spark 骚操作实现高效处理kafka数据积压
一、 开篇
spark streaming消费kafka,大家都知道有两种方式,也是面试考基本功常问的:
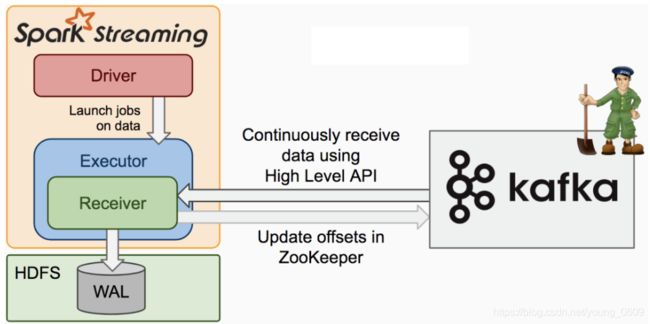
1.基于receiver的机制。
这个是spark streaming最基本的方式,spark streaming的receiver会定时生成block,默认是200ms,然后每个批次生成blockrdd,分区数就是block数。架构如下:
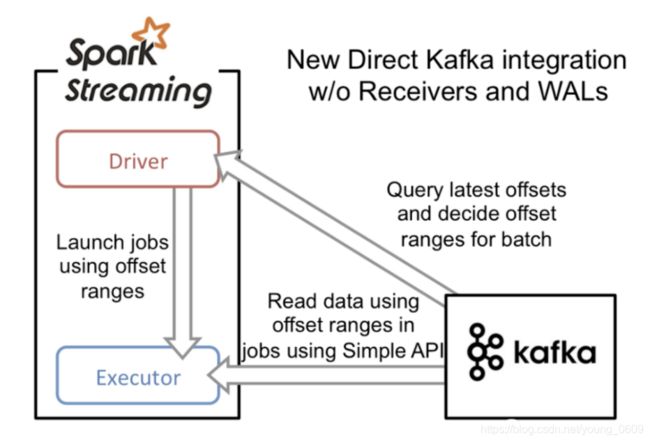
2.direct API。
这种api就是spark streaming会每个批次生成一个kafkardd,然后kafkardd的分区数,由spark streaming消费的kafkatopic分区数决定。过程如下:
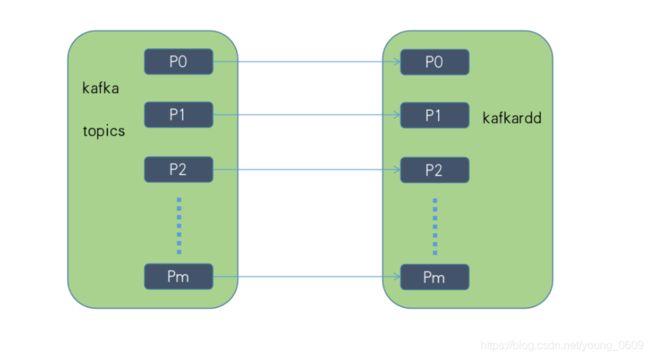
kafkardd与消费的kafka分区数的关系如下:
二.常见积压问题
kafka的producer生产数据到kafka,正常情况下,企业中应该是轮询或者随机,以保证kafka分区之间数据是均衡的。
在这个前提之下,一般情况下,假如针对你的数据量,kafka分区数设计合理。实时任务,如spark streaming或者flink,有没有长时间的停掉,那么一般不会有有积压。
消息积压的场景:
a.任务挂掉。比如,周五任务挂了,有没有写自动拉起脚本,周一早上才处理。那么spark streaming消费的数据相当于滞后两天。这个确实新手会遇到。
b.kafka分区数设少了。其实,kafka单分区生产消息的速度qps还是很高的,但是消费者由于业务逻辑复杂度的不同,会有不同的时间消耗,就会出现消费滞后的情况。
c.kafka消息的key不均匀,导致分区间数据不均衡。kafka生产消息支持指定key,用key携带写信息,但是key要均匀,否则会出现kafka的分区间数据不均衡。
上面三种积压情况,企业中很常见,那么如何处理数据积压呢?
