x264源码分析与应用示例(一)——视频编码基本流程
打算写几篇文章记录一下学习x264源码的成果,主要包含两个方面的内容,一是基本的x264视频编码流程,二是x264中的码率控制,之前分析过JM和HM的码率控制,但是x264的码率控制一直没看,这回也算是补上了。然后再以两个实际问题为例介绍通过研究源码后给出的解决方案,一个是如何修改编码参数获得更好的视频质量的问题,一个是修改源码改进x264码率控制算法的问题。
本文包含以下内容
1、H.264编码流程详述与对应x264源码解析
首先简单介绍一下x264源码调试与修改的基本方法。就是基本的conifigure和make,configure命令使用最简单的就可以,需要注意的是要--enable-debug,如果是windows的话,需要mingw。然后打开eclipse+cdt,选File->new->Makefile Project with Existing Code,接下来的对话框中的Toolchain for Indexer Settings中选Linux GCC,完成项目的新建之后右键点击x264选debug即可开始调试。如果进行修改的话,在每次修改了源码之后重新进行make即可。
H.264编码流程详述与对应x264源码解析
这里的分析基于x264-146。先给出一个标准的H.264编码流程图,如下
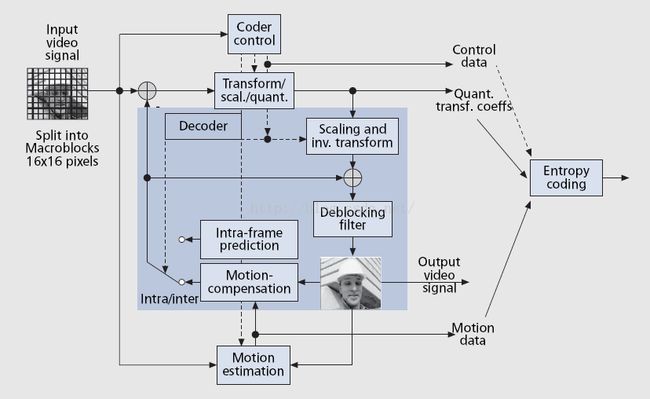
由图中可以看出一个编码流程的关键步骤有变换、量化、预测、滤波、熵编码、码率控制。下面跟着代码走一遍流程。以下面的编码命令作为测试
--threads 1 --no-cabac --vbv-bufsize 400 --vbv-maxrate 200 --bitrate 200 --input-res 176x144 -o test.264 testqcif.yuv
命令行解析 x264.c-parse()
调用了如下几个关键的函数
1、x264_param_default():给各个参数设置默认值
2、x264_param_default_preset():设置默认的preset,内部调用了x264_param_apply_preset()和x264_param_apply_tune(),在它们之中即可找到各个preset和tune的详细参数区别,例如ultrafast这个preset就是在默认值得基础上做了如下改动
if( !strcasecmp( preset, "ultrafast" ) )
{
param->i_frame_reference = 1;
param->i_scenecut_threshold = 0;
param->b_deblocking_filter = 0;//不使用去块滤波
param->b_cabac = 0;//不使用CABAC
param->i_bframe = 0;//不使用B帧
param->analyse.intra = 0;
param->analyse.inter = 0;
param->analyse.b_transform_8x8 = 0;//不使用8x8DCT
param->analyse.i_me_method = X264_ME_DIA;//运动搜索方法使用“Diamond”
param->analyse.i_subpel_refine = 0;
param->rc.i_aq_mode = 0;
param->analyse.b_mixed_references = 0;
param->analyse.i_trellis = 0;
param->i_bframe_adaptive = X264_B_ADAPT_NONE;
param->rc.b_mb_tree = 0;
param->analyse.i_weighted_pred = X264_WEIGHTP_NONE;//不使用加权
param->analyse.b_weighted_bipred = 0;
param->rc.i_lookahead = 0;
}
与此类似的还有x264_param_apply_profile(),是根据不同profile的设置修改对应的参数
3、x264_param_parse():对命令行参数进行解析,并进行对应的赋值,实质上就是用过strcmp()的方法,赋值的对象正是关键结构体x264_param_t。比如我们在前面设置了--vbv-bufsize 400,对应的代码就是
OPT("vbv-bufsize")
p->rc.i_vbv_buffer_size = atoi(value);4、select_output(),select_input():这两个函数都是根据命令行中输入输出文件名的后缀来判断类型,从而可以在后续工作中调用对应的读写操作,这样的做法在ffmpeg中也有类似的实现。比如,如果通过后缀判断出输入文件是raw格式的,就会有如下的操作
