人工智能-数学基础-回归分析
目录
回归分析的一般步骤:
最小二乘法
估计标准误差
在1-α置信水平下预测区间为:
回归直线的拟合优度
判定系数(最终指导依据)
显著性检验
线性关系检验
回归系数的显著性检验
线性关系检验与回归系数检验的区别
多元线性回归分析
调整的多重判定系数:
曲线回归分析
多重共线性
多重共线性检验的主要方法:
容忍度:
方差膨胀因子
python 工具包
statsmodel回归分析
分类变量
plotly绘图实例
回归分析的一般步骤:

误差项ε 是独立同分布的,且服从一个μ为0,σ为Θ2次方的正态分布。
最小二乘法
最小二乘法的来由:

最小二乘估计来由:

估计标准误差
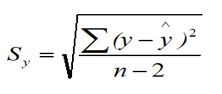
公式中根号内的分母是n-2,而不是n,因为自由度为n-2。实际上n-2等于n-p-1,p是预测因子维度。
在1-α置信水平下预测区间为:
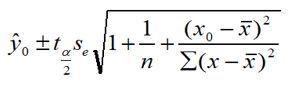
Se是标准误差,t统计量,α取值一般会给出,一般为0.05

相对于置信上下限,预测上下限考虑到了ε。
回归直线的拟合优度
总平方和(SST):
![]()
回归平方和(SSR):
![]()
残差平方和(SSE):
![]()
-
总平方和(SST),反映因变量的 n 个观察值与其均值的总离差
-
回归平方和SSR反映了y的总变差中,由于x与y之间的线性关系引起的y的变化部分
-
残差平方和SSE反映了除了x对y的线性影响之外的其他因素对y变差的作用,是不能由回归直线来解释的y的变差部分
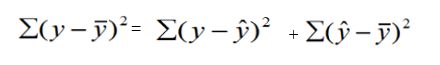 SST=SSE+SSR
SST=SSE+SSR
判定系数(最终指导依据)
回归平方和占总平方和的比例,用R^2表示,其值在0到1之间。
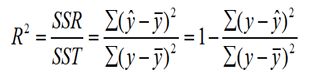 分母SSR表示模型能解释得误差,分布SS代表总误差。判定系数反应模型的解释能力,是最终指导依据。
分母SSR表示模型能解释得误差,分布SS代表总误差。判定系数反应模型的解释能力,是最终指导依据。
显著性检验
显著性检验的主要目的是根据所建立的估计方程用自变量x来估计或预测因变量y的取值。当建立了估计方程后,还不能马上进行估计或预测,因为该估计方程是根据样本数据得到的,它是否真实的反映了变量x和y之间的关系,则需要通过检验后才能证实。
根据样本数据拟合回归方程时,实际上就已经假定变量x与y之间存在着线性关系,并假定误差项是一个服从正态分布的随机变量,且具有相同的方差。但这些假设是否成立需要检验
显著性检验包括两方面:
-
线性关系检验
-
回归系数检验
线性关系检验
线性关系检验是检验自变量x和因变量y之间的线性关系是否显著,或者说,它们之间能否用一个线性模型来表示。
将均方回归 (MSR)同均方残差 (MSE)加以比较,应用F检验来分析二者之间的差别是否显著。
-
均方回归:回归平方和SSR除以相应的自由度(自变量的个数K)
-
均方残差:残差平方和SSE除以相应的自由度(n-k-1)
H0:β1=0 所有回归系数与零无显著差异,y与全体x的线性关系不显著
计算检验统计量F:
 均方回归比K,均方残差比n-K-1
均方回归比K,均方残差比n-K-1
回归系数的显著性检验
回归系数显著性检验的目的是通过检验回归系数β的值与0是否有显著性差异,来判断Y与X之间是否有显著的线性关系

计算检验的统计量:

线性关系检验与回归系数检验的区别
-
在一元线性回归中,自变量只有一个,线性关系检验与回归系数检验是等价的
-
多元回归分析中,这两种检验的意义是不同的。线性关系检验只能用来检验总体回归关系的显著性,而回归系数检验可以对各个回归系数分别进行检验
多元线性回归分析
调整的多重判定系数:
因为随着维度增加,R^2会自动增加,影响判定结果,所以需要矫正R^2。
 用样本容量n和自变量的个数k去修正R^2得到:
用样本容量n和自变量的个数k去修正R^2得到:
避免增加自变量而高估R^2
曲线回归分析
曲线回归分析最困难和首要的工作是确定自变量与因变量间的曲线关系的类型,曲线回归分析的基本过程:
- 先将x或y进行变量转换
- 对新变量进行直线回归分析、建立直线回归方程并进行显著性检验和区间估计
- 将新变量还原为原变量,由新变量的直线回归方程和置信区间得出原变量的曲线回归方程和置信区间
实例:某商店各个时期的商品流通费率和商品零售额资料