一般解决办法,针对性的有以下几种:
a.任务挂掉导致的消费滞后。
任务启动从最新的消费,历史数据采用离线修补。
最重要的是故障拉起脚本要有,还要就是实时框架异常处理能力要强,避免数据不规范导致的不能拉起。
b.任务挂掉导致的消费滞后。
任务启动从上次提交处消费处理,但是要增加任务的处理能力,比如增加资源,让任务能尽可能的赶上消费最新数据。
c.kafka分区少了。
假设数据量大,直接增加kafka分区是根本,但是也可以对kafkardd进行repartition,增加一次shuffle。
d.个别分区不均衡。
可以生产者处可以给key加随机后缀,使其均衡。也可以对kafkardd进行repartition。
三、骚操作
其实,以上都不是大家想要的,因为spark streaming生产的kafkardd的分区数,完全可以是大于kakfa分区数的。
其实,经常阅读源码的朋友应该了解,rdd的分区数,是由rdd的getPartitions函数决定。比如kafkardd的getPartitions方法实现如下:
override def getPartitions: Array[Partition] = {offsetRanges.zipWithIndex.map { case (o, i) =>new KafkaRDDPartition(i, o.topic, o.partition, o.fromOffset, o.untilOffset)}.toArray}
offsetRanges其实就是一个数组:
val offsetRanges: Array[OffsetRange],OffsetRange存储一个kafka分区元数据及其offset范围,然后进行map操作,转化为KafkaRDDPartition。实际上,我们可以在这里下手,将map改为flatmap,然后对offsetrange的范围进行拆分,但是这个会引发一个问题,浪尖在这里就不赘述了,你可以测测。
其实,我们可以在offsetRange生成的时候做下转换。位置是DirectKafkaInputDstream的compute方法。具体实现:
首先,浪尖实现中增加了三个配置,分别是:
是否开启自动重分区分区sparkConf.set("enable.auto.repartition","true")避免不必要的重分区操作,增加个阈值,只有该批次要消费的kafka的分区内数据大于该阈值才进行拆分sparkConf.set("per.partition.offsetrange.threshold","300")拆分后,每个kafkardd 的分区数据量。sparkConf.set("per.partition.after.partition.size","100")
然后,在DirectKafkaInputDstream里获取着三个配置,方法如下:
val repartitionStep = _ssc.conf.getInt("per.partition.offsetrange.size",1000)val repartitionThreshold = _ssc.conf.getLong("per.partition.offsetrange.threshold",1000)val enableRepartition = _ssc.conf.getBoolean("enable.auto.repartition",false)
对offsetRanges生成的过程进行改造,只需要增加7行源码即可。
val offsetRanges = untilOffsets.flatMap{ case (tp, uo) =>
val fo = currentOffsets(tp)
val delta = uo -fo
if(enableRepartition&&(repartitionThreshold < delta)){
val offsets = fo to uo by repartitionStep
offsets.map(each =>{
val tmpOffset = each + repartitionStep
OffsetRange(tp.topic, tp.partition, each, Math.min(tmpOffset,uo))
}).toList
}else{
Array(OffsetRange(tp.topic, tp.partition, fo, uo))
}
}
测试的主函数如下:
import bigdata.spark.config.Config
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
1. 直接消费新数据,数据离线修补。
2. repartition(10---->100),给足够多的资源,以便任务逐渐消除滞后的数据。
3. directDstream api 生成的是kafkardd,该rdd与kafka分区一一对应。
*/
object kafka010Repartition {
def main(args: Array[String]) {
// 创建一个批处理时间是2s的context 要增加环境变量
val sparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")
sparkConf.set("enable.auto.repartition","true")
sparkConf.set("per.partition.offsetrange.threshold","300")
sparkConf.set("per.partition.offsetrange.step","100")
val ssc = new StreamingContext(sparkConf, Seconds(5))
// 使用broker和topic创建DirectStream
val topicsSet = "test1".split(",").toSet
val kafkaParams = Map[String, Object]("bootstrap.servers" -> Config.kafkaHost,
"key.deserializer"->classOf[StringDeserializer],
"value.deserializer"-> classOf[StringDeserializer],
"group.id"->"test1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit"->(false: java.lang.Boolean))
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
messages.transform(rdd=>{
println("partition.size : "+rdd.getNumPartitions)
rdd
}).foreachRDD(rdd=>{
// rdd.foreachPartition(each=>println(111))
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach(o=>{
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
})
})
ssc.start()
ssc.awaitTermination()
}
}结果如下:
partition.size : 67
test1 0 447 547
test1 0 547 647
test1 0 647 747
test1 0 747 847
test1 0 847 947
test1 0 947 1047
test1 0 1047 1147
test1 0 1147 1247
test1 0 1247 1347
test1 0 1347 1447
test1 0 1447 1547
test1 0 1547 1647
test1 0 1647 1747
test1 0 1747 1847
test1 0 1847 1947
test1 0 1947 2047
test1 0 2047 2147
test1 0 2147 2247
test1 0 2247 2347
test1 0 2347 2447
test1 0 2447 2547
test1 0 2547 2647
test1 0 2647 2747
test1 0 2747 2847
test1 0 2847 2947
test1 0 2947 3047
test1 0 3047 3147
test1 0 3147 3247
test1 0 3247 3347