else if( !strcasecmp( module, "raw" ) || !strcasecmp( ext, "yuv" ) )
cli_input = raw_input;这里的cli_input定义如下,可以看到就是一个文件i/o操作相关的结构体
typedef struct
{
int (*open_file)( char *psz_filename, hnd_t *p_handle, video_info_t *info, cli_input_opt_t *opt );
int (*picture_alloc)( cli_pic_t *pic, int csp, int width, int height );
int (*read_frame)( cli_pic_t *pic, hnd_t handle, int i_frame );
int (*release_frame)( cli_pic_t *pic, hnd_t handle );
void (*picture_clean)( cli_pic_t *pic );
int (*close_file)( hnd_t handle );
} cli_input_t;而raw_input的定义就在raw.c中,里面定义了针对raw格式的I/O操作,以打开文件为例
static int open_file( char *psz_filename, hnd_t *p_handle, video_info_t *info, cli_input_opt_t *opt )
{
raw_hnd_t *h = calloc( 1, sizeof(raw_hnd_t) );
if( !h )
return -1;
if( !opt->resolution )
{
/* try to parse the file name */
for( char *p = psz_filename; *p; p++ )
if( *p >= '0' && *p <= '9' && sscanf( p, "%dx%d", &info->width, &info->height ) == 2 )
break;
}
else
sscanf( opt->resolution, "%dx%d", &info->width, &info->height );
FAIL_IF_ERROR( !info->width || !info->height, "raw input requires a resolution.\n" )
if( opt->colorspace )
{
for( info->csp = X264_CSP_CLI_MAX-1; info->csp > X264_CSP_NONE; info->csp-- )
{
if( x264_cli_csps[info->csp].name && !strcasecmp( x264_cli_csps[info->csp].name, opt->colorspace ) )
break;
}
FAIL_IF_ERROR( info->csp == X264_CSP_NONE, "unsupported colorspace `%s'\n", opt->colorspace );
}
else /* default */
info->csp = X264_CSP_I420;
h->bit_depth = opt->bit_depth;
FAIL_IF_ERROR( h->bit_depth < 8 || h->bit_depth > 16, "unsupported bit depth `%d'\n", h->bit_depth );
if( h->bit_depth > 8 )
info->csp |= X264_CSP_HIGH_DEPTH;
if( !strcmp( psz_filename, "-" ) )
h->fh = stdin;
else
h->fh = x264_fopen( psz_filename, "rb" );
if( h->fh == NULL )
return -1;
info->thread_safe = 1;
info->num_frames = 0;
info->vfr = 0;
const x264_cli_csp_t *csp = x264_cli_get_csp( info->csp );
for( int i = 0; i < csp->planes; i++ )
{
h->plane_size[i] = x264_cli_pic_plane_size( info->csp, info->width, info->height, i );
h->frame_size += h->plane_size[i];
/* x264_cli_pic_plane_size returns the size in bytes, we need the value in pixels from here on */
