所以余数中的高位VA[13:5]决定了是第几条Cache Line,余数中的低位VA[4:0]决定了Cache Line内的字节偏移量。验算一下,VA[13:5]一共是9位,作为Cache Line的编号可以表示的Cache Line数目正是512条。
直接映射Cache虽然查找速度很快,但也有缺点。比如,地址0~31、16K~16K+31、32K~32K+31都应该缓存到第1条Cache Line中,假如我们程序第一次访问地址30,地址0~31的数据就从内存加载到第1条Cache Line,以便下次访问能更快一些,但是我们程序第二次访问的却是地址32770,地址32K~32K+31的数据就要从内存加载到第1条Cache Line,把Cache Line里原来存的地址0~31的数据替换掉,以便下次访问能更快一些,但是我们程序第三次访问的却是地址16392……这样下去,Cache起不到任何加速作用,形同虚设,这种问题称为Cache抖动(Cache Thrash)。全相联Cache就不会有这种问题,因为任何VA都可以缓存到任何一条Cache Line,可以把先后几次访问的VA缓存到不同的Cache Line,就不会相互冲突。
全相联Cache和直接映射Cache各有优缺点,全相联Cache查找很慢,但没有抖动问题,直接映射Cache则正相反。为了得到更好的性能,实际CPU的Cache设计是取两者的折衷,把所有Cache Line分成若干个组,每一组有n条Cache Line,称为n路组相联Cache(n-way Set Associative Cache)。ARM920T采用64路组相联Cache,如下图所示:
图 19. 64路组相联Cache
有了前面两种Cache概念的基础,这种Cache应该很好理解,512条Cache Line分成8组,每组64条,地址0-31、256-587、512-543等等可以缓存到第1组64条Cache Line中的任何一条,地址32-63、288-319、544-575等等可以缓存到第2组64条Cache Line中的任何一条,依此类推。为什么说组相联Cache是全相联和直接映射Cache的一个折衷呢?如果把组分得很大,把全部Cache Line都分到一个组里面去,就变成了全相联Cache;如果把组分得很小,每组只有一个Cache Line,就变成了直接映射Cache。作为练习,请读者自己计算一下为什么VA Tag是VA[31:8],为什么组的编号用VA[7:5]表示。
那么,为什么组相联Cache的性能比直接映射Cache要好呢?一方面,组相联Cache把一条Cache Line上的冲突分散到了64条Cache Line上,起到了64倍的积极作用。而另一方面,应该缓存到同一个组的VA更多了:对于直接映射Cache,在同一个组(也就是同一条Cache Line)互相冲突的VA有4G/512个;对于组相联Cache,在同一个组(64条Cache Line)互相冲突的VA有4G/8个。从这个数量关系来看,组相联Cache又起到了64倍的消极作用。难道这两种作用不会完全抵销吗?我不打算从数学上严格证明,这不是本节的重点,读者可以通过一个生活常识的例子来理解:层数一样多的两栋楼,其中一栋楼是一部电梯,每层三户,而另一栋楼是两部电梯,每层六户,每户的平均人数一样多,你认为在哪个楼里等电梯的时间较短呢?
接下来解释一下有关Cache写回内存的问题。Cache写回内存有两种模式:
Write Back:Cache Line中的数据被CPU核修改时并不立刻写回内存,Cache Line和内存中的数据会暂时不一致,在Cache Line中有一个Dirty位标记这一情况。当一条Cache Line要被其它VA的数据替换时,如果不是Dirty的就直接替换掉,如果是Dirty的就先写回内存再替换。
Write Through:每当CPU核修改Cache Line中的数据时就立刻写回内存,Cache Line和内存中的数据总是一致的。如果有多个CPU或设备同时访问内存,例如采用双口RAM,那么Cache中的数据和内存保持一致就非常重要了,这时相关的内存页面通常配置为Write Through模式。
通过读写CP15的相关寄存器,可以对Cache做以下操作:
Clean:将Cache Line中的数据写回内存,清除Dirty位。在程序中的某些同步点上用于确保Cache Line和内存中的数据一致。
Invalidate:在Cache Line中有一个Invalid位表示无效,将这个位置1,下次要访问时即使VA Tag匹配也重新从内存读取数据。例如进程切换时需要声明前一个进程缓存在Cache中的数据无效。
Lock:将某个地址的数据锁定在Cache中,确保不被替换掉。在实时系统中,这样做可以保证某个地址的数据能在一个确定的时间内访问到。
从Cache中查找要访问的数据时用的是VA,但是Cache写回内存要用PA,如果写回内存时还需要查一遍页表就太没有效率了,所以实际上每条Cache Line中还保存了PA[31:5](PA Tag),完整的Cache构造如下图所示:
图 20. PA Tag
最后解决我们前面遗留的一个问题:页描述符中的C、B位具体是什么意思?