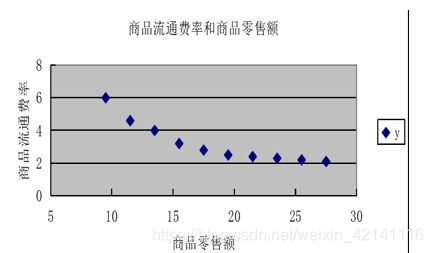


多重共线性
回归模型中两个或两个以上的自变量彼此相关的现象
多重共线性带来的问题有:
-
回归系数估计值的不稳定性增强
-
回归系数假设检验的结果不显著等
多重共线性检验的主要方法:
- 容忍度
- 方差膨胀因子(VIF)
容忍度:
![]()
- Ri是解释变量xi与方程中其他解释变量间的复相关系数;(应该有工具包可以算)
- 容忍度在0~1之间,越接近于0,表示多重共线性越强,越接近于1,表示多重共线性越弱。
方差膨胀因子
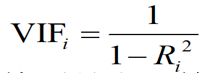 方差膨胀因子是容忍度的倒数
方差膨胀因子是容忍度的倒数
- VIFi越大,特别是大于等于10,说明解释变量xi与方程中其他解释变量之间有严重的多重共线性;
- VIFi越接近1,表明解释变量xi和其他解释变量之间的多重共线性越弱。
python 工具包
statsmodels 偏统计学习。点开链接查看官网教程例子
scikit-learn 偏人工智能。点开链接查看官网教程例子
statsmodel回归分析
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
# creat data
nsample = 20
x = np.linspace(0,10,nsample)
X = sm.add_constant(x) # add a column that filled with 1
beta = np.array([2,5]) # β0 和β1 分别设置为2,5
e = np.random.normal(size = nsample)
y = np.dot(X,beta)+e
model = sm.OLS(y,X) #最小二乘法
result = model.fit() #拟合数据
result.summary() #显示所有拟合后得相关参数 result.summary()
result.summary()
y_ = result.fittedvalues #拟合得估计值,返回一个数组,Y拔#绘图
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(x,y,'o',label='data')
ax.plot(x,y_,'r--',label='test')
ax.legend(loc='best')
plt.show()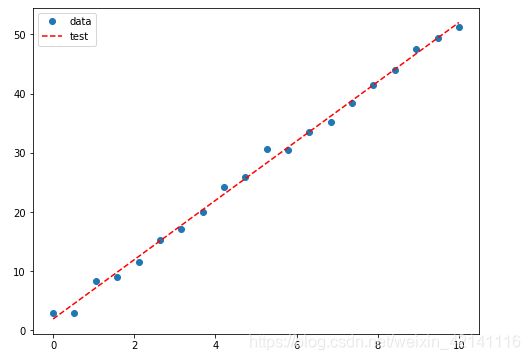
分类变量
假设分类变量有3个取值(a,b,c),比如考试成绩有3个等级。那么a就是(1,0,0),b(0,1,0),c(0,0,1),这个时候就需要3个系数β0,β1,β2,也就是β0x0+β1x1+β2x2
nsample = 50
groups = np.zeros(nsample,int)
groups[20:40] = 1
groups[40:] = 2
dummy = sm.categorical(groups,drop=True) #返回新数组,长度一致,每个位置是一个类似mask的分数组
# Y = 5+2X+3Z1+6Z2+9Z3
x = np.linspace(0,20,nsample)
X = np.column_stack((x,dummy))
X = sm.add_constant(X)
beta = np.array([5,2,3,6,9])
e = np.random.normal(size=nsample)
y = np.dot(X,beta) + e
results = sm.OLS(y,X).fit()
results.summary()
#显示
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(x,y,'o',label='data')
ax.plot(x,results.fittedvalues,'r--.',label='test')
ax.legend(loc='best')
plt.show()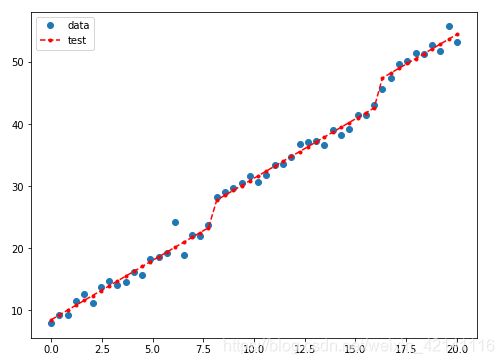
plotly绘图实例
import pandas as pd
import statsmodels.api as sm
from plotly.offline import init_notebook_mode,iplot
import plotly.graph_objs as go #something like javaScript can be used to page interaction.better than matplotlib
init_notebook_mode(connected=False) #offline model may be better,for connected = true can result in image can't be showed
data = pd.read_csv('I:/ITLearningMaterials/TYD/MathematicalFoundation/统计分析/回归分析/weight.csv')
data = data[data.height>120] # there can't someone's height below 120cm
trace = go.Scatter(x=data.height,y=data.weight,mode='markers')
layout = go.Layout(
width=900,
height=500,
xaxis=dict(title='Height',titlefont=dict(family='Consolas,monospace',size=15)),
yaxis=dict(title='Weight',titlefont=dict(family='Consolas,monospace',size=15))
)
data2 = [trace] #加这个方框是什么意思,变成数组形式吗?
fig = go.Figure(data=data2,layout=layout)
iplot(fig)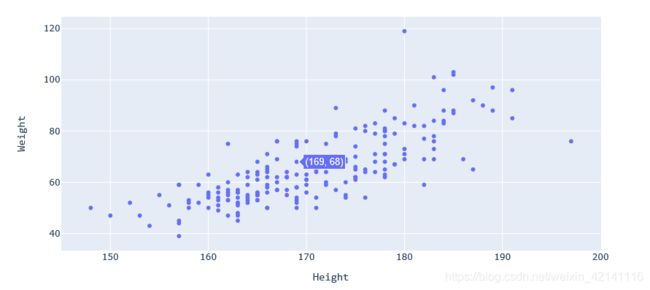
开始回归分析
X = data.height
y = data.weight
X = sm.add_constant(X)
model = sm.OLS(y,X).fit()
model.summary()
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
ax.plot(data.height,y,'o',label="data")
ax.plot(data.height,model.fittedvalues,'r--.',label='OLS')
ax.legend(loc='best')
plt.show()