h->plane_size[i] /= x264_cli_csp_depth_factor( info->csp );
}
if( x264_is_regular_file( h->fh ) )
{
fseek( h->fh, 0, SEEK_END );
uint64_t size = ftell( h->fh );
fseek( h->fh, 0, SEEK_SET );
info->num_frames = size / h->frame_size;
}
*p_handle = h;
return 0;
}
此外还有一个cli_vid_filter_t,是输入格式滤镜结构体,可以对输入数据做一些简单的处理,例如拉伸(需要libswscale的支持)、裁剪等等(当然滤镜也可以不作任何处理,直接读取输入数据)。在x264的编码过程中,就是调用cli_vid_filter_t结构体的get_frame()读取YUV数据,调用cli_output_t的write_frame()写入数据。
整个parse()的内容都可以归结为是在给x264_param_t结构体赋值,先赋值为默认值,再根据命令做相应的修改,最后再解析一下输入输出的文件格式。
编码主流程 x264.c——encode()
依次调用了如下几个关键函数
1、x264_encoder_open():打开编码器,初始化编码需要的各种变量,各种赋值。包括
(1)根据输入参数x264_param_t 生成码流的SPS、PPS信息,各种赋值,参见H.264标准即可——x264_sps_init() x264_pps_init()
(2)初始化帧内预测的C语言版本或汇编优化过的函数。H.264中有两种帧内预测模式:16x16亮度帧内预测模式和4x4亮度帧内预测模式。其中16x16帧内预测模式一共有4种(Vertical,Horizontal,DC,Plane),4x4帧内预测模式一共有9种,简单记为249—— x264_predict_16x16_init() x264_predict_4x4_init()
(3)初始化像素值计算相关的汇编函数,包括SAD(绝对误差和)、SATD(hadamard变换后的绝对误差和)、SSD(差值平方和),都是主要用于帧内预测模式以及帧间预测模式的判断,即将一个宏块的所有预测模式都走一遍,分别计算预测值和原始值之间的差距,选择差距小的那种预测模式。早期的编码器使用SAD进行计算,近期的编码器多使用SATD进行计算。为什么使用SATD而不使用SAD呢?关键原因在于编码之后码流的大小是和图像块DCT变换后频域信息紧密相关的,而和变换前的时域信息关联性小一些。SAD只能反应时域信息;SATD却可以反映频域信息,而且计算复杂度也低于DCT变换,因此是比较合适的模式选择的依据。对应的结构体是x264_pixel_function_t,所谓的初始化就是给这个结构体中的函数接口赋值——x264_pixel_init()
(4)初始化DCT变换和反变换相关的C语言版本或汇编优化过的函数,DCT变换都是针对残差进行的,早期的DCT变换都使用了8x8的矩阵(变换系数为小数)。在H.264标准中新提出了一种4x4的矩阵。这种4x4 DCT变换的系数都是整数,一方面提高了运算的准确性,一方面也利于代码的优化。对应的结构体是x264_dct_function_t,所谓的初始化就是给这个结构体中的函数接口赋值—— x264_dct_init()
(5)初始化运动估计、运动补偿、半像素内插相关的C语言版本或汇编优化过的函数。对应的结构体是x264_mc_functions_t,所谓的初始化就是给这个结构体中的函数接口赋值——x264_mc_init()
(6)初始化量化和反量化相关的C语言版本或汇编优化过的函数,我们平时说的QP其实只是量化步长qstep的序号,qstep共有52个值,QP每增加6,qstep增加一倍,量化公式中的分母也是qstep,所以QP越大,量化越不精细,图像质量受损越严重。量化是对DCT残差矩阵进行的,比如,如果是对4x4的DCT残差矩阵进行量化的话,就是对16个DCT系数依次使用量化公式。对应的结构体是x264_quant_function_t,所谓的初始化就是给这个结构体中的函数接口赋值——x264_quant_init()
(7)初始化去块效应滤波器相关的C语言版本或汇编优化过的函数,块效应主要由DCT变换后的量化误差导致,环路滤波有两种强度,普通强度针对方块边界周围的6个点,强滤波器则针对8个点,通常帧内预测相关的图像块使用腔滤波器,而帧间预测使用普通滤波器,此外也需要边界两边的两个点的像素值差距达到一定值才会进行环路滤波。对应的结构体是x264_deblock_function_t,所谓的初始化就是给这个结构体中的函数接口赋值——x264_deblock_init()
(8)初始化Lookahead相关的变量 x264_lookahead_init()