表 2. 页描述符中C、B位的含义
C位为1表示允许Cache,这种情况下用B位来表示Write Through还是Write Back。有些页面不允许Cache,置C位为0,这种情况下可以用B位来选择是否允许使用Write Buffer。Write Buffer也是一种简单的Cache,CPU核执行写指令时可以把数据交给Write Buffer,然后由Write Buffer负责写回内存,这时CPU可以执行后续指令而不必等待写回内存这个较慢的操作结束。想一下,既然有Write Buffer,为什么没有Read Buffer?
启用MMU后地址访问过程
当CPU请求存储器访问时,首先在TLB中查找虚拟地址,如果该虚拟地址对应的地址描述符不在TLB中时,读取内存中页表查询,并将该描述符添加到TLB中,如果TLB已满,根据一定算法进行替换。
在得到该地址描述符后,进行如下操作:
1从描述符表中得到对应的物理地址
2根据域访问控制和描述符中AP位确定是否允许对该内存进行操作。如不,则产生存储访问中止中断
3如访问被允许,根据描述符表中CB位决定是否缓存该内存的访问结果,如不,则根据得到的物理地址直接访问内存,如允许,则首先在CACHE中查找,命中则直接读取,如未命中,则根据物理地址直接访问内存,并将该数据读取到CACHE中。
第四节 具体编程实现
好了,通过对以上知识的学习,我们已经对ARM地址转换及CACHE的读写有了深刻的认识,因此启动MMU及CACHE,需要如下步骤:
1. 禁止数据CACHE,将C15中寄存器的c1寄存器C[2]清零
mrc p15,0,r0,c1,c0,0
bic r0,r0,#(0x1<<2)
mcr p15,0,r0,c1,c0,0
2. 禁止代码CACHE,将C15中寄存器的c1寄存器I[12]清零
mrc p15,0,r0,c1,c0,0
bic r0,r0,#(0x1<<12)
mcr p15,0,r0,c1,c0,0
3. 禁止MMU,将C15中寄存器的c1寄存器M[0]清零
mrc p15,0,r0,c1,c0,0
bic r0,r0,#0x1
mcr p15,0,r0,c1,c0,0
4. 使数据及代码段CACHE无效
mcr p15,0,r0,c7,c7,0
5. 清空写缓冲区
mcr p15,0,r0,c7,c10,4
6. 使TLB整个页表无效
mcr p15,0,r0,c8,c7,0
7. 设置控制域
mcr p15,0,r0,c3,c0,0 R0->C3;
8. 设置进程PID号
mcr p15,0,r0,c13,c0,0
9. 设置页表基地址
mcr p15,0,r0,c2,c0,0 R0->C2
10. 计算描述符表并添加到TLB指定的内存单元中
由于一级页表由虚地址[31:20]进行索引,共计4096个为16k,由于TQ2440开发板为64M内存,故我们将其放在0x33ffc000处,即64M内存的最未端的16K内存中。
11. 在设置好页表描述符的基础上, 我们启用地址对齐功能,将C1寄存器A[1]赋值为1
mrc p15,0,r0,c1,c0,0
orr r0,r0,#(0x1<<1)
mcr p15,0,r0,c1,c0,0
12. 开启MMU功能,将C1寄存器M[0]赋值为1
mrc p15,0,r0,c1,c0,0
orr r0,r0,#0x1
mcr p15,0,r0,c1,c0,0
13. 开启代码及数据CACHE,将C1寄存器C[2]位,I[12]位赋值为1
mrc p15,0,r0,c1,c0,0
bic r0,r0,#(0x1<<12+0x1<<2)
mcr p15,0,r0,c1,c0,0
经过以上步骤,我们成功开启了MMU及CACHE功能。在本程序中,为了能使用中断功能,我们将0~0x20000000(32M)的地址空间映射到了0x30000000~0x32000000处,这样当中断发生时,CPU到0x18处执行时,实际到物理地址0x30000018处执行,中断就能正常运行了。
虽然我们成功对0x0开始的地址进行了映射,但还有一个关键问题未解决,当CPU执行mcr p15,0,r0,c1,c0,0这条指令后,MMU功能开启,而这条指令的下一条指令已经开始译码并执行,而这条指令的地址已经通过MMU进行转换,那么此时程序如何保证能得到正确的物理地址而正确执行呢?如果我们将0x30000000映射到0x30000000,即虚拟地址与物理地址一致,显然程序能够正确执行。这也是ARM推荐使用这种方法。
TQ2440-TEST程序映射关系:
通过以上分析,我们确保了程序的正确运行,但又产生了新的问题,也就是说我们的程序必须保证在0x0和0x30000000均能正确运行,对于这个问题,我在前几章已经做过分析。一句话,确保程序是基于PC+8+偏移量的寻址方式。
我们完全可以将0x0处的地址映射到0x30000000处,其它地址映射保持不变,即虚拟地址与物理地址一致。这样地址映射对我们来说完全是透明的,在开发程序时,我们完全可以不用考虑它,最后调用它就行。