(9)初始化码率控制相关的变量,在下一篇文章中详细分析。x264_ratecontrol_new()
2、x264_encoder_headers():分别调用了x264_sps_write(),x264_pps_write(),x264_sei_version_write()输出了SPS,PPS,和SEI(附加信息,就是平时在mediainfo里面看懂的编码设置信息)信息,不同于前面的x264_sps_init()等,这里的write就是直接以熵编码的形式写到码流中了
3、encode_frame():编码一帧YUV数据,循环运行。内部调用x264_encoder_encode()(在下一小节详细分析)编码x264_picture_t为x264_nal_t,调用cli_output.write_frame()输出码流。如下
//编码1帧
static int encode_frame( x264_t *h, hnd_t hout, x264_picture_t *pic, int64_t *last_dts )
{
x264_picture_t pic_out;
x264_nal_t *nal;
int i_nal;
int i_frame_size = 0;
//编码API
//编码x264_picture_t为x264_nal_t
i_frame_size = x264_encoder_encode( h, &nal, &i_nal, pic, &pic_out );
FAIL_IF_ERROR( i_frame_size < 0, "x264_encoder_encode failed\n" );
if( i_frame_size )
{
//通过cli_output_t中的方法输出
//输出raw H.264流的话,等同于直接fwrite()
//其他封装格式,则还需进行一定的封装
i_frame_size = cli_output.write_frame( hout, nal[0].p_payload, i_frame_size, &pic_out );
*last_dts = pic_out.i_dts;
}
return i_frame_size;
}
4、print_status():输出编码状态,就是我们在命令行中看到的那些,如
[7.7%] 1/13 frames, 0.02 fps, 1133.40 kb/s, eta 0:13:07需要注意的是这里的fps,代表的是编码速度
5、x264_encoder_close():关闭编码器,输出统计信息,就是在命令行窗口中最后看到的那一大串信息(不包括前面print_status()输出的内容)
x264_encoder_encode
来详细看看编码的核心函数x264_encoder_encode(),其中依次调用了如下几个函数,这些关键步骤在源码中也给出了一些注释
1、获取一个空的x264_frame_t用于存储编码数据,即fenc,同时进行了初始化——x264_frame_pop_unused
2、将外部结构体的pic_in(x264_picture_t类型)的数据拷贝给内部结构体的fenc——x264_frame_copy_picture
3、将fenc放入Lookahead模块的队列中,等待确定帧类型——x264_lookahead_put_frame
4、分析Lookahead模块中一个帧的帧类型,内部调用的是x264_slicetype_decide来确定帧类型,x264_slicetype_decide又调用了x264_slicetype_analyse。判断帧类型的逻辑如下,如果通过scenecut()判断为场景切换,就设置为I帧;如果不适用B帧,就将所有帧设置为P帧;如果使用B帧,就计算开销(使用哪种帧带来的误差satd小,在1/2分辨率下计算),判断是否B帧,分析后的帧保存在frames.current[]中。——x264_lookahead_get_frames
5、从frames.current[]中取出分析帧类型之后的fenc——x264_frame_shift
6、更新参考帧队列frames.reference[]——x264_reference_update
7、如果编码帧fenc是IDR帧,清空参考帧队列frames.reference[]——x264_reference_reset
8、创建参考帧列表List0和List1——x264_reference_build_list
关于参考帧这部分内容我一直还不是很清楚,留待以后研究
9、码率控制单元初始化——x264_ratecontrol_start,在下一篇文章详细分析
10、初始化Slice Header信息——x264_slice_init,内部调用x264_slice_header_init
11、进行编码——x264_slices_write,循环一副图像中的每一个slice进行编码,调用x264_slice_write(没有s,在下一小节详细分析),编码流程图中的各个模块就在这个函数中依次展开了
12、做一些编码后的后续处理,记录统计信息,输出nalu(例如添加起始码),输出重建帧,还调用了x264_ratecontrol_end结束码率控制,需要说明的是H.264码流有两种格式:
(1)annexb模式(传统模式)。这种模式下每个NALU包含起始码0x00000001;而且SPS、PPS存储在ES码流中。常见的H.264裸流就是属于这种格式。
(2)mp4模式。这种模式下每个NALU不包含起始码,原本存储起始码前4个字节存储的是这个NALU的长度(不包含前4字节);而且SPS、PPS被单独放在容器的其他位置上。这种H.264一般存储在某些容器中,例如MP4中。
从源代码中可以看出,x264_nal_encode()根据H.264码流格式的不同分成两种情况给NALU添加起始码:
(1)annexb模式下,在每个NALU前面添加0x00000001。
(2)mp4模式下,先计算NALU的长度(不包含前4字节),再将长度信息写入NALU前面的4个字节——x264_encoder_frame_end
x264_slice_write
前面说了这么多,都没看到前面编码流程图里面的内容,别着急,这就来了,都在x264_slice_write中。它依次包含了以下内容
1、开始写一个NALU——x264_nal_start
2、初始化宏块重建数据缓存fdec_buf[](在像素块的左边和上边包含了左上方相邻块用于预测的像素)和编码数据缓存fenc_buf[](YUV像素挨着存放,比较简单)——x264_macroblock_thread_init
3、输出 Slice Header,不同于前面的x264_slice_init,这里直接就是通过熵编码写入码流了——x264_slice_header_write
4、滤波模块。环路滤波,半像素插值,SSIM/PSNR的计算——x264_fdec_filter_row,内部又调用了如下几个函数
(4.1)去块效应滤波——x264_frame_deblock_row。一次处理一行。
(4.2)半像素插值——x264_frame_filter。
(4.3)PSNR计算——x264_pixel_ssd_wxh。在需要计算编码质量的时候,下同。这里是先计算SSD,最后输出的时候再用x264_psnr将SSD换算为PSNR,公式如下
MSE=SSD*1/(w*h) PSNR=10*log10(MAX^2/MSE)
(4.4)SSIM计算——x264_pixel_ssim_wxh。
5、将要编码的宏块的周围的宏块的信息读进来——x264_macroblock_cache_load
6、分析模块。帧内预测模式分析以及帧间运动估计等,帧内预测的内容前面有讲过,而对于帧间运动估计,不仅仅只可以选择一个图像作为参考帧(P帧),而且还可以选择两张图片作为参考帧(B帧)。使用一张图像作为参考帧称为单向预测,而使用一张图像作为参考帧称为双向预测。使用单向预测的时候,直接将参考帧上的匹配块的数据“搬移下来”作后续的处理(“赋值”),而使用双向预测的时候,需要首先将两个参考帧上的匹配块的数据求平均值(“求平均”),然后再做后续处理。毫无疑问双向预测可以得到更好的压缩效果,但是也会使码流变得复杂一些。总体来说就是把各种模式都遍历一遍,选择SAD或者SATD最小的那一种,因为可以认为误差越小,消耗的比特越少,编码代价越小。帧间宏块的划分方式总共有8种。运动搜索主要有菱形搜索算法DIA、六边形搜索算法HEX——x264_macroblock_analyse
7、宏块编码模块。对残差DCT变换、量化等方式对宏块进行编码,反变换反量化用于重建帧的内容也在这里,宏块编码部分的DCT残差反变换,并且叠加到预测数据上,形成重建帧是用来干什么的?重建帧有时会用来输出,并且后面几帧的预测是基于重建帧而非原始待编码帧的数据——x264_macroblock_encode
8、熵编码,熵编码的内容包括Qp(存储的是QP偏移值,即上一个宏块和当前宏块之间的差值)、残差数据、IPB各个slice的header数据,包括预测模式,运动矢量差值(MV-预测MV,预测MV由周围宏块的MV取中值的来,而不是直接储存运动矢量),参考帧序号等等——x264_macroblock_write_cabac,x264_macroblock_write_cavlc
9、保存当前宏块的信息,包括帧内预测模式,DCT非零系数,运动矢量,参考帧序号等等,用于以后的宏块的编码——x264_macroblock_cache_save
10、码率控制——x264_ratecontrol_mb,在下一篇文章中会详细分析
11、结束写一个NALU——x264_nal_end
关注公众号,掌握更多多媒体领域知识与资讯

文章帮到你了?可以扫描如下二维码进行打赏~,打赏多少您随意~
